ExplainableDetector: Exploring Transformer-based Language Modeling Approach for SMS Spam Detection with Explainability Analysis
作者: Mohammad Amaz Uddin, Muhammad Nazrul Islam, Leandros Maglaras, Helge Janicke, Iqbal H. Sarker
分类: cs.LG
发布日期: 2024-05-12
💡 一句话要点
ExplainableDetector:利用可解释Transformer语言模型进行短信垃圾检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 短信垃圾检测 Transformer模型 RoBERTa 可解释人工智能 文本分类 网络安全 文本增强
📋 核心要点
- 短信垃圾检测面临非结构化数据和类别不平衡的挑战,传统方法难以有效应对。
- 利用优化微调的Transformer语言模型,结合文本增强解决数据不平衡问题,提升检测性能。
- 实验表明,RoBERTa模型达到99.84%的准确率,并结合XAI技术提高模型可解释性。
📝 摘要(中文)
短信服务(SMS)作为一种广泛使用且经济高效的通信媒介,不幸地成为了垃圾信息的温床。随着智能手机和互联网连接的快速普及,短信垃圾邮件已成为一种普遍存在的威胁。垃圾邮件发送者已经注意到短信对于手机用户的重要性。因此,随着新的网络安全威胁的出现,短信垃圾邮件的数量近年来显著增加。SMS数据非结构化的格式给短信垃圾邮件检测带来了重大挑战,使得在网络安全领域成功对抗垃圾邮件攻击变得更加困难。本文采用优化和微调的基于Transformer的大型语言模型(LLM)来解决垃圾邮件检测问题。我们使用基准SMS垃圾邮件数据集进行垃圾邮件检测,并利用多种预处理技术来获得干净且无噪声的数据,并使用文本增强技术解决类别不平衡问题。实验结果表明,我们优化的微调BERT变体模型RoBERTa获得了高达99.84%的准确率。我们还使用可解释人工智能(XAI)技术来计算正负系数得分,从而探索和解释微调模型在基于文本的垃圾短信检测任务中的透明度。此外,还研究了传统的机器学习(ML)模型,以将其性能与基于Transformer的模型进行比较。该分析描述了LLM如何对网络安全领域中复杂的基于文本的垃圾邮件数据产生良好的影响。
🔬 方法详解
问题定义:论文旨在解决短信垃圾邮件检测问题。现有方法在处理非结构化短信数据和类别不平衡问题时存在不足,导致检测精度不高,且缺乏可解释性,难以理解模型决策依据。
核心思路:论文的核心思路是利用预训练的Transformer语言模型(特别是RoBERTa)强大的文本理解能力,通过微调和优化,使其能够更准确地识别垃圾短信。同时,结合可解释人工智能(XAI)技术,提高模型决策过程的透明度,使用户能够理解模型判断垃圾短信的原因。
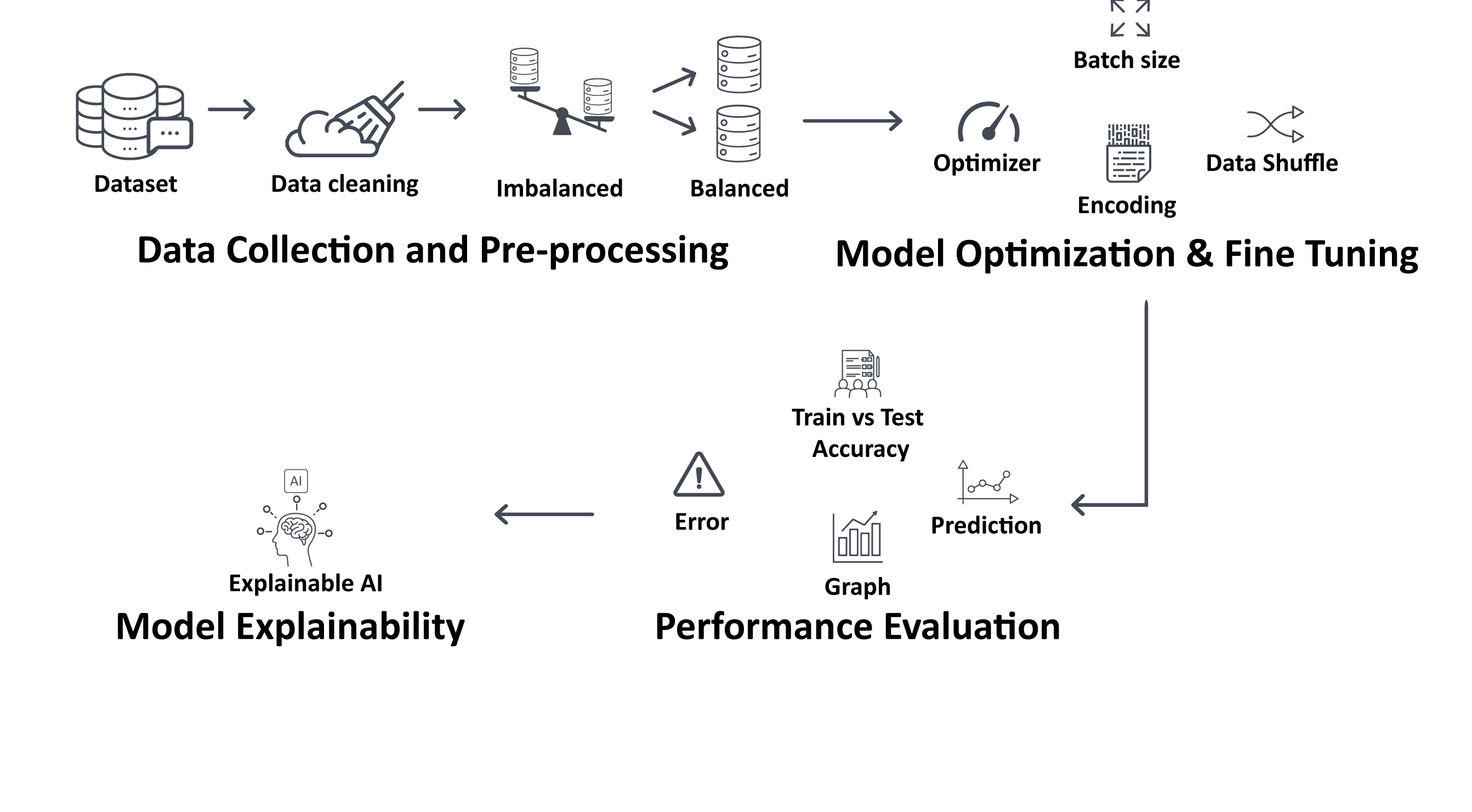
技术框架:整体框架包括数据预处理、模型训练和评估、以及可解释性分析三个主要阶段。首先,对原始短信数据进行清洗和预处理,包括去除噪声、分词等。然后,使用文本增强技术解决类别不平衡问题。接着,使用预训练的RoBERTa模型进行微调,并在测试集上评估模型性能。最后,利用XAI技术分析模型在进行垃圾短信判断时所关注的关键特征。
关键创新:论文的关键创新在于将优化的Transformer语言模型应用于短信垃圾邮件检测,并结合XAI技术提高模型的可解释性。相比于传统的机器学习方法,Transformer模型能够更好地捕捉文本中的语义信息,从而提高检测精度。同时,XAI技术的引入使得模型决策过程更加透明,有助于用户理解和信任模型。
关键设计:论文使用了RoBERTa模型作为基础模型,并对其进行了微调。具体来说,使用了分类交叉熵损失函数进行训练,并采用AdamW优化器进行参数更新。此外,论文还使用了文本增强技术,例如随机插入、随机删除等,来解决类别不平衡问题。XAI方面,采用了如LIME或SHAP等方法来计算每个词语对模型预测结果的贡献度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,经过优化和微调的RoBERTa模型在短信垃圾邮件检测任务中取得了99.84%的准确率,显著优于传统的机器学习模型。此外,通过XAI技术,论文还展示了模型在进行垃圾短信判断时所关注的关键特征,提高了模型的可解释性。
