Privileged Sensing Scaffolds Reinforcement Learning
作者: Edward S. Hu, James Springer, Oleh Rybkin, Dinesh Jayaraman
分类: cs.LG, cs.AI, cs.RO
发布日期: 2024-05-23
备注: ICLR 2024 Spotlight version
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出Scaffolder,利用特权感知提升强化学习在机器人任务中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 特权学习 机器人学习 感知脚手架 模拟训练
📋 核心要点
- 现有强化学习方法在复杂机器人任务中,难以有效利用训练时可用的、但部署时不可用的特权信息。
- 论文提出Scaffolder框架,通过在训练阶段利用特权传感器信息辅助评论家、世界模型等组件,提升策略学习效率。
- 在S3机器人任务套件上的实验表明,Scaffolder显著优于现有方法,甚至可媲美测试时具备特权信息的策略。
📝 摘要(中文)
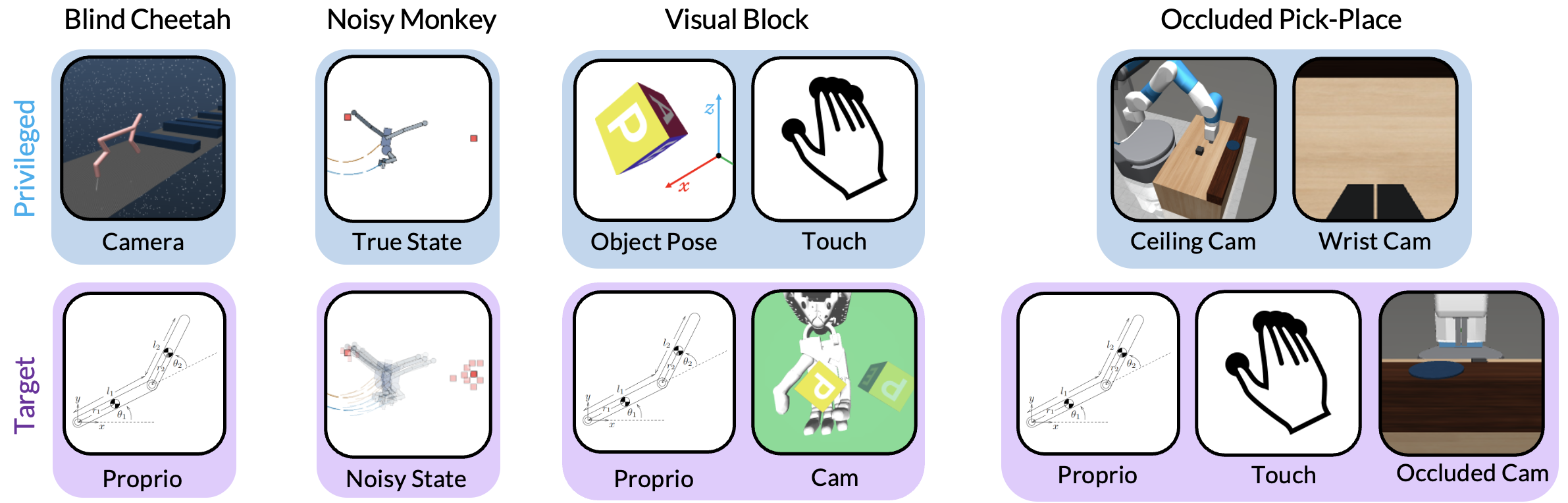
本文探讨了“感知脚手架”现象,即对于新手学习者有益的观察流,在掌握技能后可能不再需要。作者针对训练人工代理提出了这种感知脚手架设置。例如,机器人手臂可能只需要一个低成本、鲁棒的通用摄像头进行部署;但如果在训练时能够访问信息丰富但昂贵且笨重的运动捕捉设备或脆弱的触觉传感器,其性能可能会得到提高。为此,作者提出了一种名为“Scaffolder”的强化学习方法,该方法有效地利用评论家、世界模型、奖励估计器等辅助组件中的特权感知(仅在训练时使用)来改进目标策略。为了评估感知脚手架代理,作者设计了一个新的“S3”套件,其中包含十个不同的模拟机器人任务,探索了各种实际的传感器设置。代理必须使用特权摄像头感知来训练盲人跨栏运动员,使用特权主动视觉感知来帮助机器人手臂克服视觉遮挡,使用特权触摸传感器来训练机器人手等等。Scaffolder 轻松超越了相关的先前基线,并且通常甚至可以与在测试时可以访问特权传感器的策略相媲美。
🔬 方法详解
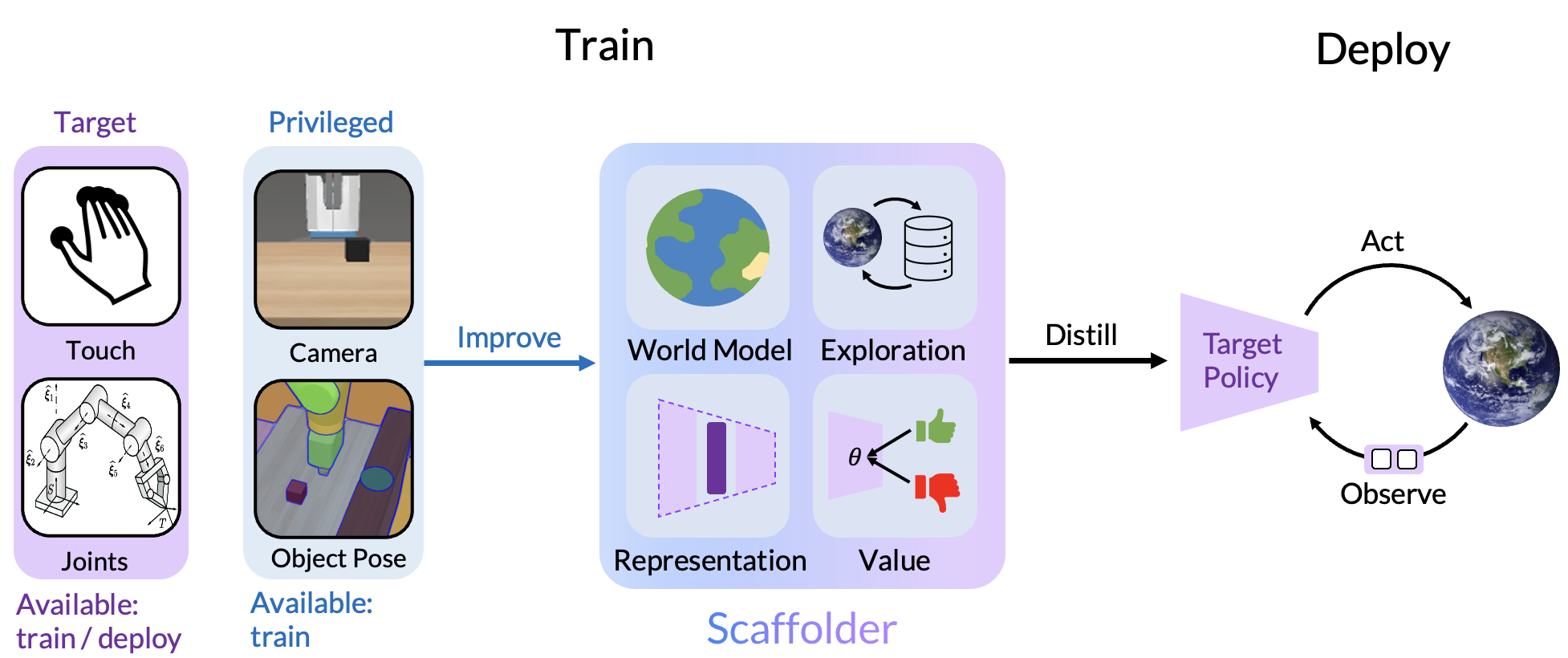
问题定义:论文旨在解决强化学习中如何有效利用训练时可用的特权信息(privileged information)的问题。在机器人学习中,例如,训练时可以使用高精度的运动捕捉系统或触觉传感器,但实际部署时可能只能使用低成本的摄像头。现有方法难以充分利用这些训练时可用的特权信息来提升最终策略的性能。
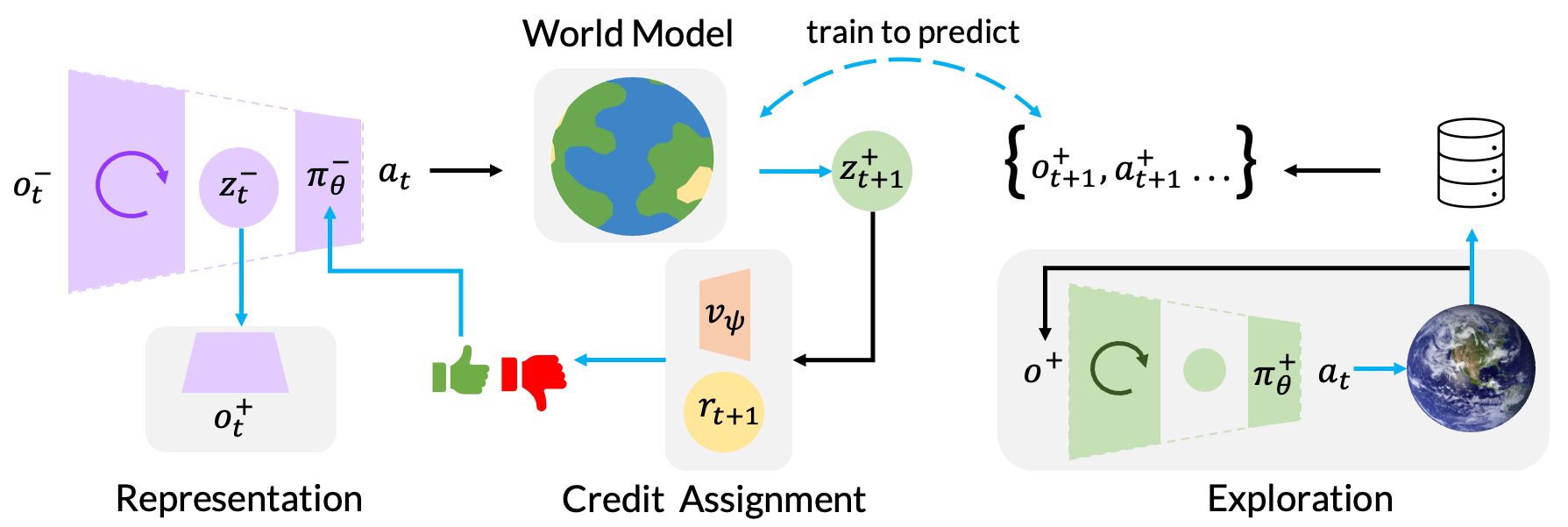
