Mechanistic Interpretability of Binary and Ternary Transformers
作者: Jason Li
分类: cs.LG, cs.CL
发布日期: 2024-05-27
💡 一句话要点
研究二元和三元Transformer网络的可解释性,揭示其与全精度网络的算法相似性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机制可解释性 二元网络 三元网络 Transformer网络 模型压缩 大型语言模型 模块化加法
📋 核心要点
- 大型语言模型内存需求高、推理速度慢,二元和三元Transformer网络是潜在的解决方案。
- 论文采用机制可解释性方法,对比二元、三元和全精度Transformer网络学习到的算法。
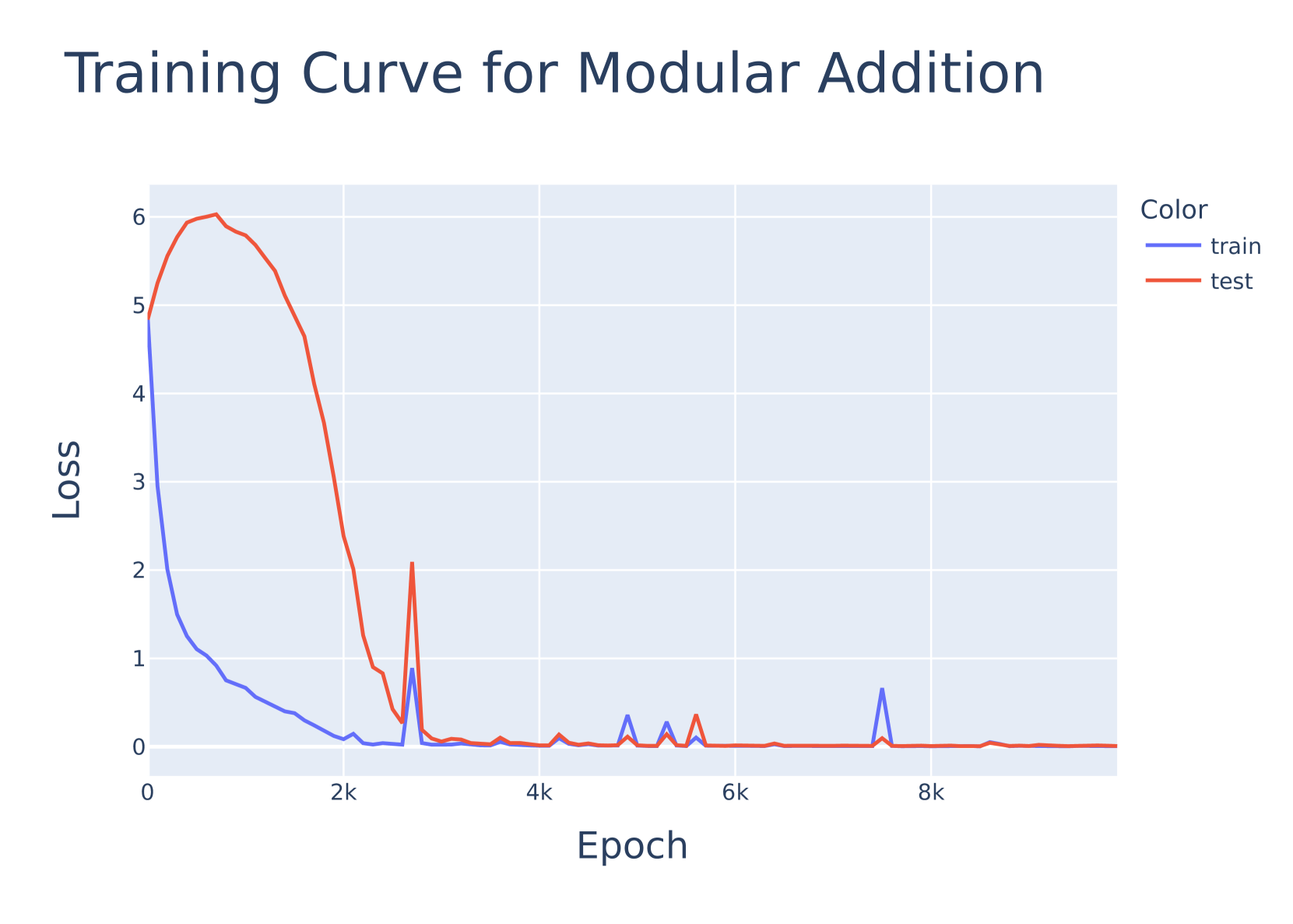
- 实验表明,在模块化加法任务上,二元和三元网络学习到的算法与全精度网络相似。
📝 摘要(中文)
近期研究表明,二元和三元Transformer网络能够在保持精度的同时,显著降低大型语言模型(LLM)的内存占用并提高推理速度。本文应用机制可解释性技术,研究这些网络与全精度Transformer网络相比,是否学习到截然不同或相似的算法。具体而言,我们对模块化加法的玩具问题进行了逆向工程,发现二元和三元网络学习到的算法与全精度网络相似。这表明,使用二元和三元网络作为LLM中更易于解释的替代方案的可能性较低。
🔬 方法详解
问题定义:论文旨在研究二元和三元Transformer网络是否学习到与全精度Transformer网络不同的算法。现有方法虽然在压缩模型和加速推理方面取得了进展,但缺乏对这些压缩模型内部机制的深入理解,特别是它们是否改变了模型解决问题的方式。
核心思路:论文的核心思路是通过机制可解释性技术,对二元、三元和全精度Transformer网络在同一任务上的学习结果进行比较。如果二元和三元网络学习到与全精度网络不同的算法,那么它们可能提供了一种更易于理解的LLM替代方案。反之,如果算法相似,则表明压缩过程并未根本上改变模型的行为。
技术框架:论文采用的整体框架包括:1) 选择一个简单的玩具问题(模块化加法)作为研究对象;2) 分别训练二元、三元和全精度Transformer网络来解决该问题;3) 使用机制可解释性技术(例如,逆向工程)来分析这些网络学习到的算法;4) 比较不同网络学习到的算法,以确定它们之间的相似性和差异。
关键创新:论文的关键创新在于将机制可解释性技术应用于分析二元和三元Transformer网络。以往的研究主要关注这些网络的性能指标(例如,精度、速度、内存占用),而忽略了它们内部机制的变化。通过分析网络学习到的算法,论文能够更深入地理解压缩过程对模型行为的影响。
