Zamba: A Compact 7B SSM Hybrid Model
作者: Paolo Glorioso, Quentin Anthony, Yury Tokpanov, James Whittington, Jonathan Pilault, Adam Ibrahim, Beren Millidge
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-05-26
💡 一句话要点
Zamba:一种紧凑的7B SSM混合模型,在同等规模下性能媲美领先的开源模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 Mamba架构 混合模型 长序列建模 高效推理
📋 核心要点
- 现有Transformer模型在长序列生成时面临推理速度慢、内存需求大的挑战。
- Zamba创新性地结合Mamba骨干网络和共享注意力模块,在参数量有限的情况下兼顾效率和性能。
- Zamba在1T tokens上训练,并在高质量数据集上进行退火,性能优于同等规模的非Transformer模型。
📝 摘要(中文)
本技术报告介绍了一种新型的7B SSM-Transformer混合模型Zamba,它在同等规模下实现了与领先的开源模型相媲美的性能。Zamba在来自公开数据集的1T tokens上进行训练,是目前该规模下最好的非Transformer模型。Zamba首创了一种独特的架构,将Mamba骨干网络与单个共享注意力模块相结合,从而以最小的参数成本获得了注意力的优势。由于其架构,Zamba在推理速度上明显快于同类Transformer模型,并且在生成长序列时需要的内存也大大减少。Zamba的预训练分为两个阶段:第一阶段基于现有的网络数据集,而第二阶段包括在高质量的指令和合成数据集上退火模型,其特点是学习率快速衰减。我们开源了Zamba的权重和所有检查点,包括第一阶段和退火阶段。
🔬 方法详解
问题定义:现有的大型语言模型,特别是Transformer模型,在处理长序列时面临计算效率和内存消耗的瓶颈。Transformer的注意力机制复杂度是序列长度的平方级别,导致推理速度慢,并且需要大量的内存来存储中间激活值。因此,如何设计一种既能保持高性能,又能降低计算和内存开销的模型是一个关键问题。
核心思路:Zamba的核心思路是利用State Space Model (SSM),特别是Mamba架构,来替代Transformer中的自注意力机制,从而降低计算复杂度。同时,为了弥补SSM在某些任务上的不足,Zamba引入了一个共享的注意力模块,以增强模型的全局上下文理解能力。这种混合架构旨在结合两者的优点,实现高性能和高效率。
技术框架:Zamba的整体架构包括一个Mamba骨干网络和一个共享注意力模块。Mamba骨干网络负责处理序列中的局部信息,而共享注意力模块则负责捕捉全局依赖关系。模型首先通过Mamba层进行处理,然后将Mamba层的输出输入到共享注意力模块中。最后,将注意力模块的输出与Mamba层的输出进行融合,得到最终的表示。Zamba的训练分为两个阶段:预训练阶段和退火阶段。预训练阶段使用大规模的Web数据集,退火阶段使用高质量的指令和合成数据集,并采用快速学习率衰减策略。
关键创新:Zamba的关键创新在于其混合架构,它将Mamba的效率与注意力的全局上下文理解能力相结合。与纯Transformer模型相比,Zamba在推理速度和内存消耗方面具有显著优势。与纯SSM模型相比,Zamba通过共享注意力模块增强了模型的性能。此外,Zamba的训练策略也具有创新性,通过退火阶段的微调,进一步提升了模型的性能。
关键设计:Zamba的关键设计包括Mamba层的具体参数设置、共享注意力模块的结构、以及训练过程中的学习率衰减策略。共享注意力模块采用多头注意力机制,头数和维度需要仔细调整以平衡性能和计算成本。退火阶段的学习率衰减采用余弦退火策略,以确保模型能够稳定地收敛到最优解。损失函数采用标准的交叉熵损失函数。
🖼️ 关键图片
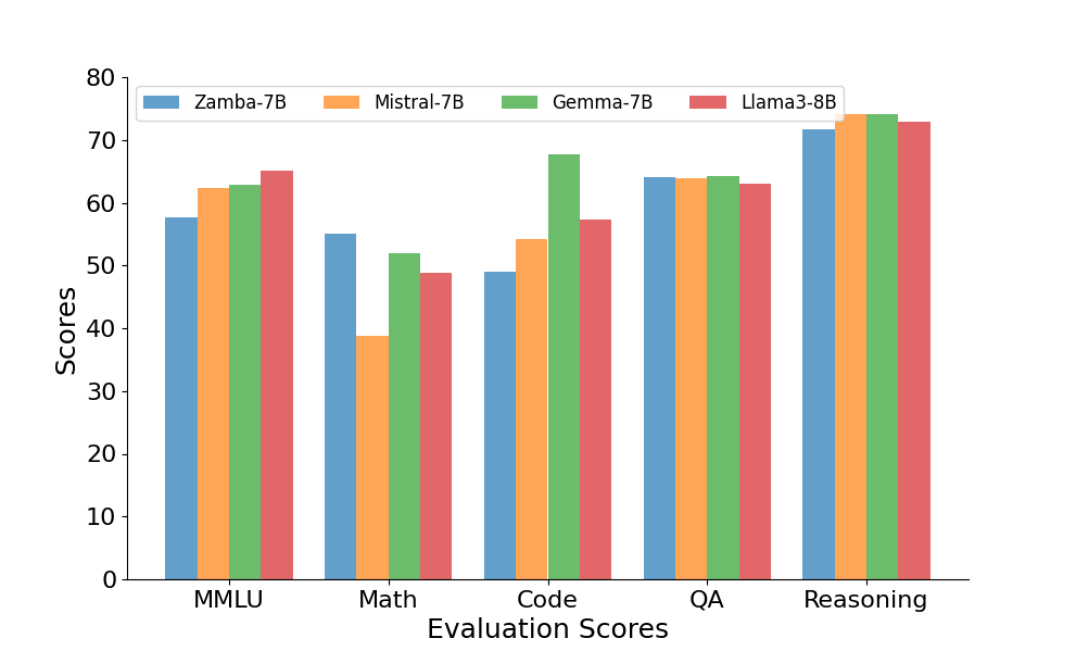


📊 实验亮点
Zamba在与同等规模的开源模型进行比较时,取得了具有竞争力的性能。实验结果表明,Zamba在推理速度上明显快于同类Transformer模型,并且在生成长序列时需要的内存也大大减少。Zamba是目前该规模下最好的非Transformer模型。开源的权重和检查点使得研究人员可以轻松地复现和扩展Zamba。
🎯 应用场景
Zamba模型具有广泛的应用前景,包括自然语言处理、代码生成、时间序列预测等领域。由于其高效的推理速度和低内存消耗,Zamba特别适合于部署在资源受限的设备上,如移动设备和嵌入式系统。此外,Zamba还可以用于构建更大规模的语言模型,从而进一步提升模型的性能。
📄 摘要(原文)
In this technical report, we present Zamba, a novel 7B SSM-transformer hybrid model which achieves competitive performance against leading open-weight models at a comparable scale. Zamba is trained on 1T tokens from openly available datasets and is the best non-transformer model at this scale. Zamba pioneers a unique architecture combining a Mamba backbone with a single shared attention module, thus obtaining the benefits of attention at minimal parameter cost. Due to its architecture, Zamba is significantly faster at inference than comparable transformer models and requires substantially less memory for generation of long sequences. Zamba is pretrained in two phases: the first phase is based on existing web datasets, while the second one consists of annealing the model over high-quality instruct and synthetic datasets, and is characterized by a rapid learning rate decay. We open-source the weights and all checkpoints for Zamba, through both phase 1 and annealing phases.