Symmetric Reinforcement Learning Loss for Robust Learning on Diverse Tasks and Model Scales
作者: Ju-Seung Byun, Andrew Perrault
分类: cs.LG, cs.AI
发布日期: 2024-05-27 (更新: 2025-06-23)
💡 一句话要点
提出对称强化学习损失,增强RL在多样任务和模型规模下的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 鲁棒性 对称损失 反向交叉熵 RLHF RLAIF 噪声数据 策略优化
📋 核心要点
- 传统强化学习训练面临移动目标和高梯度方差等问题,RLHF/RLAIF进一步增加了训练难度,例如奖励模型误差。
- 论文借鉴监督学习中的反向交叉熵(RCE)思想,提出对称强化学习损失,以增强RL训练的稳定性。
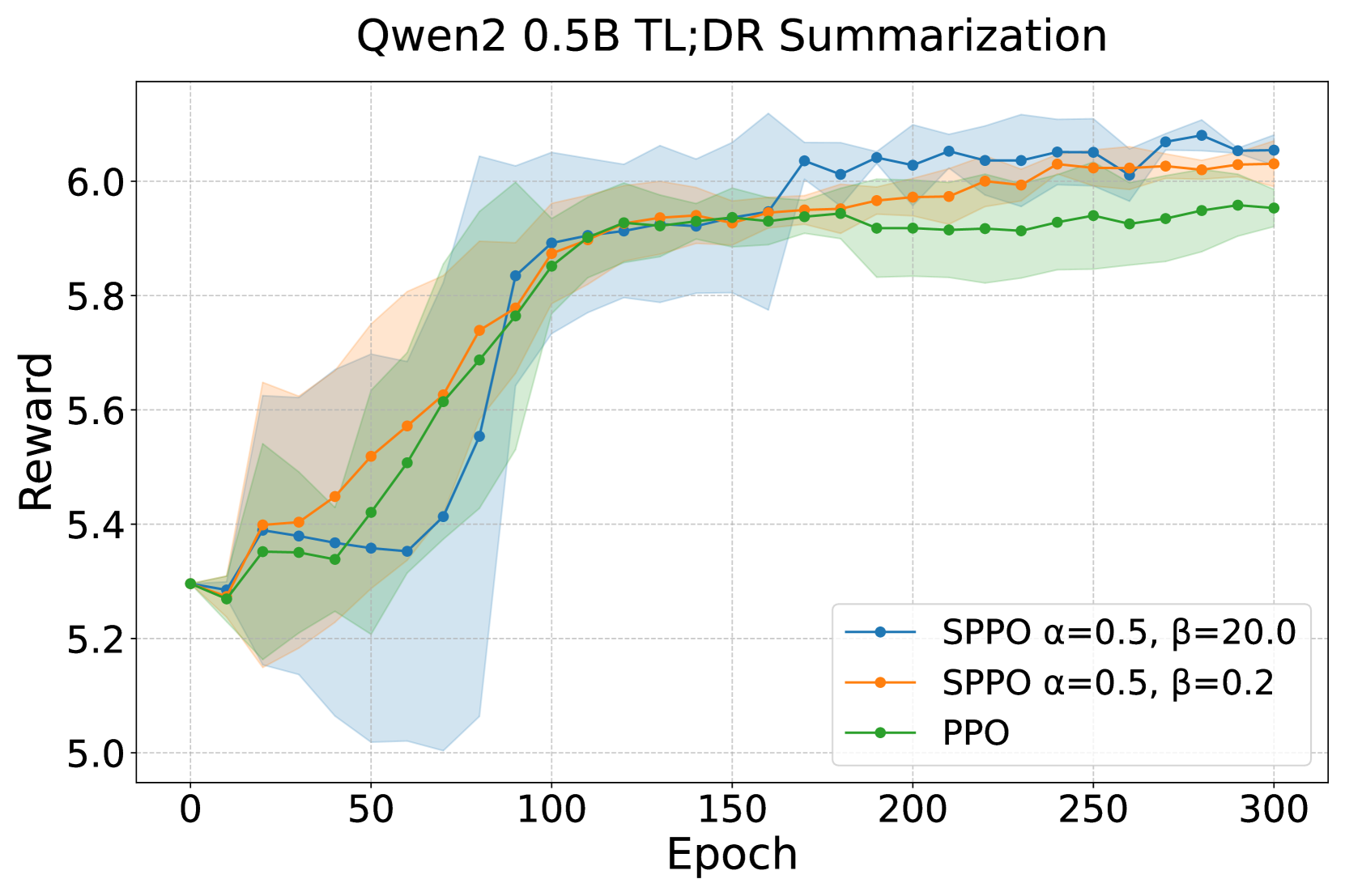
- 实验表明,对称RL损失在Atari、MuJoCo等任务以及RLHF任务中均能提升性能,尤其是在SPPO算法中。
📝 摘要(中文)
强化学习(RL)训练本质上是不稳定的,这归因于移动目标和高梯度方差等因素。从人类反馈中进行强化学习(RLHF)和从AI反馈中进行强化学习(RLAIF)可能会引入额外的困难。不同的偏好会使对齐过程复杂化,并且当LLM生成未见过的输出时,训练后的奖励模型中的预测误差可能会变得更加严重。为了增强训练的鲁棒性,RL已经采用了监督学习中的技术,例如集成和层归一化。在这项工作中,我们通过调整监督学习中用于噪声数据的反向交叉熵(RCE)来定义对称RL损失,从而提高RL训练的稳定性。我们证明了在各种任务和规模上的性能改进。我们使用对称A2C(SA2C)和对称PPO(SPPO)在离散动作任务(Atari游戏)和连续动作空间任务(MuJoCo基准和Box2D)中进行了实验,无论是否添加噪声,SPPO在不同的超参数下都表现出特别显著的性能。此外,我们通过在RLHF任务(如IMDB正面情感和TL;DR摘要任务)中提高性能,验证了对称RL损失在使用SPPO进行大型语言模型训练时的优势。
🔬 方法详解
问题定义:强化学习训练的固有不稳定性,以及RLHF/RLAIF带来的额外挑战,使得模型训练的鲁棒性成为一个关键问题。现有方法,如直接应用监督学习的技巧(集成、层归一化),在强化学习场景下的效果有限,无法有效应对奖励模型误差和策略探索带来的噪声数据。
核心思路:借鉴监督学习中处理噪声数据的反向交叉熵(RCE)损失,将其适配到强化学习领域,构建对称的损失函数。核心思想是,通过同时考虑策略和价值函数的预测误差,并对二者进行平衡,从而降低噪声数据对训练的影响,提高模型的鲁棒性。
技术框架:该方法主要通过修改强化学习算法中的损失函数来实现。具体而言,将原有的策略梯度损失或PPO的clip损失,替换为对称的损失函数。整体训练流程与原算法保持一致,无需引入额外的模块或阶段。
关键创新:将反向交叉熵损失的思想引入强化学习,并将其推广到对称损失的形式。这种对称性体现在同时考虑策略和价值函数的预测误差,并利用超参数进行平衡。与传统方法相比,该方法更关注于降低噪声数据的影响,而非简单地平滑梯度或增加模型复杂度。
关键设计:对称损失函数的具体形式未知,但可以推测其包含两部分:一部分衡量策略的预测与目标策略的差异,另一部分衡量价值函数的预测与目标价值的差异。通过超参数来调节两部分的权重,以适应不同的任务和数据分布。具体实现可能需要对策略梯度或PPO的clip损失进行修改,以引入反向交叉熵的思想。
🖼️ 关键图片


