Time-Varying Constraint-Aware Reinforcement Learning for Energy Storage Control
作者: Jaeik Jeong, Tai-Yeon Ku, Wan-Ki Park
分类: cs.LG, cs.AI
发布日期: 2024-05-17
备注: ICLR 2024 Workshop: Tackling Climate Change with Machine Learning
💡 一句话要点
提出时变约束感知强化学习,用于优化储能设备控制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 储能控制 时变约束 连续控制 能源管理
📋 核心要点
- 传统强化学习在储能控制中面临挑战,离散方法难以处理连续充放电,而传统连续方法忽略了SoC约束下的时变可行范围。
- 提出一种连续强化学习方法,通过引入额外的目标函数,学习时变可行充放电范围,从而引导智能体探索更有效的策略。
- 实验结果表明,该方法能够更有效地利用储能设备,避免陷入持续满充或满放的次优状态,提升储能效率。
📝 摘要(中文)
储能设备,如电池、热能存储和氢系统,通过确保更稳定和可持续的电力供应,有助于减缓气候变化。为了最大限度地提高储能的效率,确定每个时间段的适当充放电量至关重要。由于强化学习能够适应动态和复杂环境,因此优于传统的储能控制优化方法。然而,储能中充放电水平的连续性对离散强化学习构成限制,并且基于荷电状态(SoC)可变性的时变可行充放电范围也限制了传统的连续强化学习。本文提出了一种考虑时变可行充放电范围的连续强化学习方法。引入了一个额外的目标函数,用于学习每个时间段的可行动作范围,补充了训练actor进行策略学习和critic进行价值学习的目标。这通过将充放电水平强制纳入可行动作范围,积极促进了储能的利用,防止它们陷入次优状态,例如持续充满电或放电。实验结果表明,所提出的方法通过积极提高储能的利用率,进一步最大化了储能的效率。
🔬 方法详解
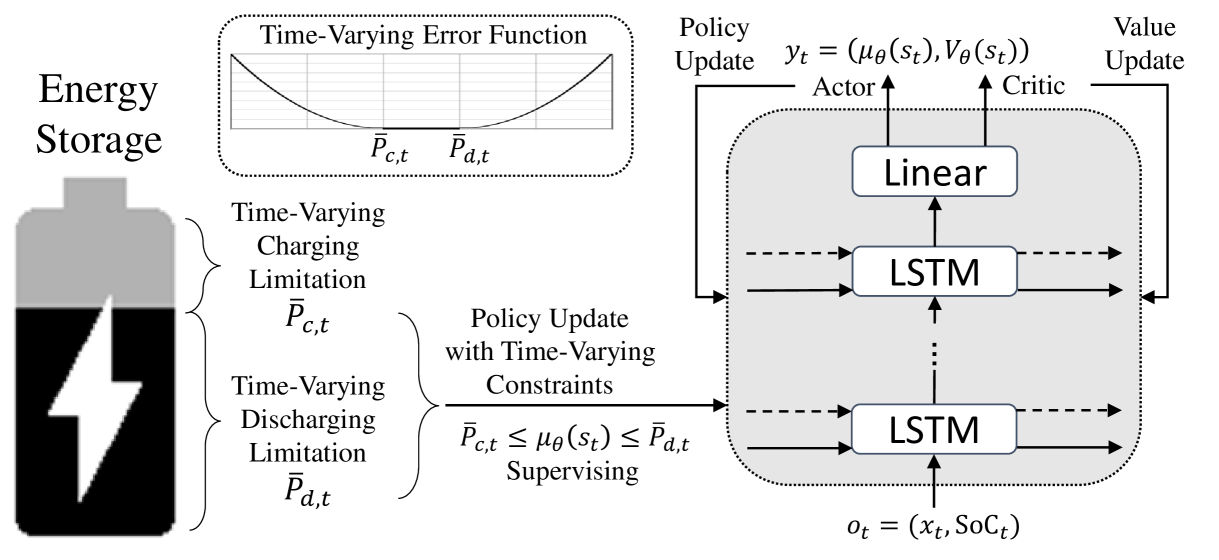
问题定义:论文旨在解决储能设备控制问题,具体而言,是如何在考虑电池荷电状态(SoC)约束下,优化充放电策略,以最大化储能效率。现有方法,特别是传统的连续强化学习方法,无法有效处理SoC约束带来的时变可行充放电范围,容易导致储能设备陷入次优状态,例如持续充满电或放电,从而限制了储能的利用率。
核心思路:论文的核心思路是设计一种能够感知时变约束的强化学习算法。通过引入额外的目标函数,显式地学习每个时间段的可行动作范围,并将充放电水平限制在该范围内。这种方法能够引导智能体探索更有效的策略,避免无效的动作,从而提高储能设备的利用率和效率。
技术框架:整体框架基于Actor-Critic架构的连续强化学习。主要包含三个模块:Actor网络,用于学习最优策略;Critic网络,用于评估策略的价值;以及一个额外的目标函数,用于学习时变可行动作范围。算法流程如下:首先,根据当前状态和Actor网络输出的策略,选择一个动作;然后,根据环境反馈和Critic网络评估的价值,更新Actor和Critic网络;同时,根据SoC约束,计算当前时间段的可行动作范围,并利用额外的目标函数,引导Actor网络输出的动作落入该范围内。
关键创新:论文的关键创新在于引入了时变约束感知机制,通过额外的目标函数,显式地学习可行动作范围。与传统的连续强化学习方法相比,该方法能够更好地处理SoC约束带来的时变性,避免无效的动作探索,从而提高学习效率和最终性能。
关键设计:额外的目标函数的设计是关键。该目标函数旨在最小化Actor网络输出的动作与可行动作范围之间的距离。具体而言,可以使用均方误差或交叉熵等损失函数来衡量这种距离。此外,Actor和Critic网络的结构选择也至关重要,可以根据具体的储能系统和控制目标进行调整。例如,可以使用循环神经网络(RNN)来处理时间序列数据,或者使用卷积神经网络(CNN)来提取状态特征。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的时变约束感知强化学习方法能够显著提高储能设备的利用率。与传统的连续强化学习方法相比,该方法能够避免储能设备陷入持续满充或满放的次优状态,从而更有效地利用储能容量。具体的性能提升幅度取决于具体的储能系统和控制目标,但总体而言,该方法能够带来显著的性能提升。