🎯 应用场景
该研究成果可应用于移动安全软件、短信过滤服务、以及网络安全监控系统等领域。通过提高短信垃圾邮件的检测精度和可解释性,可以有效减少用户受垃圾信息骚扰,降低网络钓鱼和恶意软件传播的风险,提升整体网络安全水平。未来,该技术还可扩展到其他文本分类任务,例如情感分析、舆情监控等。
📄 摘要(原文)
SMS, or short messaging service, is a widely used and cost-effective communication medium that has sadly turned into a haven for unwanted messages, commonly known as SMS spam. With the rapid adoption of smartphones and Internet connectivity, SMS spam has emerged as a prevalent threat. Spammers have taken notice of the significance of SMS for mobile phone users. Consequently, with the emergence of new cybersecurity threats, the number of SMS spam has expanded significantly in recent years. The unstructured format of SMS data creates significant challenges for SMS spam detection, making it more difficult to successfully fight spam attacks in the cybersecurity domain. In this work, we employ optimized and fine-tuned transformer-based Large Language Models (LLMs) to solve the problem of spam message detection. We use a benchmark SMS spam dataset for this spam detection and utilize several preprocessing techniques to get clean and noise-free data and solve the class imbalance problem using the text augmentation technique. The overall experiment showed that our optimized fine-tuned BERT (Bidirectional Encoder Representations from Transformers) variant model RoBERTa obtained high accuracy with 99.84\%. We also work with Explainable Artificial Intelligence (XAI) techniques to calculate the positive and negative coefficient scores which explore and explain the fine-tuned model transparency in this text-based spam SMS detection task. In addition, traditional Machine Learning (ML) models were also examined to compare their performance with the transformer-based models. This analysis describes how LLMs can make a good impact on complex textual-based spam data in the cybersecurity field.