Towards Modular LLMs by Building and Reusing a Library of LoRAs
作者: Oleksiy Ostapenko, Zhan Su, Edoardo Maria Ponti, Laurent Charlin, Nicolas Le Roux, Matheus Pereira, Lucas Caccia, Alessandro Sordoni
分类: cs.LG, cs.CL
发布日期: 2024-05-18
💡 一句话要点
构建和复用LoRA库,实现模块化LLM并提升泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 LoRA 适配器库 模型聚类 零样本学习 任务泛化 模块化LLM
📋 核心要点
- 现有参数高效微调方法缺乏对适配器库的有效构建和复用机制,限制了模型在新任务上的泛化能力。
- 提出基于模型聚类(MBC)的适配器库构建方法,并设计零样本路由机制Arrow,实现适配器的动态选择和复用。
- 实验表明,基于MBC的适配器和Arrow路由在多个LLM上,针对各种保留任务,能够显著提升模型在新任务上的泛化性能。
📝 摘要(中文)
随着基础大型语言模型(LLM)的参数高效适配方法日益增多,研究如何复用已训练的适配器以提高新任务的性能变得至关重要。本文研究了如何利用多任务数据构建最佳适配器库,并设计了通过该库进行路由的技术,以实现零样本和监督任务泛化。我们对现有构建库的方法进行了基准测试,并引入了基于模型的聚类(MBC),该方法基于适配器参数的相似性对任务进行分组,从而间接优化多任务数据集上的迁移。为了复用该库,我们提出了一种新颖的零样本路由机制Arrow,该机制能够动态选择与新输入最相关的适配器,而无需重新训练。我们在多个LLM(如Phi-2和Mistral)上,针对各种保留任务进行了实验,验证了基于MBC的适配器和Arrow路由能够更好地泛化到新任务。我们朝着创建模块化、可适配的LLM迈出了重要一步,这些LLM可以匹配甚至优于传统的联合训练。
🔬 方法详解
问题定义:现有参数高效微调方法,如LoRA,虽然能有效适配LLM到特定任务,但缺乏有效的组织和复用机制。直接针对新任务进行微调成本高昂,且无法有效利用已有的知识。因此,如何构建一个可复用的适配器库,并根据新任务的需求动态选择合适的适配器,是亟待解决的问题。现有方法在构建适配器库时,往往忽略了任务之间的内在联系,导致适配器的选择效率低下。
