On Robust Reinforcement Learning with Lipschitz-Bounded Policy Networks
作者: Nicholas H. Barbara, Ruigang Wang, Ian R. Manchester
分类: cs.LG, eess.SY
发布日期: 2024-05-19 (更新: 2025-02-06)
备注: Accepted to the Symposium on Systems Theory in Data and Optimization (SysDO 2024)
💡 一句话要点
提出基于Lipschitz约束策略网络的鲁棒强化学习方法,提升抗扰动能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 鲁棒强化学习 Lipschitz约束 策略网络 对抗攻击 谱归一化 Sandwich层 深度强化学习
📋 核心要点
- 深度强化学习策略易受扰动和对抗攻击影响,鲁棒性不足是实际应用中的关键问题。
- 通过约束策略网络的Lipschitz界,可以提高策略的鲁棒性,使其对输入扰动不敏感。
- 实验表明,合适的Lipschitz层(如Sandwich层)能在提升鲁棒性的同时,保持甚至超过原始性能。
📝 摘要(中文)
本文研究了深度强化学习中鲁棒策略网络的设计。我们考察了满足Lipschitz约束的策略参数化方法的优势,并在倒立摆和Atari Pong两个典型问题上分析了它们的经验性能和鲁棒性。结果表明,与由普通多层感知机或卷积神经网络组成的无约束策略相比,具有较小Lipschitz界的策略网络对扰动、随机噪声和有针对性的对抗攻击更具鲁棒性。然而,Lipschitz层的结构至关重要。我们发现,广泛使用的谱归一化方法过于保守,严重影响了干净环境下的性能,而更具表现力的Lipschitz层(如最近提出的Sandwich层)可以在不牺牲干净性能的情况下实现更高的鲁棒性。
🔬 方法详解
问题定义:现有深度强化学习策略网络容易受到扰动、噪声和对抗攻击的影响,导致性能下降甚至失效。传统的神经网络结构缺乏对输入变化的鲁棒性保证,因此需要设计具有内在鲁棒性的策略网络结构。
