Basis Selection: Low-Rank Decomposition of Pretrained Large Language Models for Target Applications
作者: Yang Li, Daniel Agyei Asante, Changsheng Zhao, Ernie Chang, Yangyang Shi, Vikas Chandra
分类: cs.LG, cs.AR, cs.CL
发布日期: 2024-05-24 (更新: 2025-12-19)
备注: Transactions on Machine Learning Research (TMLR), 2025
💡 一句话要点
提出基于基选择的低秩分解方法,用于压缩LLM以适应特定应用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型压缩 低秩分解 基选择 模型优化 资源受限设备 数学推理 代码生成
📋 核心要点
- 现有LLM计算开销大,难以在资源受限设备上部署,且通用预训练模型包含大量应用无关的冗余参数。
- 论文提出基于基选择的低秩分解方法,通过识别并移除冗余基,保留关键基并添加新基来压缩模型。
- 实验表明,该方法在压缩Llama 2模型的同时,在数学推理和代码生成等任务上保持了与现有方法相当的精度。
📝 摘要(中文)
大型语言模型(LLM)显著提升了各种应用的性能,但其计算密集和高能耗的特性限制了它们在资源受限设备(如个人电脑和移动/可穿戴设备)上的部署,并在云服务器等资源丰富的环境中导致了巨大的推理成本。为了扩展LLM的使用,我们提出了一种低秩分解方法,旨在有效地压缩这些模型,并使其适应特定应用的需求。我们观察到,在通用数据集上预训练的LLM包含许多特定应用不需要的冗余组件。我们的方法专注于识别和移除这些冗余部分,仅保留目标应用所需的元素。具体来说,我们将LLM的权重矩阵表示为基组件的线性组合。然后,我们剪枝不相关的基,并使用有益于特定应用的新基来增强模型。在Llama 2-7b和-13B模型上进行的数学推理和代码生成等目标应用的深度压缩结果表明,我们的方法显著降低了模型大小,同时保持了与最先进的低秩压缩技术相当的准确性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)计算量大、能耗高,难以在资源受限设备上部署的问题。现有方法在压缩LLM时,通常没有充分考虑特定应用的需求,导致压缩后的模型性能下降或压缩率不足。通用预训练的LLM包含大量与特定任务无关的冗余参数,这些参数增加了计算负担,却对目标任务的性能提升贡献不大。
核心思路:论文的核心思路是将LLM的权重矩阵分解为一组基的线性组合,然后通过选择合适的基来压缩模型。具体来说,该方法首先识别并移除对目标应用不重要的冗余基,然后根据需要添加新的基,以增强模型在特定应用上的性能。这种方法能够有效地去除冗余参数,同时保留或增强模型在目标应用上的能力。
技术框架:该方法主要包含以下几个阶段:1) 基分解:将LLM的权重矩阵分解为一组基的线性组合。2) 基选择:评估每个基对目标应用的重要性,并移除不重要的基。3) 基增强:根据目标应用的需求,添加新的基以提升模型性能。4) 模型重构:使用选择和增强后的基重构压缩后的LLM。
关键创新:该方法最重要的创新点在于其基于基选择的压缩策略。与传统的低秩分解方法不同,该方法能够根据目标应用的需求,自适应地选择和增强基,从而实现更有效的模型压缩和性能提升。此外,该方法还能够识别并移除LLM中的冗余参数,从而降低计算开销和能耗。
关键设计:论文中关键的设计包括:1) 如何选择合适的基分解方法(例如SVD)。2) 如何评估每个基对目标应用的重要性(例如基于梯度或激活值的分析)。3) 如何确定需要移除的基的数量和需要添加的新基的数量。4) 如何设计新的基以增强模型在特定应用上的性能。这些设计细节将直接影响压缩后的模型的性能和压缩率。
🖼️ 关键图片


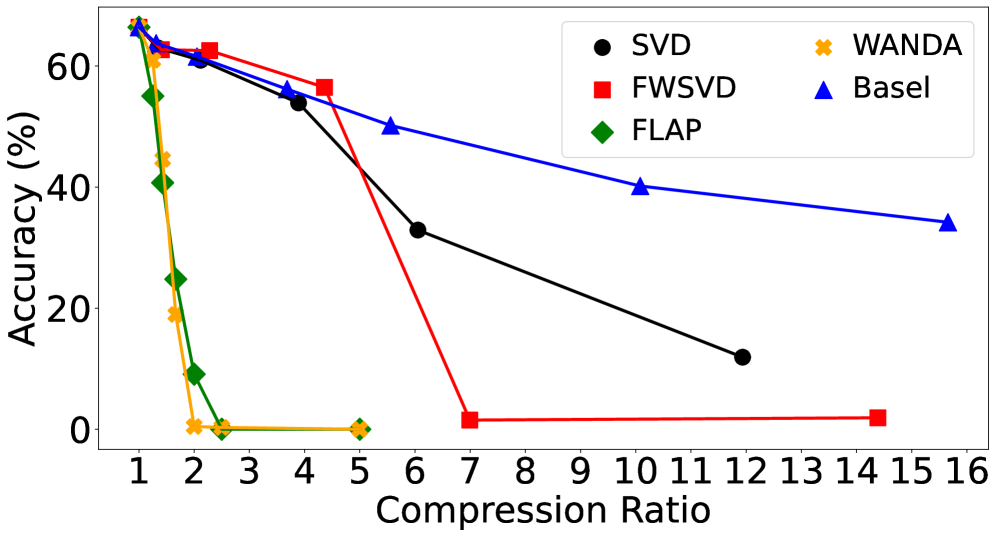
📊 实验亮点
论文在Llama 2-7b和-13B模型上进行了实验,针对数学推理和代码生成等任务,结果表明该方法能够在显著降低模型大小的同时,保持与最先进的低秩压缩技术相当的准确性。具体的性能数据和提升幅度在论文中进行了详细的展示,证明了该方法的有效性和优越性。
🎯 应用场景
该研究成果可广泛应用于各种需要部署大型语言模型的场景,尤其是在资源受限的环境中,如移动设备、嵌入式系统和边缘计算设备。通过压缩LLM,可以降低推理成本,提高响应速度,并扩展LLM的应用范围。例如,可以将压缩后的LLM部署在智能手机上,实现离线翻译、语音助手等功能。此外,该方法还可以应用于云计算领域,降低LLM的部署和维护成本,提高资源利用率。
📄 摘要(原文)
Large language models (LLMs) significantly enhance the performance of various applications, but they are computationally intensive and energy-demanding. This makes it challenging to deploy them on devices with limited resources, such as personal computers and mobile/wearable devices, and results in substantial inference costs in resource-rich environments like cloud servers. To extend the use of LLMs, we introduce a low-rank decomposition approach to effectively compress these models, tailored to the requirements of specific applications. We observe that LLMs pretrained on general datasets contain many redundant components not needed for particular applications. Our method focuses on identifying and removing these redundant parts, retaining only the necessary elements for the target applications. Specifically, we represent the weight matrices of LLMs as a linear combination of base components. We then prune the irrelevant bases and enhance the model with new bases beneficial for specific applications. Deep compression results on the Llama 2-7b and -13B models, conducted on target applications including mathematical reasoning and code generation, show that our method significantly reduces model size while maintaining comparable accuracy to state-of-the-art low-rank compression techniques.