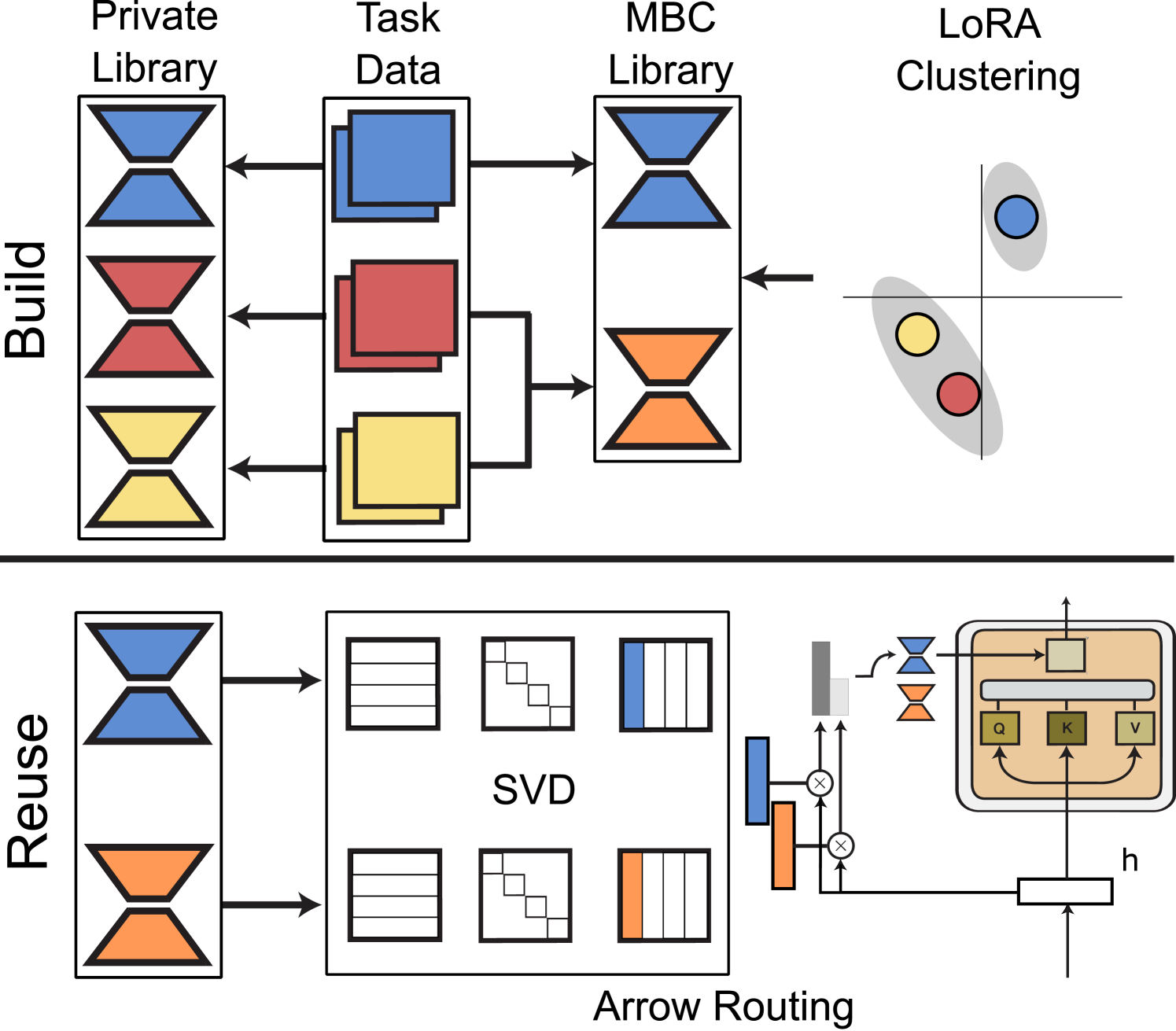
核心思路:本文的核心思路是构建一个模块化的LLM,通过构建和复用LoRA适配器库来实现。具体而言,首先利用多任务数据训练一系列LoRA适配器,然后使用基于模型的聚类(MBC)方法对任务进行分组,使得同一组内的任务具有相似的适配器参数。在推理阶段,利用提出的Arrow路由机制,根据输入样本的特征动态选择最相关的适配器组合,从而实现零样本或少样本的任务泛化。
技术框架:整体框架包含两个主要阶段:适配器库构建阶段和推理阶段。在适配器库构建阶段,首先使用多任务数据集对基础LLM进行LoRA微调,得到一系列适配器。然后,使用MBC算法对任务进行聚类,将相似的任务分配到同一组。在推理阶段,对于新的输入样本,Arrow路由机制会根据样本的特征,从适配器库中选择最相关的适配器组合,并将它们应用于基础LLM进行推理。
关键创新:本文的关键创新在于提出了基于模型聚类(MBC)的适配器库构建方法和Arrow零样本路由机制。MBC方法能够有效地发现任务之间的内在联系,从而构建更有效的适配器库。Arrow路由机制能够根据输入样本的特征动态选择适配器,避免了传统方法中需要手动选择或训练专门路由器的繁琐过程。
关键设计:MBC算法使用适配器参数的相似性作为聚类的依据,具体而言,计算不同任务的适配器参数之间的余弦相似度,并使用层次聚类算法将任务分组。Arrow路由机制使用一个轻量级的神经网络,根据输入样本的embedding向量预测适配器的权重,然后将这些权重应用于适配器参数,得到最终的预测结果。损失函数包括交叉熵损失和正则化项,用于鼓励适配器权重的稀疏性。
🖼️ 关键图片

📊 实验亮点
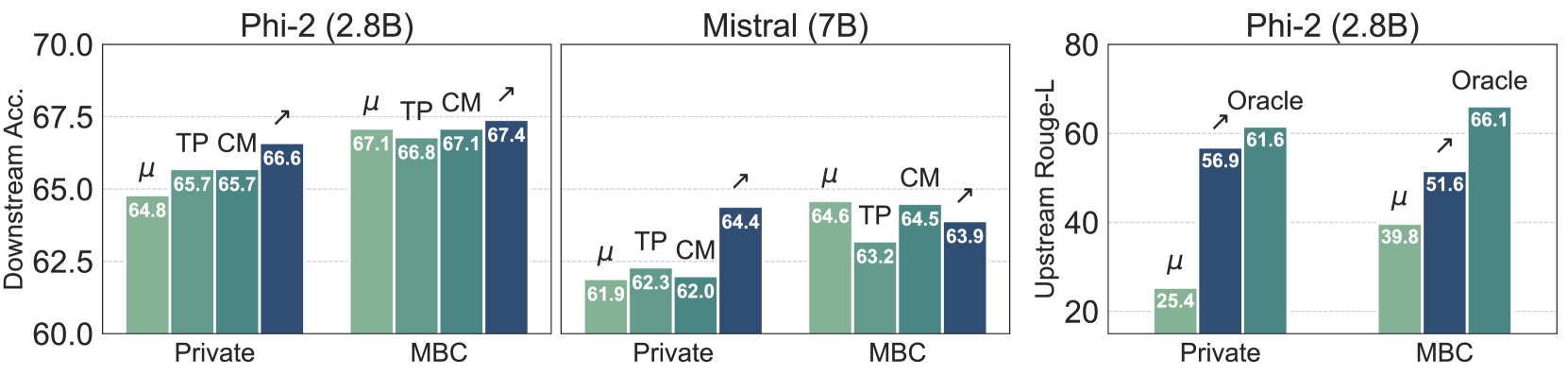
实验结果表明,基于MBC的适配器库和Arrow路由机制在多个LLM(如Phi-2和Mistral)上,针对各种保留任务,能够显著提升模型在新任务上的泛化性能。例如,在某些任务上,相比于传统的联合训练方法,该方法能够达到相近甚至更好的性能,同时显著降低了训练成本。
🎯 应用场景
该研究成果可应用于各种需要快速适应新任务的场景,例如智能客服、个性化推荐、自动翻译等。通过构建和复用适配器库,可以显著降低模型适配的成本,提高模型的泛化能力,并加速LLM在实际应用中的部署。
📄 摘要(原文)
The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.