I-LLM: Efficient Integer-Only Inference for Fully-Quantized Low-Bit Large Language Models
作者: Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, Sifan Zhou
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-05-28 (更新: 2024-06-05)
💡 一句话要点
I-LLM:面向低比特大语言模型的全量化高效整数推理框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 后训练量化 整数推理 低比特量化 模型压缩
📋 核心要点
- 现有LLM量化方法依赖浮点运算,限制了其在资源受限设备上的部署。
- I-LLM通过全平滑块重构(FSBR)和动态整数矩阵乘法(DI-MatMul)等技术,实现全整数推理。
- 实验表明,I-LLM在W4A4量化下,精度与浮点基线相当,优于其他量化方法。
📝 摘要(中文)
后训练量化(PTQ)是加速大语言模型(LLM)推理的有效技术。然而,现有方法在推理过程中仍然需要大量的浮点(FP)运算,包括额外的量化和反量化,以及RMSNorm和Softmax等非线性算子。这限制了LLM在边缘和云设备上的部署。本文指出,LLM整数量化的主要障碍在于线性和非线性运算中激活值在通道和token上的巨大波动。为了解决这个问题,我们提出了I-LLM,一种为LLM量身定制的新型全整数PTQ框架。具体来说,(1)我们开发了全平滑块重构(FSBR)来积极平滑所有激活值和权重的通道间差异。(2)为了减轻token间差异造成的性能下降,我们引入了一种名为动态整数矩阵乘法(DI-MatMul)的新方法。该方法通过动态量化输入和输出,在全整数矩阵乘法中实现动态量化。(3)我们设计了DI-ClippedSoftmax、DI-Exp和DI-Normalization,它们利用位移来高效地执行非线性算子,同时保持精度。实验表明,我们的I-LLM实现了与FP基线相当的精度,并且优于非整数量化方法。例如,I-LLM可以在W4A4下运行,且精度损失可忽略不计。据我们所知,我们是第一个弥合整数量化和LLM之间差距的人。我们已在anonymous.4open.science上发布了我们的代码,旨在为该领域的发展做出贡献。
🔬 方法详解
问题定义:现有大语言模型的后训练量化方法,虽然可以加速推理,但仍然依赖大量的浮点运算,例如量化/反量化以及非线性算子。这阻碍了LLM在边缘设备和云端服务器上的部署,因为这些设备通常对计算资源和能耗有严格的限制。因此,需要一种完全基于整数运算的量化方案,以充分利用硬件加速能力,降低计算成本。
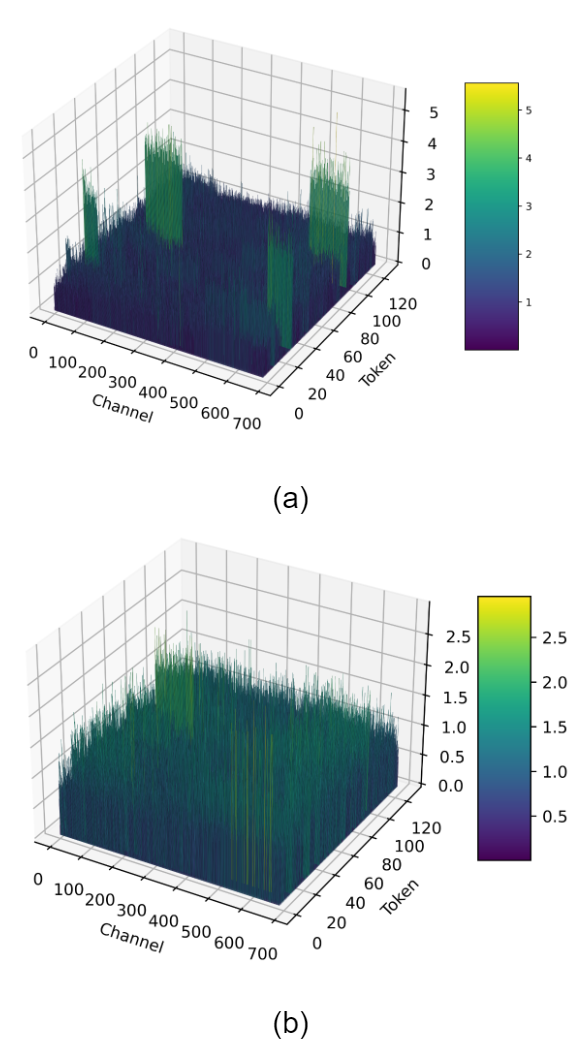
核心思路:I-LLM的核心思路是通过平滑激活值和权重的分布,以及动态调整量化参数,来克服整数量化对LLM性能的影响。具体来说,它关注于解决两个关键问题:一是激活值在通道间的巨大波动,二是激活值在token间的巨大波动。通过解决这两个问题,I-LLM能够实现全整数的推理过程,避免浮点运算带来的性能瓶颈。
技术框架:I-LLM是一个后训练量化框架,主要包含以下几个模块:1) Fully-Smooth Block-Reconstruction (FSBR):用于平滑激活值和权重的通道间差异。2) Dynamic Integer-only MatMul (DI-MatMul):用于在全整数矩阵乘法中实现动态量化,以减轻token间差异的影响。3) DI-ClippedSoftmax, DI-Exp, DI-Normalization:用于高效地执行非线性算子,同时保持精度。整个框架的目标是实现LLM的全整数推理,从而提高推理效率并降低计算成本。
关键创新:I-LLM的关键创新在于其全整数的设计,以及针对LLM特点提出的FSBR和DI-MatMul等技术。与现有方法相比,I-LLM避免了浮点运算,从而能够更好地利用硬件加速能力。此外,FSBR和DI-MatMul能够有效地解决激活值波动的问题,从而提高量化精度。
关键设计:FSBR通过块重构的方式,平滑通道间的激活值和权重分布。DI-MatMul则通过动态调整量化参数,适应token间的激活值变化。DI-ClippedSoftmax、DI-Exp和DI-Normalization则利用位移操作,近似实现非线性算子,避免了浮点运算。这些设计共同保证了I-LLM在全整数推理的同时,能够保持较高的精度。
🖼️ 关键图片


📊 实验亮点