关键设计:论文的关键设计包括:1) 选择模块化加法作为玩具问题,因为它足够简单,便于进行逆向工程;2) 使用标准的Transformer网络结构,并对权重进行二元化或三元化;3) 采用适当的训练方法,以确保二元和三元网络能够收敛并达到可接受的精度;4) 使用各种机制可解释性技术(例如,注意力模式分析、激活值分析)来理解网络学习到的算法。
🖼️ 关键图片


📊 实验亮点
论文通过对模块化加法任务的实验,发现二元和三元Transformer网络学习到的算法与全精度网络相似。这一结果表明,简单地使用二元或三元网络可能无法直接提高LLM的可解释性,需要进一步探索更有效的可解释性方法。
🎯 应用场景
该研究成果有助于理解模型压缩对大型语言模型内部机制的影响,为设计更高效、更可解释的压缩算法提供指导。潜在应用领域包括资源受限设备上的LLM部署、对模型行为有严格要求的安全关键应用等。未来的研究可以探索更复杂的任务和模型,以进一步验证该结论。
📄 摘要(原文)
Recent research (arXiv:2310.11453, arXiv:2402.17764) has proposed binary and ternary transformer networks as a way to significantly reduce memory and improve inference speed in Large Language Models (LLMs) while maintaining accuracy. In this work, we apply techniques from mechanistic interpretability to investigate whether such networks learn distinctly different or similar algorithms when compared to full-precision transformer networks. In particular, we reverse engineer the algorithms learned for the toy problem of modular addition where we find that binary and ternary networks learn similar algorithms as full precision networks. This provides evidence against the possibility of using binary and ternary networks as a more interpretable alternative in the LLM setting.