Ensemble Successor Representations for Task Generalization in Offline-to-Online Reinforcement Learning
作者: Changhong Wang, Xudong Yu, Chenjia Bai, Qiaosheng Zhang, Zhen Wang
分类: cs.LG, cs.AI
发布日期: 2024-05-12
备注: Accepted by Science China Information Sciences
💡 一句话要点
提出集成后继表示,解决离线到在线强化学习中的任务泛化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 离线强化学习 任务泛化 后继表示 集成学习
📋 核心要点
- 现有离线到在线强化学习方法在任务泛化方面存在不足,无法有效利用离线数据适应新任务。
- 提出一种利用离线数据学习集成后继表示的方法,构建集成Q函数,实现鲁棒的表示学习。
- 实验结果表明,该方法在推广到不同甚至未见过的任务时,性能优于现有方法。
📝 摘要(中文)
强化学习(RL)中,从零开始通过在线经验训练策略效率低下,因为探索困难。最近,离线强化学习提供了一个有希望的解决方案,它提供了一个初始化的离线策略,可以通过在线交互进行改进。然而,现有方法主要在同一任务中执行离线和在线学习,而没有考虑离线到在线适应中的任务泛化问题。在实际应用中,我们通常只有一个来自特定任务的离线数据集,但目标是针对多个任务进行快速在线适应。为了解决这个问题,我们的工作建立在对在线RL中任务泛化的后继表示的研究基础上,并将该框架扩展到包含离线到在线学习。我们证明了使用后继特征的传统范式无法有效地利用离线数据,也无法通过在线微调来提高新任务的性能。为了缓解这个问题,我们引入了一种新颖的方法,该方法利用离线数据来获取后继表示的集成,并随后构建集成Q函数。这种方法能够从具有不同覆盖率的数据集中进行鲁棒的表示学习,并促进Q函数在在线微调阶段快速适应新任务。广泛的经验评估提供了令人信服的证据,展示了我们的方法在推广到不同甚至未见过的任务方面的卓越性能。
🔬 方法详解
问题定义:论文旨在解决离线到在线强化学习中的任务泛化问题。现有方法主要关注在同一任务上进行离线和在线学习,忽略了实际应用中需要快速适应多个不同任务的需求。传统方法无法有效利用离线数据来提升新任务的在线适应性能,导致学习效率低下。
核心思路:论文的核心思路是利用离线数据学习一组(ensemble)后继表示,并基于此构建集成Q函数。通过集成多个后继表示,可以更好地捕捉离线数据的多样性,从而提升模型在新任务上的泛化能力。这种方法旨在克服传统后继特征方法在利用离线数据方面的局限性。
技术框架:整体框架包含两个主要阶段:离线学习阶段和在线微调阶段。在离线学习阶段,利用离线数据集训练一个后继表示的集成模型。该集成模型包含多个独立的后继表示学习器。然后,基于这些后继表示构建集成Q函数。在在线微调阶段,使用在线交互数据对集成Q函数进行微调,使其快速适应新任务。
关键创新:关键创新在于利用集成学习的思想来提升后继表示的泛化能力。传统的后继表示方法通常只学习一个单一的表示,容易受到离线数据分布的限制。通过学习多个后继表示,并将其集成起来,可以更鲁棒地捕捉离线数据的特征,从而更好地泛化到新任务。
关键设计:论文的关键设计包括:1) 如何构建后继表示的集成,例如可以使用不同的初始化或不同的网络结构来训练多个后继表示学习器;2) 如何将多个后继表示集成到Q函数中,例如可以使用加权平均或更复杂的集成方法;3) 如何设计损失函数来鼓励后继表示的多样性,从而提升集成的效果。具体的参数设置和网络结构等细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片
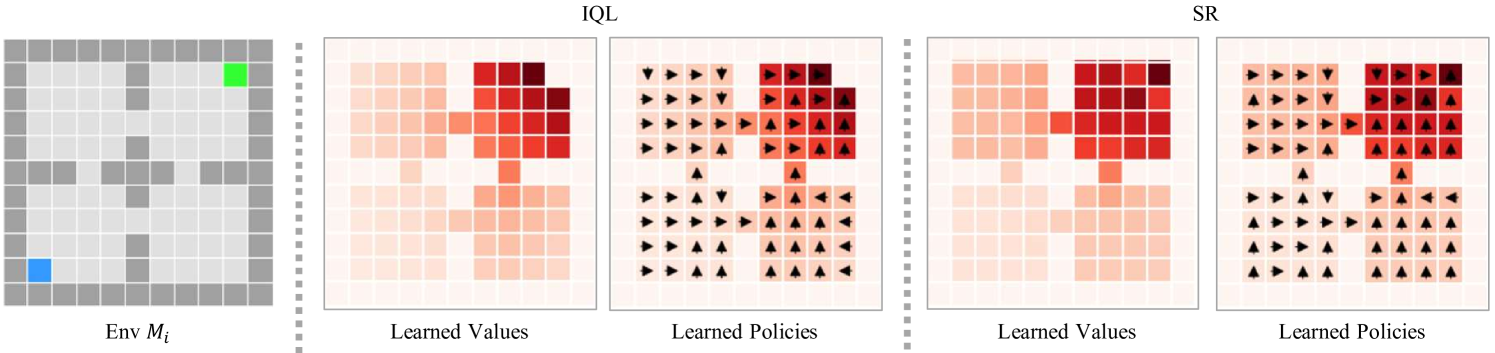

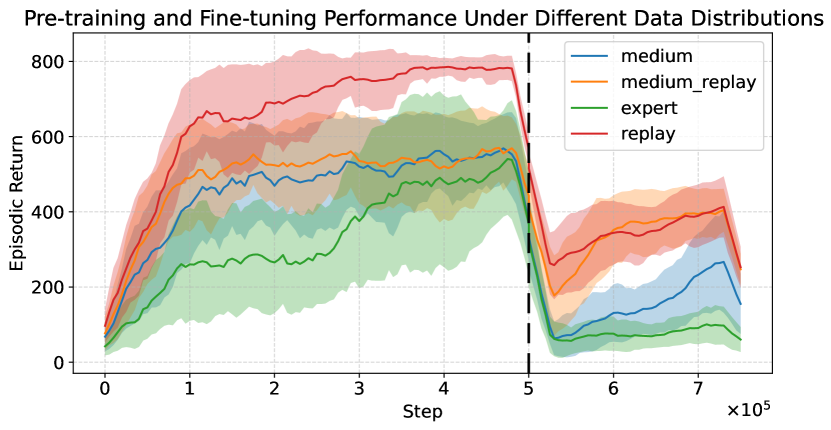
📊 实验亮点