I-LLM在W4A4量化下实现了与浮点基线相当的精度,并且优于非整数量化方法。这意味着I-LLM能够在保持精度的同时,显著提高推理效率。实验结果表明,I-LLM成功地弥合了整数量化和LLM之间的差距,为LLM在资源受限设备上的部署提供了新的可能性。
🎯 应用场景
I-LLM具有广泛的应用前景,尤其是在资源受限的边缘设备和云端服务器上。它可以用于加速LLM的推理,从而提高响应速度和吞吐量。此外,I-LLM还可以降低计算成本和能耗,使得LLM能够在更多的场景中部署和应用,例如智能手机、物联网设备和自动驾驶系统等。未来,I-LLM有望成为LLM部署的重要技术手段。
📄 摘要(原文)
Post-training quantization (PTQ) serves as a potent technique to accelerate the inference of large language models (LLMs). Nonetheless, existing works still necessitate a considerable number of floating-point (FP) operations during inference, including additional quantization and de-quantization, as well as non-linear operators such as RMSNorm and Softmax. This limitation hinders the deployment of LLMs on the edge and cloud devices. In this paper, we identify the primary obstacle to integer-only quantization for LLMs lies in the large fluctuation of activations across channels and tokens in both linear and non-linear operations. To address this issue, we propose I-LLM, a novel integer-only fully-quantized PTQ framework tailored for LLMs. Specifically, (1) we develop Fully-Smooth Block-Reconstruction (FSBR) to aggressively smooth inter-channel variations of all activations and weights. (2) to alleviate degradation caused by inter-token variations, we introduce a novel approach called Dynamic Integer-only MatMul (DI-MatMul). This method enables dynamic quantization in full-integer matrix multiplication by dynamically quantizing the input and outputs with integer-only operations. (3) we design DI-ClippedSoftmax, DI-Exp, and DI-Normalization, which utilize bit shift to execute non-linear operators efficiently while maintaining accuracy. The experiment shows that our I-LLM achieves comparable accuracy to the FP baseline and outperforms non-integer quantization methods. For example, I-LLM can operate at W4A4 with negligible loss of accuracy. To our knowledge, we are the first to bridge the gap between integer-only quantization and LLMs. We've published our code on anonymous.4open.science, aiming to contribute to the advancement of this field.