Linguistic Collapse: Neural Collapse in (Large) Language Models
作者: Robert Wu, Vardan Papyan
分类: cs.LG, cs.CL, stat.ML
发布日期: 2024-05-28 (更新: 2024-11-26)
备注: NeurIPS 2024; 35 pages; 30 figures; reverted to log mean norms for NC2
🔗 代码/项目: GITHUB
💡 一句话要点
研究发现大规模语言模型中涌现语言坍缩现象,并揭示其与泛化能力的关联
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经坍缩 大规模语言模型 语言建模 泛化能力 因果语言模型
📋 核心要点
- 现有研究对神经坍缩现象的探索主要集中在理想化的分类任务设置下,而语言建模任务的特殊性使其不满足这些条件,为研究带来了挑战。
- 该论文的核心思想是研究大规模因果语言模型在训练过程中神经坍缩现象的演变,并分析其与模型泛化能力之间的关系。
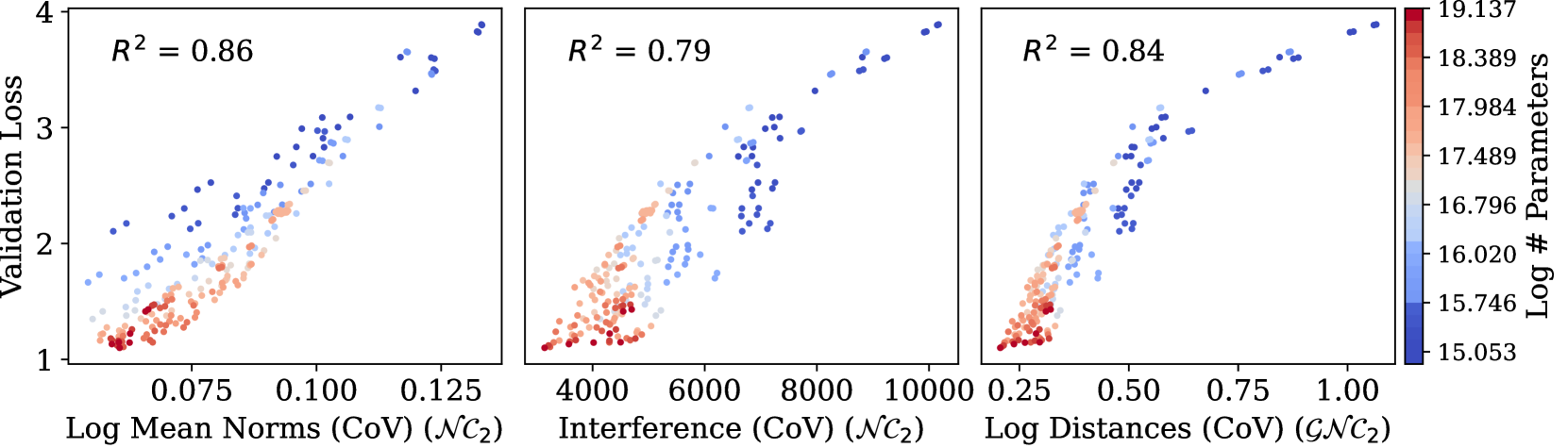
- 研究发现,随着模型规模的扩大和正则化的应用,神经坍缩的特性逐渐显现,并且这些特性与模型的泛化能力密切相关,揭示了神经坍缩在语言建模中的重要性。
📝 摘要(中文)
神经坍缩(NC)是一种在分类任务中观察到的现象,其中顶层表示坍缩为其类别均值,这些均值变得等范数、等角度并与分类器对齐。这些与泛化和鲁棒性相关的行为会在特定条件下显现:模型在无噪声标签和平衡类别下训练至零损失,且类别数量不超过模型的隐藏维度。最近的研究探索了在缺少一个或多个这些条件下的NC,以扩展和利用理想几何形状的相关优势。语言建模提出了一个有趣的领域,因为通过token预测进行训练构成了一个分类任务,其中没有一个条件存在:词汇表是不平衡的,并且超过了嵌入维度;不同的token可能对应于相似的上下文嵌入;特别是大型语言模型(LLM)通常只训练几个epoch。本文实证研究了缩放因果语言模型(CLM)的架构和训练对其向NC发展的进展的影响。我们发现,随着规模(和正则化)发展起来的NC属性与泛化相关。此外,有证据表明NC和泛化之间存在某种独立于规模的关系。因此,我们的工作强调了NC的普遍性,因为它扩展到了语言建模这一新颖且更具挑战性的设置。在下游,我们希望激发对该现象的进一步研究,以加深我们对LLM(以及大型神经网络)的理解,并改进基于NC相关属性的现有架构。我们的代码托管在GitHub上。
🔬 方法详解
问题定义:论文旨在研究大规模语言模型(LLM)中是否存在神经坍缩(Neural Collapse, NC)现象,以及该现象与模型泛化能力之间的关系。现有的关于NC的研究主要集中在图像分类等任务上,这些任务通常满足一些理想条件,例如平衡的数据集、充足的训练以及类别数量小于隐藏层维度等。然而,语言建模任务并不满足这些条件,例如词汇表通常非常大且不平衡,训练数据有限,这使得直接将现有的NC理论应用于LLM变得困难。
核心思路:论文的核心思路是通过实证研究,观察不同规模的因果语言模型(Causal Language Models, CLM)在训练过程中NC特性的演变。通过分析模型内部表示的几何结构,例如类内方差、类间方差、分类器权重等,来判断NC现象是否发生,并进一步研究NC特性与模型泛化能力之间的关联。论文假设,如果LLM中存在NC现象,并且该现象与泛化能力相关,那么可以通过优化NC相关的指标来提升模型的性能。
技术框架:论文的研究框架主要包括以下几个步骤:1) 选择不同规模的CLM模型作为研究对象;2) 使用标准的语言建模任务对模型进行训练;3) 在训练过程中,定期计算模型内部表示的NC相关指标,例如类内方差、类间方差、分类器权重等;4) 分析NC指标随训练步数的变化趋势,以及不同规模模型之间的差异;5) 将NC指标与模型的泛化能力(例如在下游任务上的性能)进行关联分析,以验证NC与泛化能力之间的关系。
关键创新:论文的关键创新在于将神经坍缩(NC)的概念扩展到语言建模领域,并实证研究了大规模语言模型(LLM)中NC现象的存在性及其与泛化能力的关系。以往的NC研究主要集中在图像分类等任务上,而语言建模任务具有其特殊性,例如词汇表巨大且不平衡,训练数据有限等。论文的研究结果表明,即使在这些非理想条件下,LLM中仍然存在NC现象,并且该现象与模型的泛化能力密切相关。
关键设计:论文的关键设计包括:1) 选择不同规模的CLM模型,以便研究模型规模对NC现象的影响;2) 使用标准的语言建模任务和数据集,以便与其他研究进行比较;3) 设计合适的NC指标,例如类内方差、类间方差、分类器权重等,以便量化NC现象的程度;4) 使用多种统计方法,例如相关性分析、回归分析等,以便分析NC指标与模型泛化能力之间的关系。
🖼️ 关键图片


📊 实验亮点
