Understanding the performance gap between online and offline alignment algorithms
作者: Yunhao Tang, Daniel Zhaohan Guo, Zeyu Zheng, Daniele Calandriello, Yuan Cao, Eugene Tarassov, Rémi Munos, Bernardo Ávila Pires, Michal Valko, Yong Cheng, Will Dabney
分类: cs.LG, cs.AI
发布日期: 2024-05-14
💡 一句话要点
揭示在线与离线对齐算法在强化学习人类反馈中的性能差距
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习人类反馈 在线对齐算法 离线对齐算法 奖励过度优化 AI对齐
📋 核心要点
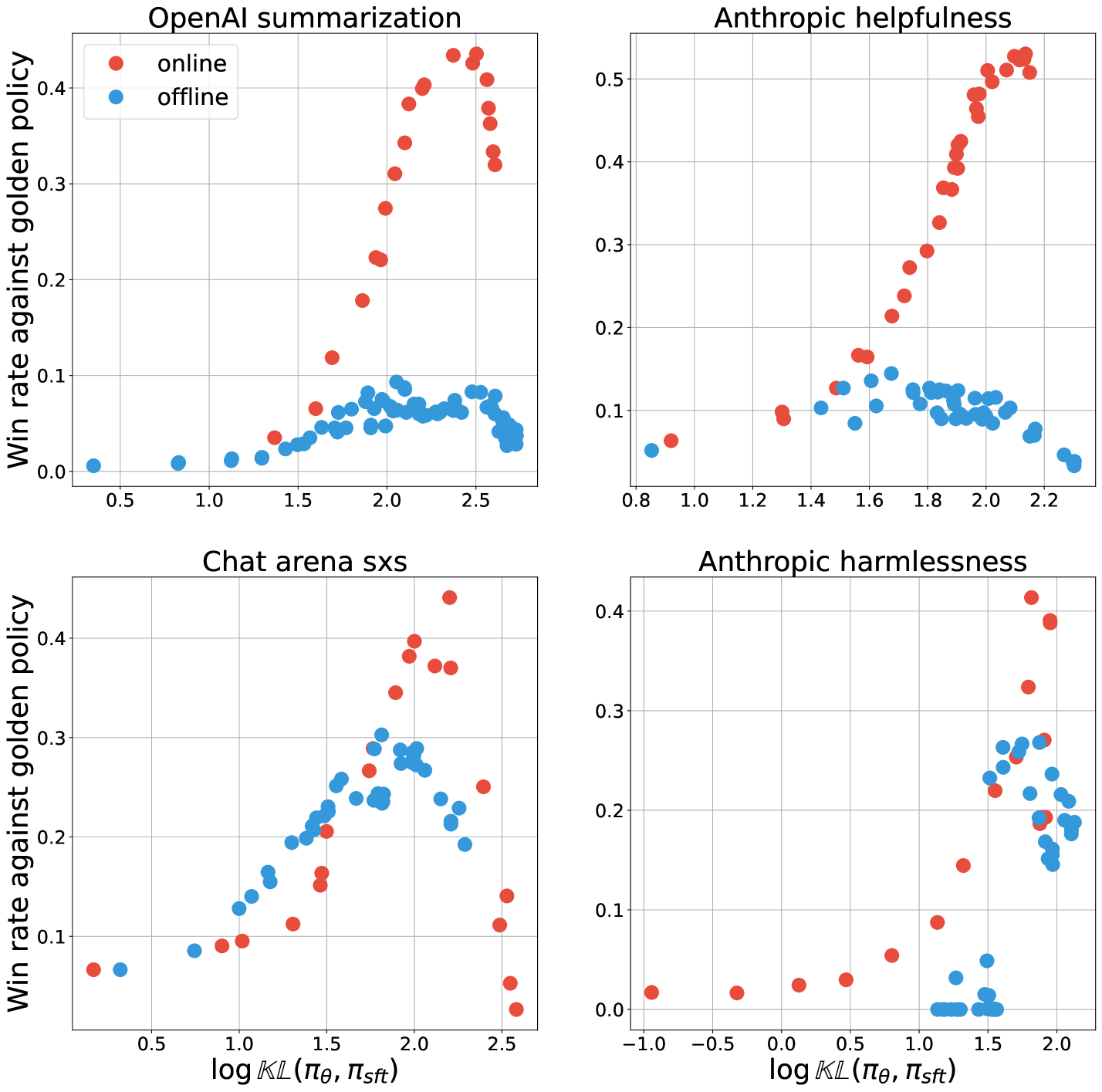
- 现有RLHF框架依赖在线采样,但离线对齐算法的兴起对其必要性提出挑战,本文旨在探究在线与离线方法在奖励过度优化方面的性能差距。
- 通过实验对比在线与离线算法,并进行消融研究,分析离线数据覆盖、数据质量等因素对性能差异的影响,揭示根本原因。
- 实验表明,在线算法在生成能力上优于离线算法,而离线算法在成对分类上更优,暗示采样过程对判别和生成能力有重要影响。
📝 摘要(中文)
本文研究了强化学习人类反馈(RLHF)中在线和离线对齐算法的性能差异。通过一系列实验,证明了在线方法相对于离线方法的明显优势。进一步的实验分析表明,离线数据覆盖率和数据质量本身无法完全解释这种性能差异。研究发现,离线算法训练的策略在成对分类方面表现良好,但在生成方面较差;而在线算法训练的策略在生成方面表现良好,但在成对分类方面较差。这暗示了判别能力和生成能力之间存在独特的相互作用,并且受到采样过程的显著影响。此外,性能差异在对比损失函数和非对比损失函数中都存在,并且似乎不能通过简单地扩大策略网络来解决。这项研究揭示了在线采样在AI对齐中的关键作用,并暗示了离线对齐算法的某些根本性挑战。
🔬 方法详解
问题定义:本文旨在解决在强化学习人类反馈(RLHF)中,在线对齐算法和离线对齐算法之间存在的性能差距问题。现有的RLHF框架主要依赖于在线采样,但随着离线对齐算法的出现,人们开始质疑在线采样的必要性。然而,离线算法在实际应用中往往表现不如在线算法,这引发了对二者差异原因的探究。现有方法缺乏对这种性能差异的深入理解,无法有效指导离线对齐算法的改进。
核心思路:本文的核心思路是通过一系列精心设计的实验,系统性地分析导致在线和离线算法性能差异的各种因素。通过消融实验,逐步排除诸如离线数据覆盖率和数据质量等可能的解释,从而揭示更深层次的原因。此外,本文还关注在线和离线算法在判别能力(成对分类)和生成能力上的差异,并探讨采样过程在其中的作用。
技术框架:本文采用实验驱动的研究方法,主要包括以下几个阶段:1) 对比在线和离线算法的性能,验证在线算法的优势;2) 通过消融实验,分析离线数据覆盖率和数据质量对性能的影响;3) 评估在线和离线算法在成对分类和生成任务上的表现;4) 考察不同损失函数(对比损失和非对比损失)以及策略网络规模对性能差异的影响。整个研究框架旨在系统地揭示在线和离线算法性能差异的根本原因。
关键创新:本文最重要的技术创新在于对在线和离线对齐算法性能差异的系统性分析和深入理解。通过实验,揭示了离线算法在成对分类上表现良好,但在生成方面较差;而在线算法则相反。这暗示了判别能力和生成能力之间存在独特的相互作用,并且受到采样过程的显著影响。这种对性能差异的细致分析为改进离线对齐算法提供了新的思路。