论文通过实验证明,所提出的集成后继表示方法在任务泛化方面优于现有方法。具体而言,该方法在多个不同的任务上实现了显著的性能提升,尤其是在推广到未见过的任务时,表现出更强的鲁棒性和适应性。具体的性能数据和对比基线需要在论文中查找(未知)。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。例如,可以利用已有的机器人操作数据集,快速训练机器人适应新的操作任务。在游戏AI中,可以利用历史游戏数据,使AI快速适应新的游戏关卡或规则。在自动驾驶中,可以利用已有的驾驶数据,使自动驾驶系统快速适应新的驾驶环境或场景。
📄 摘要(原文)
In Reinforcement Learning (RL), training a policy from scratch with online experiences can be inefficient because of the difficulties in exploration. Recently, offline RL provides a promising solution by giving an initialized offline policy, which can be refined through online interactions. However, existing approaches primarily perform offline and online learning in the same task, without considering the task generalization problem in offline-to-online adaptation. In real-world applications, it is common that we only have an offline dataset from a specific task while aiming for fast online-adaptation for several tasks. To address this problem, our work builds upon the investigation of successor representations for task generalization in online RL and extends the framework to incorporate offline-to-online learning. We demonstrate that the conventional paradigm using successor features cannot effectively utilize offline data and improve the performance for the new task by online fine-tuning. To mitigate this, we introduce a novel methodology that leverages offline data to acquire an ensemble of successor representations and subsequently constructs ensemble Q functions. This approach enables robust representation learning from datasets with different coverage and facilitates fast adaption of Q functions towards new tasks during the online fine-tuning phase. Extensive empirical evaluations provide compelling evidence showcasing the superior performance of our method in generalizing to diverse or even unseen tasks.