🎯 应用场景
该研究成果可应用于各种储能系统的优化控制,包括电池储能、热能存储和氢系统等。通过提高储能设备的利用率和效率,可以促进可再生能源的消纳,提高电力系统的稳定性和可靠性,从而为构建更可持续的能源体系做出贡献。未来,该方法有望扩展到更复杂的能源管理场景,例如微电网和智能建筑等。
📄 摘要(原文)
Energy storage devices, such as batteries, thermal energy storages, and hydrogen systems, can help mitigate climate change by ensuring a more stable and sustainable power supply. To maximize the effectiveness of such energy storage, determining the appropriate charging and discharging amounts for each time period is crucial. Reinforcement learning is preferred over traditional optimization for the control of energy storage due to its ability to adapt to dynamic and complex environments. However, the continuous nature of charging and discharging levels in energy storage poses limitations for discrete reinforcement learning, and time-varying feasible charge-discharge range based on state of charge (SoC) variability also limits the conventional continuous reinforcement learning. In this paper, we propose a continuous reinforcement learning approach that takes into account the time-varying feasible charge-discharge range. An additional objective function was introduced for learning the feasible action range for each time period, supplementing the objectives of training the actor for policy learning and the critic for value learning. This actively promotes the utilization of energy storage by preventing them from getting stuck in suboptimal states, such as continuous full charging or discharging. This is achieved through the enforcement of the charging and discharging levels into the feasible action range. The experimental results demonstrated that the proposed method further maximized the effectiveness of energy storage by actively enhancing its utilization.