Individual Contributions as Intrinsic Exploration Scaffolds for Multi-agent Reinforcement Learning
作者: Xinran Li, Zifan Liu, Shibo Chen, Jun Zhang
分类: cs.LG, cs.AI, cs.MA
发布日期: 2024-05-28
备注: Accepted by the Forty-first International Conference on Machine Learning
🔗 代码/项目: GITHUB
💡 一句话要点
提出ICES,利用个体贡献作为内在探索支架,解决MARL中的稀疏奖励探索问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 内在奖励 探索策略 信用分配 贝叶斯惊奇 稀疏奖励 个体贡献
📋 核心要点
- MARL在稀疏奖励环境中面临探索难题,全局内在奖励虽能促进探索,但信用分配复杂。
- ICES通过评估个体智能体对全局状态转换的贡献来构建探索支架,引导智能体探索。
- ICES分离探索和利用策略,利用全局信息进行训练,在GRF和SMAC等任务上表现优异。
📝 摘要(中文)
在多智能体强化学习(MARL)中,有效的探索至关重要,尤其是在稀疏奖励环境中。虽然引入全局内在奖励可以在这种环境中促进探索,但它通常会使智能体之间的信用分配变得复杂。为了解决这个问题,我们提出了一种新颖的方法,即个体贡献作为内在探索支架(ICES),通过评估每个智能体从全局角度的贡献来激励探索。特别是,ICES利用贝叶斯惊奇构建探索支架,利用集中训练期间的全局转换信息。这些支架仅在训练中使用,有助于引导个体智能体采取对全局潜在状态转换产生重大影响的行动。此外,ICES将探索策略与利用策略分开,使前者能够在训练期间利用特权全局信息。在具有稀疏奖励的合作基准任务(包括Google Research Football (GRF)和StarCraft Multi-agent Challenge (SMAC))上的大量实验表明,与基线相比,ICES表现出卓越的探索能力。代码已在https://github.com/LXXXXR/ICES上公开发布。
🔬 方法详解
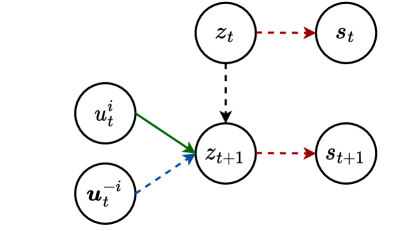
问题定义:在多智能体强化学习(MARL)中,尤其是在稀疏奖励环境中,如何有效地进行探索是一个关键问题。现有的方法,例如直接引入全局内在奖励,虽然可以促进探索,但往往会使得智能体之间的信用分配变得非常困难,难以确定每个智能体对整体奖励的贡献。
核心思路:论文的核心思路是利用个体智能体对全局状态转换的贡献程度来作为内在的探索激励。通过评估每个智能体从全局角度出发对环境产生的影响,从而引导智能体探索那些能够显著改变环境状态的行为。这种方法旨在解决稀疏奖励环境下的探索问题,并简化信用分配。
技术框架:ICES的技术框架主要包含以下几个阶段:1) 集中式训练:利用全局状态信息进行训练,评估每个智能体的贡献。2) 贝叶斯惊奇度计算:使用贝叶斯惊奇度来量化全局状态转换的显著性。3) 探索支架构建:基于贝叶斯惊奇度构建探索支架,为每个智能体提供内在奖励。4) 策略分离:将探索策略和利用策略分离,探索策略利用全局信息,而利用策略则基于个体观测。
关键创新:ICES的关键创新在于使用个体贡献作为内在探索的支架。与传统的全局内在奖励方法不同,ICES关注的是个体智能体对全局状态转换的影响,从而更精确地指导探索。此外,分离探索和利用策略,允许探索策略利用特权信息,进一步提升了探索效率。
关键设计:ICES的关键设计包括:1) 贝叶斯惊奇度计算:使用贝叶斯模型来估计状态转换的概率,并利用KL散度来衡量新状态与先前状态的差异,从而量化惊奇度。2) 探索奖励函数:基于贝叶斯惊奇度构建探索奖励函数,奖励那些能够显著改变全局状态的智能体。3) 策略网络结构:采用Actor-Critic结构,并为探索和利用分别设计独立的策略网络。
🖼️ 关键图片


📊 实验亮点
ICES在Google Research Football (GRF)和StarCraft Multi-agent Challenge (SMAC)等稀疏奖励的合作基准任务上进行了广泛的实验,结果表明ICES显著优于基线方法,展现出更强的探索能力。具体性能提升数据需要在论文中进一步查找。
🎯 应用场景
该研究成果可应用于需要多智能体协作且奖励稀疏的复杂环境,例如机器人协同操作、自动驾驶车辆编队、以及资源分配和调度等领域。通过提升智能体的探索能力,可以更有效地解决实际问题,并推动多智能体强化学习在现实世界中的应用。
📄 摘要(原文)
In multi-agent reinforcement learning (MARL), effective exploration is critical, especially in sparse reward environments. Although introducing global intrinsic rewards can foster exploration in such settings, it often complicates credit assignment among agents. To address this difficulty, we propose Individual Contributions as intrinsic Exploration Scaffolds (ICES), a novel approach to motivate exploration by assessing each agent's contribution from a global view. In particular, ICES constructs exploration scaffolds with Bayesian surprise, leveraging global transition information during centralized training. These scaffolds, used only in training, help to guide individual agents towards actions that significantly impact the global latent state transitions. Additionally, ICES separates exploration policies from exploitation policies, enabling the former to utilize privileged global information during training. Extensive experiments on cooperative benchmark tasks with sparse rewards, including Google Research Football (GRF) and StarCraft Multi-agent Challenge (SMAC), demonstrate that ICES exhibits superior exploration capabilities compared with baselines. The code is publicly available at https://github.com/LXXXXR/ICES.