关键设计:本文的关键设计包括:1) 精心设计的消融实验,用于排除各种可能的解释;2) 对成对分类和生成任务的独立评估,用于分析在线和离线算法在不同能力上的表现;3) 对比对比损失函数和非对比损失函数,以及不同规模的策略网络,用于考察这些因素对性能差异的影响。这些设计旨在全面、深入地理解在线和离线算法的性能差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在线算法在奖励过度优化方面明显优于离线算法。消融实验表明,离线数据覆盖率和数据质量本身无法完全解释这种性能差异。研究发现,离线算法训练的策略在成对分类方面表现良好,但在生成方面较差;而在线算法训练的策略在生成方面表现良好,但在成对分类方面较差。此外,性能差异在对比损失函数和非对比损失函数中都存在,并且不能通过简单地扩大策略网络来解决。
🎯 应用场景
该研究成果对强化学习人类反馈(RLHF)领域具有重要意义,有助于更好地理解在线和离线对齐算法的优缺点,从而指导算法选择和改进。潜在应用包括:提升大型语言模型的对齐效果,降低在线采样的成本,以及开发更有效的离线对齐算法。未来,该研究可以扩展到其他AI对齐任务,例如机器人控制和推荐系统。
📄 摘要(原文)
Reinforcement learning from human feedback (RLHF) is the canonical framework for large language model alignment. However, rising popularity in offline alignment algorithms challenge the need for on-policy sampling in RLHF. Within the context of reward over-optimization, we start with an opening set of experiments that demonstrate the clear advantage of online methods over offline methods. This prompts us to investigate the causes to the performance discrepancy through a series of carefully designed experimental ablations. We show empirically that hypotheses such as offline data coverage and data quality by itself cannot convincingly explain the performance difference. We also find that while offline algorithms train policy to become good at pairwise classification, it is worse at generations; in the meantime the policies trained by online algorithms are good at generations while worse at pairwise classification. This hints at a unique interplay between discriminative and generative capabilities, which is greatly impacted by the sampling process. Lastly, we observe that the performance discrepancy persists for both contrastive and non-contrastive loss functions, and appears not to be addressed by simply scaling up policy networks. Taken together, our study sheds light on the pivotal role of on-policy sampling in AI alignment, and hints at certain fundamental challenges of offline alignment algorithms.