$\textit{Trans-LoRA}$: towards data-free Transferable Parameter Efficient Finetuning
作者: Runqian Wang, Soumya Ghosh, David Cox, Diego Antognini, Aude Oliva, Rogerio Feris, Leonid Karlinsky
分类: cs.LG, cs.AI
发布日期: 2024-05-27
💡 一句话要点
提出Trans-LoRA,实现LoRA模块在不同基模型间的无损近无数据迁移。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 LoRA迁移 合成数据 无数据学习 知识迁移
📋 核心要点
- 现有LoRA方法依赖特定基模型,更换基模型需重新训练LoRA,且需访问原始训练数据,这在商业云环境中存在数据隐私问题。
- Trans-LoRA利用合成数据,近似原始任务数据分布,从而实现LoRA模块在不同基模型间的迁移,无需访问原始数据。
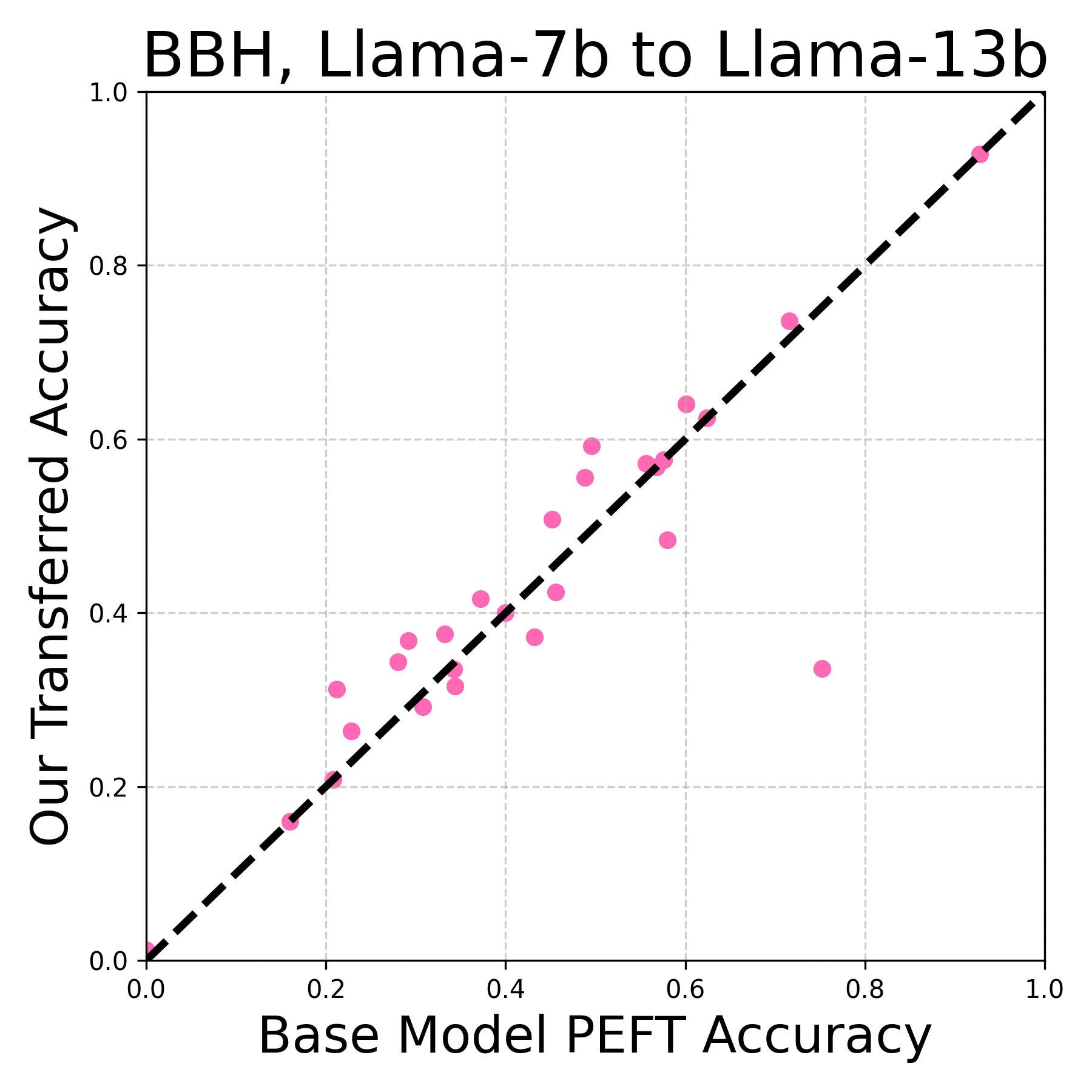
- 实验表明,Trans-LoRA在LLama和Gemma模型家族上,实现了LoRA模块的无损迁移,甚至在不同PEFT方法间也能有效迁移。
📝 摘要(中文)
低秩适配器(LoRA)及其变体是流行的参数高效微调(PEFT)技术,它们在仅需少量额外参数的情况下,性能与完整模型微调非常接近。这些额外的LoRA参数特定于被适配的基础模型。当基础模型需要被弃用并替换为新的模型时,所有相关的LoRA模块都需要重新训练。这种重新训练需要访问用于训练原始基础模型LoRA的数据。对于商业云应用来说,这尤其成问题,因为LoRA模块和基础模型由服务提供商托管,而服务提供商可能不允许托管专有的客户端任务数据。为了解决这个挑战,我们提出Trans-LoRA——一种用于在基础模型之间无损、近乎无数据地迁移LoRA的新方法。我们的方法依赖于合成数据来迁移LoRA模块。利用大型语言模型,我们设计了一个合成数据生成器来近似观察到的任务数据子集的数据生成过程。在生成的合成数据集上进行训练,将LoRA模块迁移到新的模型。我们使用LLama和Gemma模型家族展示了我们方法的有效性。我们的方法在各种任务上实现了模型内部和跨不同基础模型家族,甚至在不同PEFT方法之间的无损(大部分是改进的)LoRA迁移。
🔬 方法详解
问题定义:现有参数高效微调方法(如LoRA)获得的适配器参数与特定基础模型绑定。当需要更换基础模型时,必须重新训练适配器,这需要访问原始训练数据,在数据隐私敏感的场景下(例如商业云服务)是不可行的。因此,问题在于如何在不访问原始数据的情况下,将已训练的LoRA模块迁移到新的基础模型上。
核心思路:Trans-LoRA的核心思路是利用合成数据来模拟原始训练数据的分布,从而在新的基础模型上重新训练LoRA模块。通过在合成数据上训练,LoRA模块能够学习到与原始任务相关的知识,而无需直接访问原始数据,从而实现知识迁移。
技术框架:Trans-LoRA的整体框架包含以下几个主要阶段: 1. 合成数据生成:使用大型语言模型(LLM)作为生成器,生成与原始任务数据分布相似的合成数据。 2. LoRA模块迁移:在新模型上,使用生成的合成数据重新训练LoRA模块,从而将原始LoRA模块的知识迁移到新模型。 3. 评估:在真实数据集上评估迁移后的LoRA模块的性能。
关键创新:Trans-LoRA的关键创新在于利用合成数据实现了LoRA模块的无数据迁移。与传统的需要访问原始数据的迁移学习方法不同,Trans-LoRA通过学习原始数据的分布,生成合成数据,从而避免了数据隐私问题。此外,该方法还能够实现跨不同模型架构和PEFT方法的LoRA迁移。
关键设计:在合成数据生成阶段,论文使用了prompt工程来指导LLM生成更符合原始数据分布的合成数据。具体来说,通过设计合适的prompt,可以控制LLM生成特定类型的文本,例如问答对、摘要等。此外,论文还探索了不同的损失函数来优化LoRA模块的训练,例如交叉熵损失和对比损失。
🖼️ 关键图片


