SpinQuant: LLM quantization with learned rotations
作者: Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, Tijmen Blankevoort
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2024-05-26 (更新: 2025-02-20)
备注: ICLR 2025
🔗 代码/项目: GITHUB
💡 一句话要点
SpinQuant:通过学习旋转矩阵实现LLM量化,显著提升零样本推理精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型量化 后训练量化 旋转矩阵 异常值消除 零样本推理
📋 核心要点
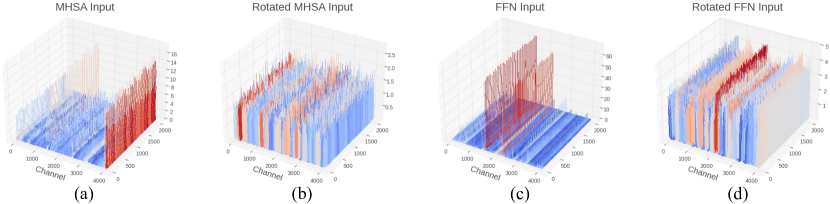
- 现有PTQ方法在量化LLM时,由于异常值的存在,容易产生较大的量化误差,导致精度下降。
- SpinQuant通过引入可学习的旋转矩阵,在不改变全精度模型输出的前提下,优化量化后的网络精度。
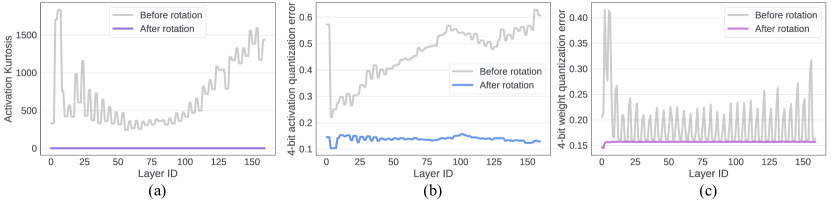
- 实验结果表明,SpinQuant在4比特量化下,显著缩小了与全精度模型的精度差距,优于现有PTQ和基于随机旋转的方法。
📝 摘要(中文)
后训练量化(PTQ)技术应用于权重、激活和KV缓存,可以显著降低大型语言模型(LLM)的内存使用、延迟和功耗,但当存在异常值时,可能会导致较大的量化误差。旋转激活或权重矩阵有助于消除异常值,从而有利于量化。本文确定了一系列适用的旋转参数化方法,这些方法在全精度Transformer架构中产生相同的输出,同时提高了量化精度。此外,我们发现一些随机旋转比其他旋转产生更好的量化效果,在下游零样本推理性能方面差异高达13个点。因此,我们提出了一种新颖的方法SpinQuant,它结合了学习到的旋转矩阵,以实现最佳的量化网络精度。通过对权重、激活和KV缓存进行4比特量化,SpinQuant将LLaMA-2 7B模型在零样本推理任务上的精度差距缩小到仅2.9个点,超过LLM-QAT 19.1个点,超过SmoothQuant 25.0个点。此外,SpinQuant也优于同期工作QuaRot,后者应用随机旋转来消除异常值。特别是在难以量化的LLaMA-3 8B模型上,SpinQuant相对于QuaRot,将与全精度的差距缩小了高达45.1%。代码可在https://github.com/facebookresearch/SpinQuant获取。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)量化过程中,由于激活值或权重中存在异常值,导致量化精度显著下降的问题。现有的后训练量化(PTQ)方法难以有效处理这些异常值,从而限制了LLM在资源受限设备上的部署。
核心思路:论文的核心思路是通过引入可学习的旋转矩阵,对激活值或权重进行旋转变换,从而将异常值分散或消除,使得量化过程更加友好。这种旋转变换被设计为在全精度模型中保持输出不变,因此不会影响模型的原始性能。通过学习最优的旋转矩阵,可以最大程度地提高量化后的模型精度。
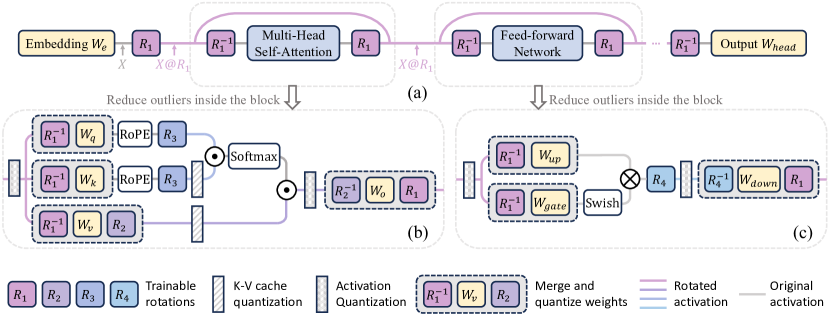
技术框架:SpinQuant的技术框架主要包括以下几个步骤:1) 选择合适的旋转参数化方法,确保旋转变换在全精度下不改变模型输出;2) 初始化旋转矩阵,可以使用随机旋转或预训练的旋转矩阵;3) 使用少量校准数据,通过优化算法(如梯度下降)学习最优的旋转矩阵;4) 使用学习到的旋转矩阵对激活值或权重进行旋转变换;5) 对旋转后的激活值或权重进行量化。
关键创新:SpinQuant的关键创新在于引入了可学习的旋转矩阵,并设计了一种优化算法来学习最优的旋转矩阵。与现有方法(如SmoothQuant)相比,SpinQuant能够更有效地消除异常值,从而提高量化精度。与基于随机旋转的方法(如QuaRot)相比,SpinQuant通过学习到的旋转矩阵,能够获得更好的量化性能。