📊 实验亮点
实验结果表明,对称RL损失在Atari游戏、MuJoCo基准和Box2D等任务中均能提升性能。特别是在SPPO算法中,即使在不同的超参数设置下,也能观察到显著的性能提升。此外,在RLHF任务(如IMDB情感分析和TL;DR摘要)中,使用对称RL损失的SPPO算法也表现出更好的性能。
🎯 应用场景
该研究成果可广泛应用于各种强化学习任务中,尤其是在数据质量不高或存在噪声的情况下,例如机器人控制、游戏AI、推荐系统等。此外,该方法在RLHF/RLAIF场景下具有重要意义,可以提高大型语言模型对齐的稳定性和可靠性,降低奖励模型误差带来的负面影响。
📄 摘要(原文)
Reinforcement learning (RL) training is inherently unstable due to factors such as moving targets and high gradient variance. Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning from AI Feedback (RLAIF) can introduce additional difficulty. Differing preferences can complicate the alignment process, and prediction errors in a trained reward model can become more severe as the LLM generates unseen outputs. To enhance training robustness, RL has adopted techniques from supervised learning, such as ensembles and layer normalization. In this work, we improve the stability of RL training by adapting the reverse cross entropy (RCE) from supervised learning for noisy data to define a symmetric RL loss. We demonstrate performance improvements across various tasks and scales. We conduct experiments in discrete action tasks (Atari games) and continuous action space tasks (MuJoCo benchmark and Box2D) using Symmetric A2C (SA2C) and Symmetric PPO (SPPO), with and without added noise with especially notable performance in SPPO across different hyperparameters. Furthermore, we validate the benefits of the symmetric RL loss when using SPPO for large language models through improved performance in RLHF tasks, such as IMDB positive sentiment sentiment and TL;DR summarization tasks.