Large Language Models in Wireless Application Design: In-Context Learning-enhanced Automatic Network Intrusion Detection
作者: Han Zhang, Akram Bin Sediq, Ali Afana, Melike Erol-Kantarci
分类: cs.LG, cs.AI, cs.CR
发布日期: 2024-05-17
💡 一句话要点
提出基于上下文学习增强的LLM框架,用于无线网络入侵检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 无线网络安全 入侵检测 上下文学习 GPT-4 自动化 网络流量分析
📋 核心要点
- 现有网络入侵检测方法在自动化和泛化能力方面存在不足,难以适应复杂多变的网络环境。
- 利用LLM强大的理解和推理能力,结合上下文学习,无需额外训练即可实现高效的入侵检测。
- 实验表明,该方法显著提升了入侵检测的准确率和F1分数,尤其是在GPT-4上表现优异。
📝 摘要(中文)
本文提出了一种基于预训练大型语言模型(LLM)的全自动网络入侵检测框架。该框架利用生成式预训练Transformer(GPTs)在信息理解和问题解决方面的卓越能力,并设计和比较了三种上下文学习方法,以增强LLM的性能。在真实网络入侵检测数据集上的实验表明,上下文学习在提高任务处理性能方面非常有效,且无需对LLM进行额外的训练或微调。实验结果表明,对于GPT-4,测试准确率和F1分数可以提高90%。此外,预训练的LLM在执行无线通信相关任务方面表现出巨大的潜力。具体而言,所提出的框架仅使用10个上下文学习示例,即可使GPT-4在不同类型的攻击上达到超过95%的准确率和F1分数。
🔬 方法详解
问题定义:论文旨在解决无线网络入侵检测的自动化和高性能问题。传统的入侵检测方法往往需要大量的人工特征工程和模型训练,难以适应新型攻击和动态变化的网络环境。此外,已有的基于机器学习的方法在泛化能力上存在局限性,难以在不同的网络环境中取得一致的性能。
核心思路:论文的核心思路是利用预训练大型语言模型(LLM)强大的上下文理解和推理能力,通过上下文学习(In-Context Learning)的方式,让LLM直接从少量的示例中学习入侵检测的模式,而无需进行额外的训练或微调。这种方法可以显著降低模型部署和维护的成本,并提高模型的泛化能力。
技术框架:该框架主要包含以下几个阶段:1) 数据预处理:将原始网络流量数据转换为LLM可以理解的文本格式。2) 上下文学习示例构建:选择或生成少量的入侵检测示例,作为LLM的上下文输入。3) LLM推理:将预处理后的数据和上下文学习示例输入到LLM中,让LLM判断是否存在入侵行为。4) 结果后处理:将LLM的输出转换为入侵检测的最终结果。
关键创新:该论文的关键创新在于将上下文学习应用于无线网络入侵检测,并设计了三种不同的上下文学习方法。与传统的监督学习方法相比,该方法无需大量的标注数据和模型训练,可以快速适应新的攻击类型和网络环境。此外,该论文还探索了不同LLM(如GPT-4)在入侵检测任务中的性能表现。
关键设计:论文中设计了三种上下文学习方法,具体细节未知。关键在于如何选择或生成合适的上下文学习示例,以提高LLM的入侵检测性能。此外,如何将原始网络流量数据转换为LLM可以理解的文本格式也是一个重要的技术细节。论文中使用了GPT-4,但未提及具体的参数设置和损失函数。
🖼️ 关键图片
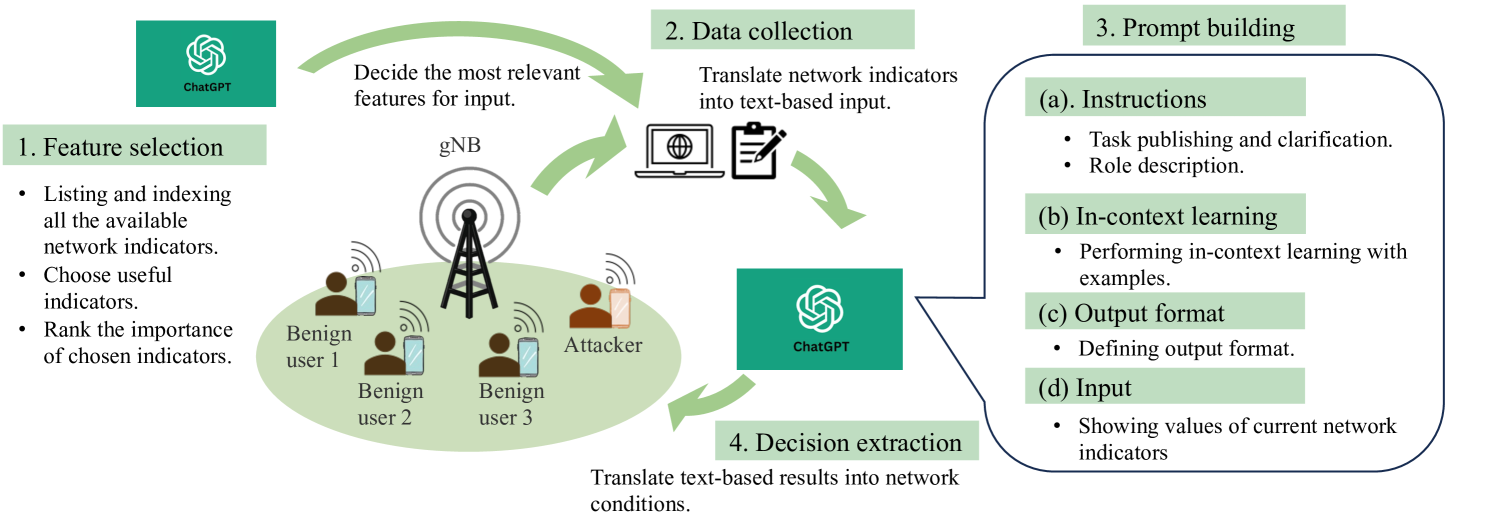


📊 实验亮点
实验结果表明,基于上下文学习的LLM框架在网络入侵检测任务中取得了显著的性能提升。对于GPT-4,测试准确率和F1分数可以提高90%,并且仅使用10个上下文学习示例,即可在不同类型的攻击上达到超过95%的准确率和F1分数。这些结果表明,LLM在无线通信安全领域具有巨大的应用潜力。
🎯 应用场景
该研究成果可应用于各种无线网络安全场景,例如智能家居、工业物联网、车载网络等。通过自动化的入侵检测,可以及时发现和阻止恶意攻击,保障网络的安全稳定运行。此外,该方法还可以用于构建智能化的安全防御系统,提高网络的安全防护能力,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Large language models (LLMs), especially generative pre-trained transformers (GPTs), have recently demonstrated outstanding ability in information comprehension and problem-solving. This has motivated many studies in applying LLMs to wireless communication networks. In this paper, we propose a pre-trained LLM-empowered framework to perform fully automatic network intrusion detection. Three in-context learning methods are designed and compared to enhance the performance of LLMs. With experiments on a real network intrusion detection dataset, in-context learning proves to be highly beneficial in improving the task processing performance in a way that no further training or fine-tuning of LLMs is required. We show that for GPT-4, testing accuracy and F1-Score can be improved by 90%. Moreover, pre-trained LLMs demonstrate big potential in performing wireless communication-related tasks. Specifically, the proposed framework can reach an accuracy and F1-Score of over 95% on different types of attacks with GPT-4 using only 10 in-context learning examples.