📊 实验亮点
Trans-LoRA在LLama和Gemma模型家族上进行了广泛的实验,结果表明,该方法能够实现LoRA模块的无损迁移,甚至在某些情况下,迁移后的LoRA模块性能优于原始LoRA模块。此外,实验还表明,Trans-LoRA能够实现跨不同PEFT方法的LoRA迁移,例如将一个在LoRA上训练的模块迁移到Adapter上。
🎯 应用场景
Trans-LoRA在商业云服务、边缘计算等数据隐私敏感的场景下具有广泛的应用前景。例如,云服务提供商可以在不访问客户数据的情况下,将客户定制的LoRA模块迁移到新的基础模型上,从而提高服务质量和效率。此外,该方法还可以用于跨语言、跨领域的知识迁移,例如将一个在英语数据集上训练的LoRA模块迁移到中文数据集上。
📄 摘要(原文)
Low-rank adapters (LoRA) and their variants are popular parameter-efficient fine-tuning (PEFT) techniques that closely match full model fine-tune performance while requiring only a small number of additional parameters. These additional LoRA parameters are specific to the base model being adapted. When the base model needs to be deprecated and replaced with a new one, all the associated LoRA modules need to be re-trained. Such re-training requires access to the data used to train the LoRA for the original base model. This is especially problematic for commercial cloud applications where the LoRA modules and the base models are hosted by service providers who may not be allowed to host proprietary client task data. To address this challenge, we propose $\textit{Trans-LoRA}$ -- a novel method for lossless, nearly data-free transfer of LoRAs across base models. Our approach relies on synthetic data to transfer LoRA modules. Using large language models, we design a synthetic data generator to approximate the data-generating process of the $\textit{observed}$ task data subset. Training on the resulting synthetic dataset transfers LoRA modules to new models. We show the effectiveness of our approach using both LLama and Gemma model families. Our approach achieves lossless (mostly improved) LoRA transfer between models within and across different base model families, and even between different PEFT methods, on a wide variety of tasks.