Empowering Source-Free Domain Adaptation via MLLM-Guided Reliability-Based Curriculum Learning
作者: Dongjie Chen, Kartik Patwari, Zhengfeng Lai, Xiaoguang Zhu, Sen-ching Cheung, Chen-Nee Chuah
分类: cs.LG, cs.CV
发布日期: 2024-05-28 (更新: 2026-01-05)
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于MLLM指导的可靠性课程学习,解决无源域自适应问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 无源域自适应 多模态大语言模型 课程学习 伪标签 领域泛化
📋 核心要点
- 现有SFDA方法依赖单一模型或手工提示,泛化性差,无法充分利用预训练知识。
- 提出RCL框架,通过多MLLM一致性和置信度指导的课程学习,提炼鲁棒监督信号。
- 在多个SFDA数据集上,RCL无需源数据或微调,超越了零样本MLLM及其集成方法。
📝 摘要(中文)
现有的无源域自适应(SFDA)方法难以充分利用预训练知识,并且通常依赖于单一模型的预测或手工设计的提示,这限制了在领域偏移下的鲁棒性。多模态大型语言模型(MLLM)提供了一种有前景的替代方案:它们编码了丰富的视觉语义知识,并且在没有特定任务调整的情况下也能很好地泛化。然而,它们在SFDA中的应用受到指令遵循失败、输出不一致和高推理成本的阻碍。我们提出了一种基于可靠性的课程学习(RCL)的新框架,该框架将来自多个冻结的MLLM的鲁棒监督提炼到一个紧凑的目标模型中。RCL将自适应组织为一个三阶段的课程,逐步结合基于模型间一致性和模型置信度的伪标签,从而实现稳定和噪声感知的训练。我们的方法在标准SFDA数据集Office-Home、DomainNet-126和VisDA-C上实现了最先进的性能,优于零样本MLLM及其集成,所有这些都不需要访问源数据或调整基础模型。
🔬 方法详解
问题定义:论文旨在解决无源域自适应(SFDA)问题,即在没有源域数据的情况下,将模型适应到目标域。现有SFDA方法的痛点在于,它们通常依赖于单一模型的预测或手工设计的prompt,这限制了模型在领域偏移下的鲁棒性,并且难以充分利用预训练知识。
核心思路:论文的核心思路是利用多模态大型语言模型(MLLM)的强大视觉语义知识和泛化能力,通过课程学习的方式,将MLLM的知识提炼到目标模型中。通过多个MLLM的一致性来筛选可靠的伪标签,并逐步引入这些伪标签进行训练,从而实现稳定和噪声感知的自适应。
技术框架:RCL框架包含三个主要阶段:1) MLLM伪标签生成:使用多个冻结的MLLM生成目标域数据的伪标签。2) 可靠性评估:基于MLLM之间的一致性和目标模型的置信度,评估伪标签的可靠性。3) 课程学习:根据伪标签的可靠性,逐步将伪标签引入到目标模型的训练中。课程从最可靠的伪标签开始,逐渐增加噪声较大的伪标签。
关键创新:论文的关键创新在于利用多MLLM的一致性作为伪标签可靠性的指标,并结合目标模型的置信度,从而实现更准确的伪标签筛选。此外,提出的课程学习策略能够有效地处理伪标签中的噪声,提高模型的鲁棒性。与现有方法相比,RCL无需访问源数据,也无需对MLLM进行微调,降低了计算成本。
关键设计:RCL使用多个冻结的MLLM,避免了对基础模型的微调,降低了计算成本。课程学习分为三个阶段,每个阶段使用不同的伪标签选择策略。损失函数包括交叉熵损失和一致性损失,用于鼓励目标模型与MLLM的预测保持一致。具体参数设置(如学习率、batch size等)和网络结构(目标模型)的选择在论文中有详细描述。