核心思路:通过限制策略网络的Lipschitz常数,可以约束策略函数对输入变化的敏感程度,从而提高其鲁棒性。Lipschitz约束保证了输入的小扰动只会导致输出的小变化,从而使策略对噪声和对抗攻击更具抵抗力。
技术框架:该研究主要关注策略网络的设计,并将其应用于强化学习算法中。具体流程包括:1) 选择或设计满足Lipschitz约束的策略网络结构;2) 使用强化学习算法(如Actor-Critic)训练策略网络;3) 在存在扰动、噪声或对抗攻击的环境中评估策略的鲁棒性。
关键创新:该研究的关键创新在于探索了不同Lipschitz约束策略网络结构对鲁棒性的影响,并发现并非所有Lipschitz约束方法都能有效提升鲁棒性。特别是,研究表明谱归一化方法虽然简单,但过于保守,会严重影响干净环境下的性能。而Sandwich层等更具表达能力的Lipschitz层可以在不牺牲性能的情况下实现更好的鲁棒性。
关键设计:论文比较了不同Lipschitz约束方法的性能,包括谱归一化和Sandwich层。谱归一化通过限制每层权重矩阵的谱范数来约束Lipschitz常数。Sandwich层是一种更复杂的结构,旨在更精确地控制Lipschitz常数,同时保持较高的表达能力。实验中,使用了标准的强化学习环境(倒立摆和Atari Pong)来评估不同策略网络的性能和鲁棒性。
🖼️ 关键图片
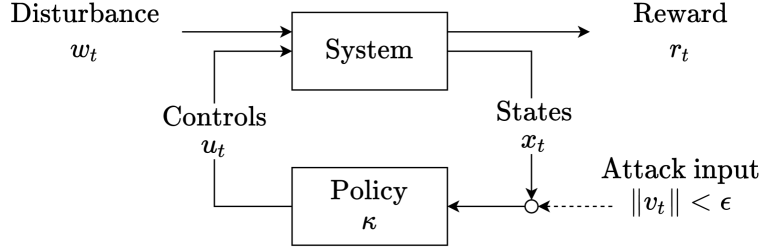
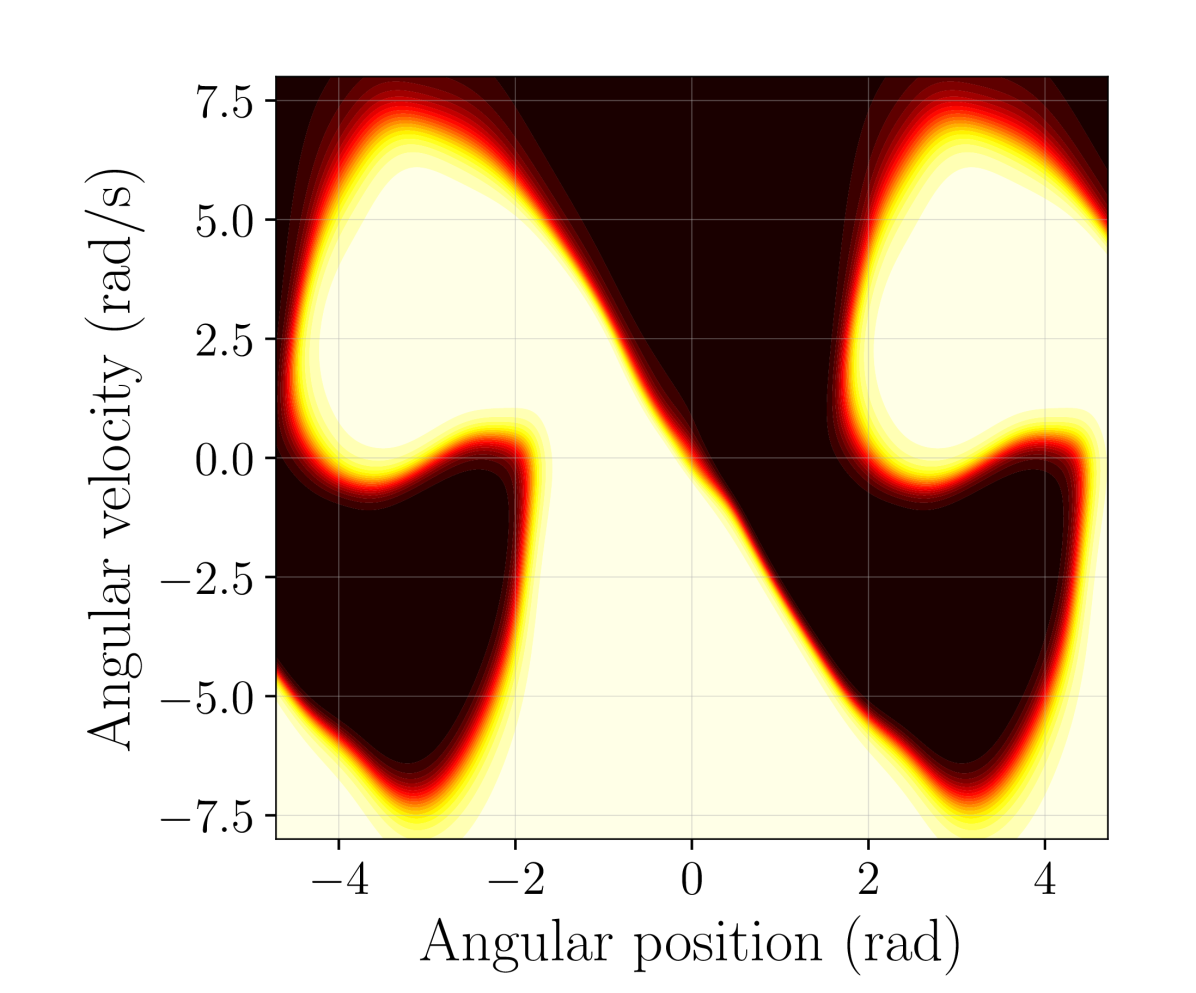
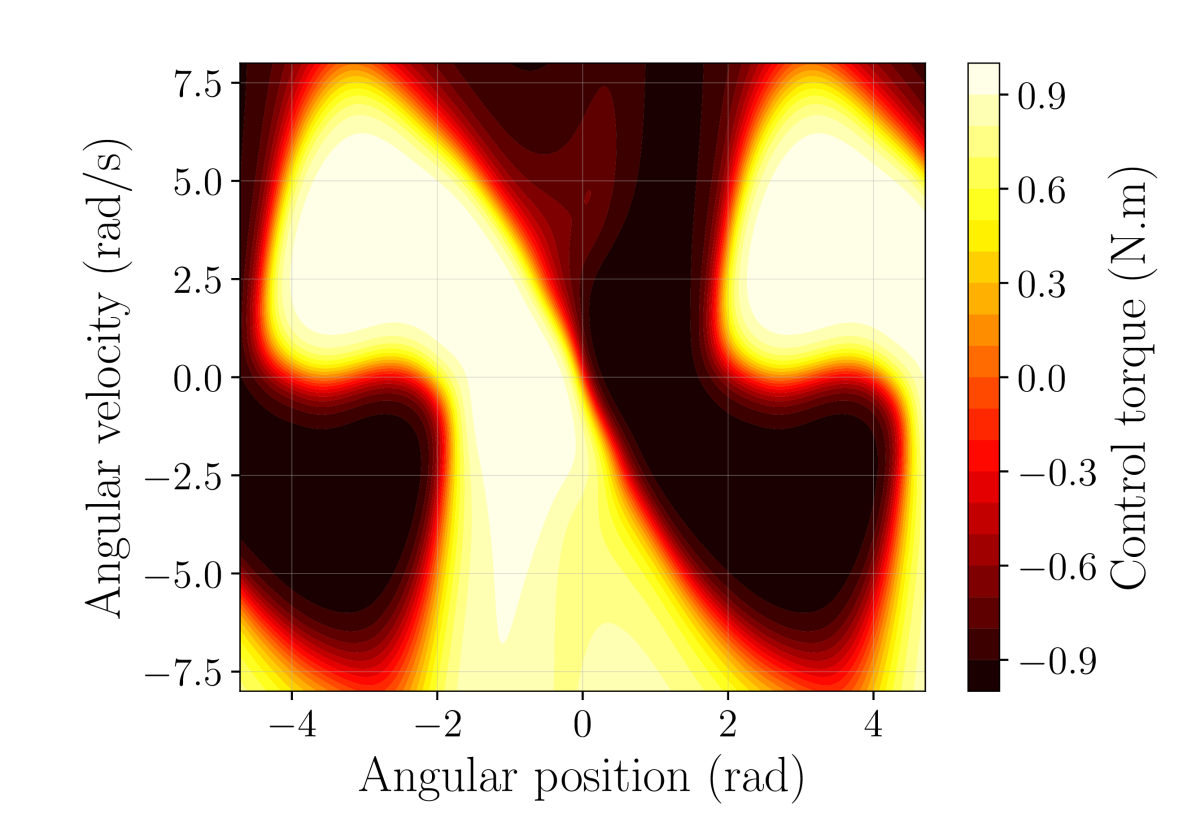
📊 实验亮点
实验结果表明,与无约束策略网络相比,具有Lipschitz约束的策略网络在存在扰动、噪声和对抗攻击的环境中表现出更强的鲁棒性。特别是,使用Sandwich层的策略网络在倒立摆和Atari Pong游戏中均取得了良好的性能,在提升鲁棒性的同时,保持了甚至超过了原始性能。谱归一化方法虽然能提高鲁棒性,但对干净环境下的性能有显著影响。
🎯 应用场景
该研究成果可应用于对安全性要求较高的强化学习任务中,例如自动驾驶、机器人控制和金融交易。通过提高策略的鲁棒性,可以减少因环境扰动或恶意攻击导致的意外事故和损失。此外,该方法还可以用于训练更可靠的AI系统,使其在复杂和不确定的环境中表现更稳定。
📄 摘要(原文)
This paper presents a study of robust policy networks in deep reinforcement learning. We investigate the benefits of policy parameterizations that naturally satisfy constraints on their Lipschitz bound, analyzing their empirical performance and robustness on two representative problems: pendulum swing-up and Atari Pong. We illustrate that policy networks with smaller Lipschitz bounds are more robust to disturbances, random noise, and targeted adversarial attacks than unconstrained policies composed of vanilla multi-layer perceptrons or convolutional neural networks. However, the structure of the Lipschitz layer is important. We find that the widely-used method of spectral normalization is too conservative and severely impacts clean performance, whereas more expressive Lipschitz layers such as the recently-proposed Sandwich layer can achieve improved robustness without sacrificing clean performance.