Spectral regularization for adversarially-robust representation learning
作者: Sheng Yang, Jacob A. Zavatone-Veth, Cengiz Pehlevan
分类: cs.LG, cs.CV
发布日期: 2024-05-27
备注: 15 + 15 pages, 8 + 11 figures
💡 一句话要点
提出谱正则化方法,提升表征学习的对抗鲁棒性,尤其适用于自监督学习。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 对抗鲁棒性 表征学习 谱正则化 自监督学习 神经网络 对抗攻击 特征空间 黑盒攻击
📋 核心要点
- 现有对抗训练方法通常对整个网络进行正则化,忽略了表征学习中特征空间的重要性。
- 提出一种谱正则化方法,专注于特征空间的正则化,以提升下游任务的黑盒对抗鲁棒性。
- 实验表明,该方法在监督学习和自监督学习中均能有效提高模型的测试精度和对抗鲁棒性。
📝 摘要(中文)
神经网络分类器易受对抗攻击影响,这严重阻碍了其在安全关键型应用中的部署。训练期间对网络参数进行正则化可以提高对抗鲁棒性和泛化性能。通常,网络是端到端正则化的,所有层的参数都受到影响。然而,在表征学习至关重要的场景中,例如自监督学习(SSL),特征表征之后的层在推理时将被丢弃。对于这些模型,正则化到特征空间更为合适。为此,我们提出了一种新的表征学习谱正则化器,旨在提高下游分类任务中的黑盒对抗鲁棒性。在监督分类设置中,实验表明,与先前正则化网络所有层的方法相比,该方法在提高测试精度和鲁棒性方面更有效。我们进一步证明,该方法可以提高使用自监督学习或从另一个分类任务迁移学习的表征的分类器的对抗鲁棒性。总而言之,我们的工作开始揭示表征结构如何影响对抗鲁棒性。
🔬 方法详解
问题定义:现有对抗训练方法通常对神经网络的所有层进行正则化,这在表征学习的场景下可能不是最优的。尤其是在自监督学习中,学习到的特征表示会被用于下游任务,而后续的网络层会被丢弃。因此,对整个网络进行正则化可能会引入不必要的约束,影响特征表示的质量和泛化能力。现有方法缺乏针对特征空间进行专门优化的正则化策略。
核心思路:论文的核心思路是提出一种谱正则化方法,直接作用于特征表示的谱,从而提高对抗鲁棒性。通过控制特征表示的谱特性,可以使得模型对输入扰动更加稳定,从而提高其对抗鲁棒性。这种方法特别适用于表征学习,因为它只关注特征空间,而忽略后续的网络层。
技术框架:该方法主要包含以下几个阶段:1)使用神经网络提取输入数据的特征表示;2)计算特征表示的谱;3)使用谱正则化器对特征表示的谱进行约束;4)使用对抗训练或其他方法对模型进行训练,以提高对抗鲁棒性。整体框架是在标准的神经网络训练流程中加入谱正则化项,以约束特征表示的谱特性。
关键创新:该方法最重要的技术创新点在于提出了谱正则化器,它可以直接作用于特征表示的谱,从而提高对抗鲁棒性。与现有方法相比,该方法更加专注于特征空间,可以更好地提高表征学习的性能。此外,该方法还可以与其他对抗训练方法相结合,进一步提高模型的对抗鲁棒性。
关键设计:谱正则化器的具体形式未知,论文中可能涉及对特征矩阵的奇异值进行约束,例如限制其最大奇异值或奇异值的衰减速度。损失函数包含标准的分类损失和谱正则化项,正则化系数用于平衡分类精度和对抗鲁棒性。具体的网络结构取决于具体的应用场景,可以是卷积神经网络、循环神经网络等。
🖼️ 关键图片
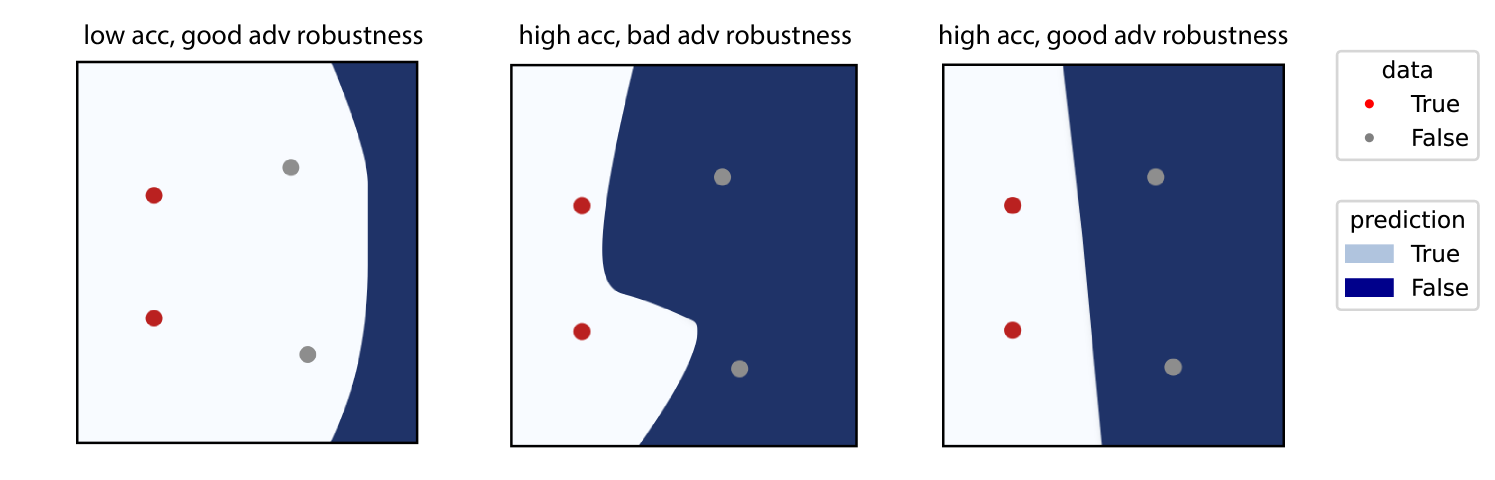


📊 实验亮点
实验结果表明,该方法在监督分类任务中,相较于正则化所有网络层的方法,能更有效地提升测试精度和对抗鲁棒性。同时,该方法也能提升使用自监督学习或迁移学习得到的表征的对抗鲁棒性。具体的性能提升数据未知,但论文强调了其优于现有方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要高安全性和可靠性的场景,例如自动驾驶、医疗诊断、金融风控等。通过提高模型的对抗鲁棒性,可以有效防止恶意攻击,保障系统的稳定运行。此外,该方法在自监督学习领域的应用,可以降低对标注数据的依赖,提高模型的泛化能力。
📄 摘要(原文)
The vulnerability of neural network classifiers to adversarial attacks is a major obstacle to their deployment in safety-critical applications. Regularization of network parameters during training can be used to improve adversarial robustness and generalization performance. Usually, the network is regularized end-to-end, with parameters at all layers affected by regularization. However, in settings where learning representations is key, such as self-supervised learning (SSL), layers after the feature representation will be discarded when performing inference. For these models, regularizing up to the feature space is more suitable. To this end, we propose a new spectral regularizer for representation learning that encourages black-box adversarial robustness in downstream classification tasks. In supervised classification settings, we show empirically that this method is more effective in boosting test accuracy and robustness than previously-proposed methods that regularize all layers of the network. We then show that this method improves the adversarial robustness of classifiers using representations learned with self-supervised training or transferred from another classification task. In all, our work begins to unveil how representational structure affects adversarial robustness.