研究发现,随着模型规模的扩大和正则化的应用,神经坍缩的特性逐渐显现,并且这些特性与模型的泛化能力密切相关。此外,研究还发现,即使在模型规模较小的情况下,神经坍缩与泛化能力之间也存在一定的关联,这表明神经坍缩可能是一种普遍存在的现象,而不仅仅是大型模型的涌现特性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的性能和可解释性。通过理解和优化神经坍缩现象,可以设计更高效的训练策略和模型架构,从而提高模型的泛化能力和鲁棒性。此外,该研究也有助于深入理解神经网络的工作机制,为人工智能领域的发展提供理论基础。
📄 摘要(原文)
Neural collapse ($\mathcal{NC}$) is a phenomenon observed in classification tasks where top-layer representations collapse into their class means, which become equinorm, equiangular and aligned with the classifiers. These behaviours -- associated with generalization and robustness -- would manifest under specific conditions: models are trained towards zero loss, with noise-free labels belonging to balanced classes, which do not outnumber the model's hidden dimension. Recent studies have explored $\mathcal{NC}$ in the absence of one or more of these conditions to extend and capitalize on the associated benefits of ideal geometries. Language modelling presents a curious frontier, as \textit{training by token prediction} constitutes a classification task where none of the conditions exist: the vocabulary is imbalanced and exceeds the embedding dimension; different tokens might correspond to similar contextual embeddings; and large language models (LLMs) in particular are typically only trained for a few epochs. This paper empirically investigates the impact of scaling the architectures and training of causal language models (CLMs) on their progression towards $\mathcal{NC}$. We find that $\mathcal{NC}$ properties that develop with scale (and regularization) are linked to generalization. Moreover, there is evidence of some relationship between $\mathcal{NC}$ and generalization independent of scale. Our work thereby underscores the generality of $\mathcal{NC}$ as it extends to the novel and more challenging setting of language modelling. Downstream, we seek to inspire further research on the phenomenon to deepen our understanding of LLMs -- and neural networks at large -- and improve existing architectures based on $\mathcal{NC}$-related properties. Our code is hosted on GitHub at https://github.com/rhubarbwu/linguistic-collapse .