关键设计:论文中关键的设计包括:1) 选择合适的旋转参数化方法,例如Givens旋转或Householder变换,以确保旋转变换在全精度下不改变模型输出;2) 设计损失函数,用于指导旋转矩阵的学习,例如最小化量化误差或最大化量化后的模型性能;3) 选择合适的优化算法,例如Adam或SGD,来学习最优的旋转矩阵;4) 确定旋转矩阵的应用位置,例如只对激活值进行旋转,或同时对激活值和权重进行旋转。
🖼️ 关键图片
📊 实验亮点
SpinQuant在LLaMA-2 7B模型上,通过4比特量化,将零样本推理任务上的精度差距缩小到仅2.9个点,超过LLM-QAT 19.1个点,超过SmoothQuant 25.0个点。在LLaMA-3 8B模型上,SpinQuant相对于QuaRot,将与全精度的差距缩小了高达45.1%。这些结果表明,SpinQuant能够显著提高量化LLM的精度。
🎯 应用场景
SpinQuant具有广泛的应用前景,可用于在资源受限的设备上部署大型语言模型,例如移动设备、嵌入式系统和边缘计算设备。通过降低LLM的内存占用、延迟和功耗,SpinQuant可以使这些设备能够运行更复杂的AI应用,例如智能助手、机器翻译和自然语言处理。
📄 摘要(原文)
Post-training quantization (PTQ) techniques applied to weights, activations, and the KV cache greatly reduce memory usage, latency, and power consumption of Large Language Models (LLMs), but may lead to large quantization errors when outliers are present. Rotating activation or weight matrices helps remove outliers and benefits quantization. In this work, we identify a collection of applicable rotation parameterizations that lead to identical outputs in full-precision Transformer architectures while enhancing quantization accuracy. In addition, we find that some random rotations lead to much better quantization than others, with an up to 13 points difference in downstream zero-shot reasoning performance. As a result, we propose SpinQuant, a novel approach that incorporates learned rotation matrices for optimal quantized network accuracy. With 4-bit quantization of weight, activation, and KV-cache, SpinQuant narrows the accuracy gap on zero-shot reasoning tasks with full precision to merely 2.9 points on the LLaMA-2 7B model, surpassing LLM-QAT by 19.1 points and SmoothQuant by 25.0 points. Furthermore, SpinQuant also outperforms concurrent work QuaRot, which applies random rotations to remove outliers. In particular, for LLaMA-3 8B models that are hard to quantize, SpinQuant reduces the gap to full precision by up to 45.1% relative to QuaRot. Code is available at https://github.com/facebookresearch/SpinQuant.