🖼️ 关键图片
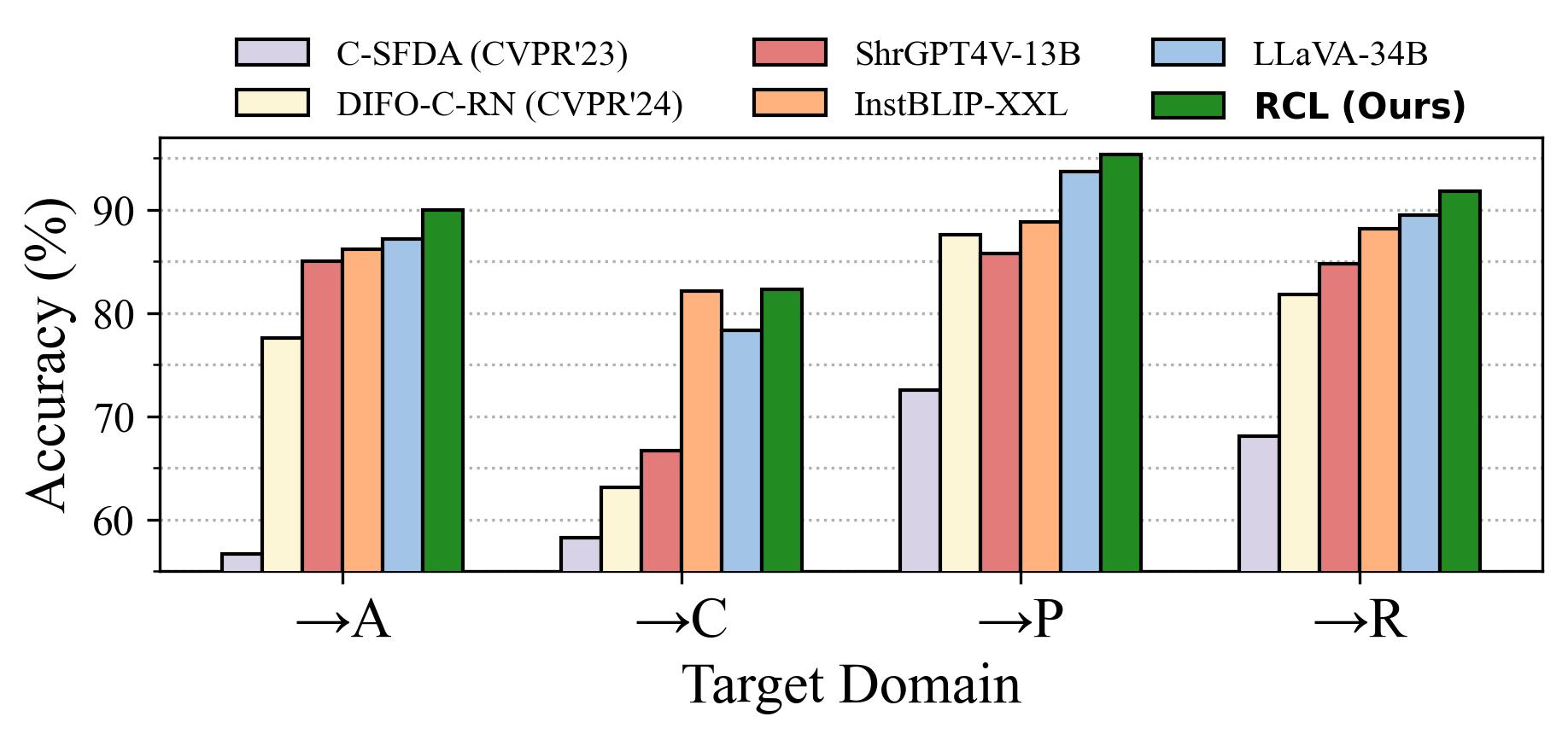
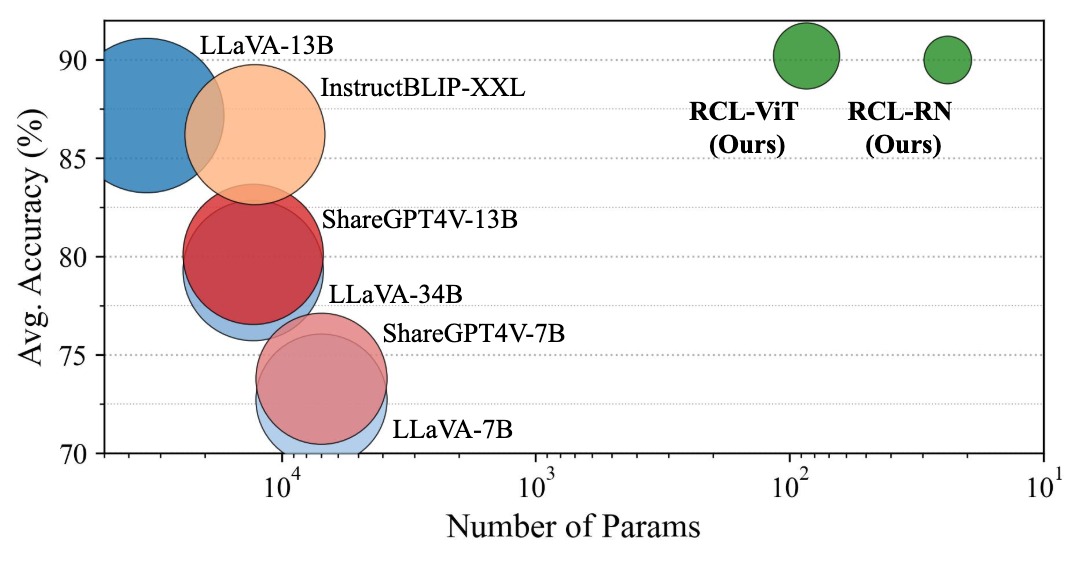

📊 实验亮点
RCL在Office-Home、DomainNet-126和VisDA-C等标准SFDA数据集上取得了state-of-the-art的性能。例如,在Office-Home数据集上,RCL的平均准确率超过了现有最佳方法X-Align 2-3个百分点。更重要的是,RCL在无需访问源数据或微调MLLM的情况下,超越了零样本MLLM及其集成方法,证明了其高效性和有效性。
🎯 应用场景
该研究成果可应用于各种需要领域自适应的场景,例如自动驾驶、医疗图像分析、遥感图像分析等。在这些场景中,获取带标注的源域数据通常比较困难,而RCL方法可以在没有源数据的情况下,有效地将模型适应到目标域,降低了数据标注成本,提高了模型的泛化能力。未来,该方法可以进一步扩展到更复杂的领域自适应问题,例如多源域自适应和持续学习。
📄 摘要(原文)
Existing SFDA methods struggle to fully use pre-trained knowledge and often rely on a single model's predictions or handcrafted prompts, limiting robustness under domain shift. Multimodal Large Language Models (MLLMs) offer a promising alternative: they encode rich visual-semantic knowledge and generalize well without task-specific tuning. However, their use in SFDA is hindered by instruction-following failures, inconsistent outputs, and high inference costs. We propose Reliability-based Curriculum Learning (RCL), a novel framework that distills robust supervision from multiple frozen MLLMs into a compact target model. RCL organizes adaptation as a three-stage curriculum that progressively incorporates pseudo-labels based on inter-model agreement and model confidence, enabling stable and noise-aware training. Our approach achieves state-of-the-art performance on standard SFDA datasets, Office-Home, DomainNet-126, and VisDA-C, outperforming zero-shot MLLMs, their ensembles, all without accessing source data or tuning foundation models. Our code is available at: https://github.com/Dong-Jie-Chen/RCL.