核心思路:核心思路是利用特权信息来辅助训练过程中的关键组件,如评论家(critic)、世界模型(world model)和奖励估计器(reward estimator)。这些组件仅在训练阶段使用,因此可以充分利用特权信息来提供更准确的反馈和指导,从而加速策略学习并提升最终性能。在部署阶段,策略仅依赖于部署时可用的传感器信息。
技术框架:Scaffolder框架包含以下主要模块:1) 策略网络(Policy Network):根据部署时可用的传感器信息生成动作。2) 评论家网络(Critic Network):利用特权信息评估策略生成的动作的价值。3) 世界模型(World Model):利用特权信息预测环境的未来状态。4) 奖励估计器(Reward Estimator):利用特权信息估计奖励函数。这些模块在训练阶段协同工作,利用特权信息来提升策略学习的效率和性能。在部署阶段,只有策略网络被使用。
关键创新:关键创新在于将特权信息融入到强化学习的辅助组件中,而不是直接用于策略学习。这种方法避免了策略对特权信息的过度依赖,使得训练出的策略能够在部署时仅依赖于有限的传感器信息。此外,Scaffolder框架具有通用性,可以应用于不同的强化学习算法和机器人任务。
关键设计:Scaffolder的具体实现细节取决于所使用的强化学习算法和任务。例如,可以使用不同的神经网络结构来实现策略网络、评论家网络、世界模型和奖励估计器。损失函数的设计也至关重要,需要确保特权信息能够有效地指导策略学习。此外,还需要仔细调整超参数,以获得最佳的性能。论文中提出的S3套件包含十个不同的模拟机器人任务,涵盖了各种实际的传感器设置,为评估感知脚手架代理提供了一个全面的平台。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Scaffolder在S3机器人任务套件上显著优于现有的强化学习方法。例如,在某些任务中,Scaffolder的性能甚至可以与在测试时可以访问特权传感器的策略相媲美。这表明Scaffolder能够有效地利用特权信息来提升策略学习的效率和性能。
🎯 应用场景
该研究成果可广泛应用于机器人学习领域,尤其是在训练数据丰富但部署环境受限的场景下。例如,可以使用高精度模拟器或昂贵的传感器进行训练,然后将训练好的策略部署到资源受限的机器人平台上。这有助于降低机器人开发的成本和难度,加速机器人在各个领域的应用。
📄 摘要(原文)
We need to look at our shoelaces as we first learn to tie them but having mastered this skill, can do it from touch alone. We call this phenomenon "sensory scaffolding": observation streams that are not needed by a master might yet aid a novice learner. We consider such sensory scaffolding setups for training artificial agents. For example, a robot arm may need to be deployed with just a low-cost, robust, general-purpose camera; yet its performance may improve by having privileged training-time-only access to informative albeit expensive and unwieldy motion capture rigs or fragile tactile sensors. For these settings, we propose "Scaffolder", a reinforcement learning approach which effectively exploits privileged sensing in critics, world models, reward estimators, and other such auxiliary components that are only used at training time, to improve the target policy. For evaluating sensory scaffolding agents, we design a new "S3" suite of ten diverse simulated robotic tasks that explore a wide range of practical sensor setups. Agents must use privileged camera sensing to train blind hurdlers, privileged active visual perception to help robot arms overcome visual occlusions, privileged touch sensors to train robot hands, and more. Scaffolder easily outperforms relevant prior baselines and frequently performs comparably even to policies that have test-time access to the privileged sensors. Website: https://penn-pal-lab.github.io/scaffolder/