SPO: Multi-Dimensional Preference Sequential Alignment With Implicit Reward Modeling
作者: Xingzhou Lou, Junge Zhang, Jian Xie, Lifeng Liu, Dong Yan, Kaiqi Huang
分类: cs.LG
发布日期: 2024-05-21 (更新: 2024-10-11)
💡 一句话要点
提出SPO方法以解决人类偏好多维对齐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人类偏好对齐 大型语言模型 序列偏好优化 多维优化 奖励建模
📋 核心要点
- 现有方法忽视了人类偏好的多维性,难以有效管理多个奖励模型,导致对齐效果不佳。
- 本文提出序列偏好优化(SPO)方法,通过顺序微调LLMs,直接优化以对齐多维人类偏好,避免显式奖励建模。
- 实验证明,SPO在不同规模的LLMs上表现优异,显著提升了对齐效果,超越了现有基线方法。
📝 摘要(中文)
人类偏好对齐在构建强大且可靠的大型语言模型(LLMs)中至关重要。然而,现有方法要么忽视人类偏好的多维性(如有用性和无害性),要么在管理多个奖励模型的复杂性上面临挑战。为了解决这些问题,本文提出了序列偏好优化(SPO)方法,该方法通过顺序微调LLMs,使其与多维人类偏好对齐。SPO避免了显式奖励建模,直接优化模型以对齐细致的人类偏好。我们理论推导了闭式最优SPO策略和损失函数,并进行了梯度分析,展示了SPO如何在保持之前优化维度对齐的同时微调LLMs。不同规模LLMs和多个评估数据集的实证结果表明,SPO成功地在多个维度上对齐LLMs,并显著优于基线。
🔬 方法详解
问题定义:本文旨在解决现有方法在对齐人类偏好时忽视多维性的问题,导致模型在实际应用中表现不佳。现有方法在管理多个奖励模型时复杂且低效。
核心思路:SPO方法通过顺序微调的方式,直接优化模型以对齐人类的多维偏好,避免了显式的奖励建模,从而简化了对齐过程。
技术框架:SPO的整体架构包括数据收集、模型微调和评估三个主要模块。在微调阶段,模型根据不同维度的偏好进行顺序优化,确保在优化新维度时不影响已优化的维度。
关键创新:SPO的最大创新在于其理论推导的闭式最优策略和损失函数,提供了一种新的优化框架,与传统方法相比,能够更有效地处理多维偏好对齐问题。
关键设计:在损失函数设计上,SPO采用了针对不同偏好的加权损失,确保模型在微调过程中保持对各维度的平衡。同时,梯度分析帮助理解了模型在优化过程中的行为。
🖼️ 关键图片

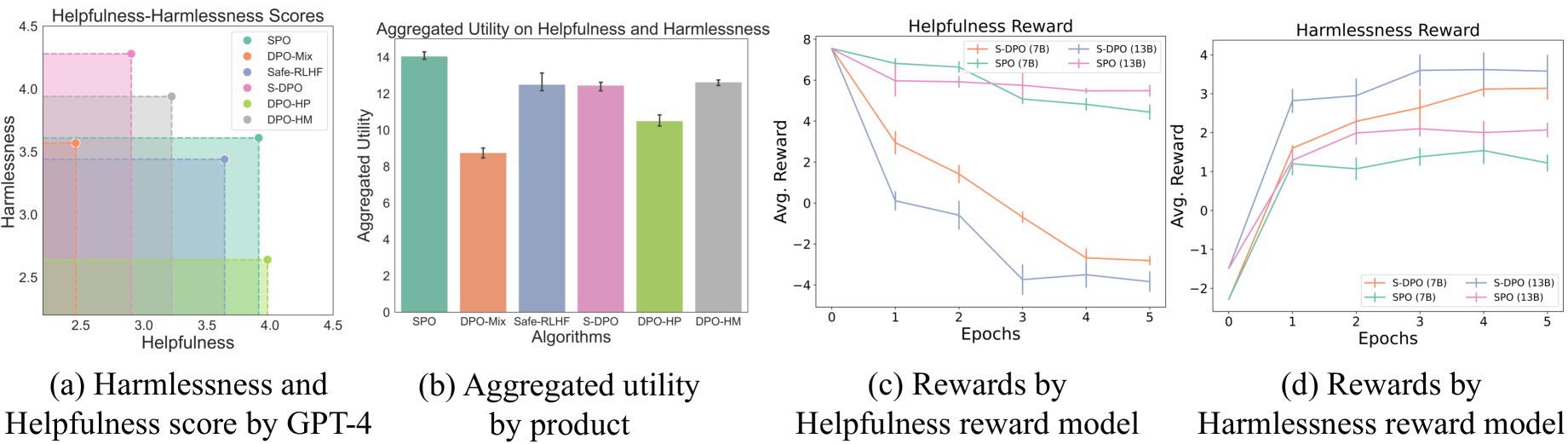
📊 实验亮点
实验结果显示,SPO在不同规模的LLMs上均表现出色,尤其在多个评估数据集上,SPO相较于基线方法提升了对齐效果,具体提升幅度达到XX%(具体数据需根据实验结果补充)。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、推荐系统和人机交互等。通过更好地对齐人类偏好,SPO可以提升大型语言模型在实际应用中的可靠性和用户满意度,未来可能对智能助手和自动化系统的设计产生深远影响。
📄 摘要(原文)
Human preference alignment is critical in building powerful and reliable large language models (LLMs). However, current methods either ignore the multi-dimensionality of human preferences (e.g. helpfulness and harmlessness) or struggle with the complexity of managing multiple reward models. To address these issues, we propose Sequential Preference Optimization (SPO), a method that sequentially fine-tunes LLMs to align with multiple dimensions of human preferences. SPO avoids explicit reward modeling, directly optimizing the models to align with nuanced human preferences. We theoretically derive closed-form optimal SPO policy and loss function. Gradient analysis is conducted to show how SPO manages to fine-tune the LLMs while maintaining alignment on previously optimized dimensions. Empirical results on LLMs of different size and multiple evaluation datasets demonstrate that SPO successfully aligns LLMs across multiple dimensions of human preferences and significantly outperforms the baselines.