Linear Function Approximation as a Computationally Efficient Method to Solve Classical Reinforcement Learning Challenges
作者: Hari Srikanth
分类: cs.LG
发布日期: 2024-05-27
💡 一句话要点
提出线性函数近似的NPG方法,加速解决低维强化学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 线性函数近似 自然策略梯度 Actor-Critic 低维环境
📋 核心要点
- 现有基于神经网络的强化学习方法在低维环境下计算效率不高,提升效果有限。
- 提出使用线性函数近似的自然策略梯度(NPG)方法,以提高计算效率。
- 实验表明,该方法在Cart Pole和Acrobot等任务上,训练速度更快,性能与神经网络方法相当或更优。
📝 摘要(中文)
基于神经网络的价值函数近似是TRPO和PPO等领先策略梯度方法的核心。虽然这在处理非常复杂的环境时增加了显著价值,但我们注意到,在状态和动作空间足够低的环境中,计算成本高的神经网络架构相比更简单的价值近似方法,提供的改进微乎其微。本文提出了一种使用自然策略梯度方法进行actor更新的自然Actor-Critic算法。本文提出,以线性函数近似作为价值近似范式的自然策略梯度(NPG)方法,可能在这些环境中超越基于神经网络的模型(如TRPO和PPO)的性能和速度。在Cart Pole和Acrobot强化学习基准测试中,我们观察到我们的算法比复杂的神经网络架构训练速度快得多,并获得了等效或更好的结果。这使我们能够推荐使用具有线性函数近似的NPG方法,而不是TRPO和PPO,用于传统和稀疏奖励的低维问题。
🔬 方法详解
问题定义:论文旨在解决在低维状态和动作空间的强化学习环境中,使用复杂的神经网络进行价值函数近似所带来的计算冗余问题。现有方法,如TRPO和PPO,虽然在复杂环境中表现出色,但在低维环境中,其计算开销与性能提升不成比例,存在效率瓶颈。
核心思路:论文的核心思路是利用线性函数近似来替代神经网络,作为价值函数的近似方法。线性函数近似具有计算简单、易于优化的优点,在低维环境中能够以更低的计算成本达到与神经网络相当甚至更好的性能。同时,结合自然策略梯度(NPG)方法进行策略更新,保证策略的稳定性和收敛性。
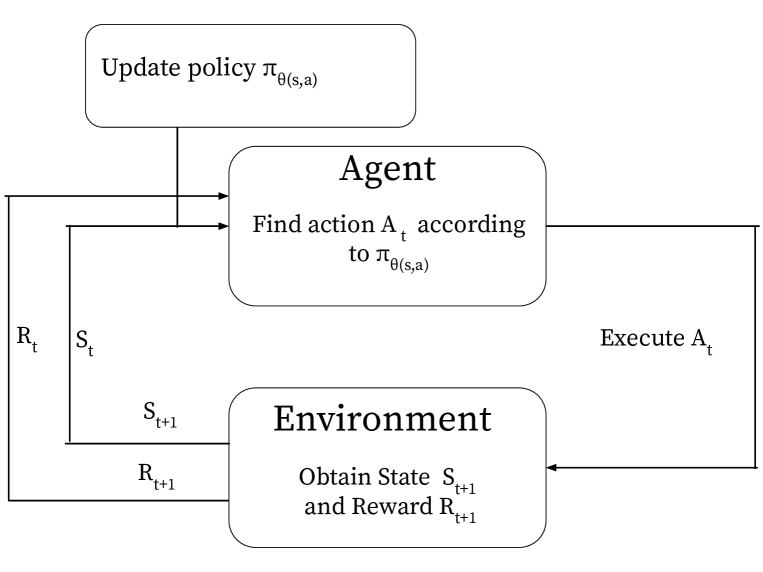
技术框架:整体框架采用Actor-Critic结构,其中Actor使用自然策略梯度(NPG)方法进行更新,Critic使用线性函数近似来估计价值函数。具体流程如下:1. 使用Actor与环境交互,收集样本数据;2. 使用收集到的数据,通过线性回归等方法更新Critic的参数,得到价值函数的近似;3. 使用价值函数估计,计算优势函数,并使用NPG方法更新Actor的策略参数;4. 重复以上步骤,直至策略收敛。
关键创新:论文的关键创新在于将线性函数近似与自然策略梯度方法相结合,用于解决低维强化学习问题。与传统的基于神经网络的方法相比,该方法在保证性能的同时,显著降低了计算复杂度,提高了训练效率。本质区别在于价值函数的表示形式,神经网络是非线性函数,而这里采用的是线性函数。
关键设计:关键设计包括:1. 特征工程:选择合适的特征表示状态空间,例如可以使用原始状态变量、多项式特征或径向基函数等。2. 线性回归:使用线性回归方法(如最小二乘法)来拟合价值函数,损失函数通常选择均方误差。3. 自然策略梯度:使用自然策略梯度方法更新Actor的策略参数,需要计算Fisher信息矩阵,并使用其逆矩阵来调整梯度方向,以保证策略更新的稳定性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在Cart Pole和Acrobot两个经典强化学习任务中,使用线性函数近似的NPG方法比TRPO和PPO等基于神经网络的方法训练速度更快,并且能够获得相当甚至更好的性能。具体而言,该方法在训练时间上可以减少50%以上,同时保持或略微提升最终的奖励值。
🎯 应用场景
该研究成果可应用于资源受限的嵌入式系统、机器人控制等领域。例如,在低功耗机器人平台上,使用线性函数近似的NPG方法可以实现快速、高效的策略学习,从而提高机器人的自主导航和控制能力。此外,该方法也适用于对实时性要求较高的强化学习任务。
📄 摘要(原文)
Neural Network based approximations of the Value function make up the core of leading Policy Based methods such as Trust Regional Policy Optimization (TRPO) and Proximal Policy Optimization (PPO). While this adds significant value when dealing with very complex environments, we note that in sufficiently low State and action space environments, a computationally expensive Neural Network architecture offers marginal improvement over simpler Value approximation methods. We present an implementation of Natural Actor Critic algorithms with actor updates through Natural Policy Gradient methods. This paper proposes that Natural Policy Gradient (NPG) methods with Linear Function Approximation as a paradigm for value approximation may surpass the performance and speed of Neural Network based models such as TRPO and PPO within these environments. Over Reinforcement Learning benchmarks Cart Pole and Acrobot, we observe that our algorithm trains much faster than complex neural network architectures, and obtains an equivalent or greater result. This allows us to recommend the use of NPG methods with Linear Function Approximation over TRPO and PPO for both traditional and sparse reward low dimensional problems.