AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting
作者: Shreyan Ganguly, Roshan Nayak, Rakshith Rao, Ujan Deb, Prathosh AP
分类: cs.LG, cs.AI
发布日期: 2024-05-11
💡 一句话要点
AdaKD:提出自适应损失权重动态知识蒸馏方法,提升语音识别模型性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 语音识别 模型压缩 自适应权重 课程学习
📋 核心要点
- 现有知识蒸馏方法对任务特定损失和蒸馏损失赋予相同权重,忽略了样本难度差异,导致性能受限。
- AdaKD 提出自适应损失权重调整策略,根据教师模型的损失动态调整每个样本的蒸馏损失权重,模拟课程学习。
- 实验结果表明,AdaKD 优于传统知识蒸馏方法和现有实例级损失函数,验证了其有效性。
📝 摘要(中文)
知识蒸馏是一种广泛使用的模型压缩技术,其核心思想是将知识从复杂的教师模型迁移到轻量级的学生模型。该技术通常涉及联合优化任务特定损失和知识蒸馏损失,并为它们分配权重。然而,这些权重在蒸馏过程中起着至关重要的作用,但现有方法通常为两种损失赋予相同的权重,导致性能欠佳。本文提出了一种名为自适应知识蒸馏(Adaptive Knowledge Distillation)的新技术,该技术受到课程学习的启发,能够在实例级别自适应地调整损失权重。该方法基于样本难度随教师损失增加的理念。我们的方法遵循即插即用的范式,可以应用于任何任务特定和蒸馏目标。实验表明,我们的方法优于传统的知识蒸馏方法和现有的实例级损失函数。
🔬 方法详解
问题定义:论文旨在解决语音识别(ASR)模型知识蒸馏过程中,静态损失权重分配导致的学生模型性能瓶颈问题。现有方法通常为任务特定损失和知识蒸馏损失分配固定的权重,无法根据样本的难易程度进行动态调整,导致蒸馏效果不佳。特别是对于难样本,固定的权重可能无法充分利用教师模型的知识。
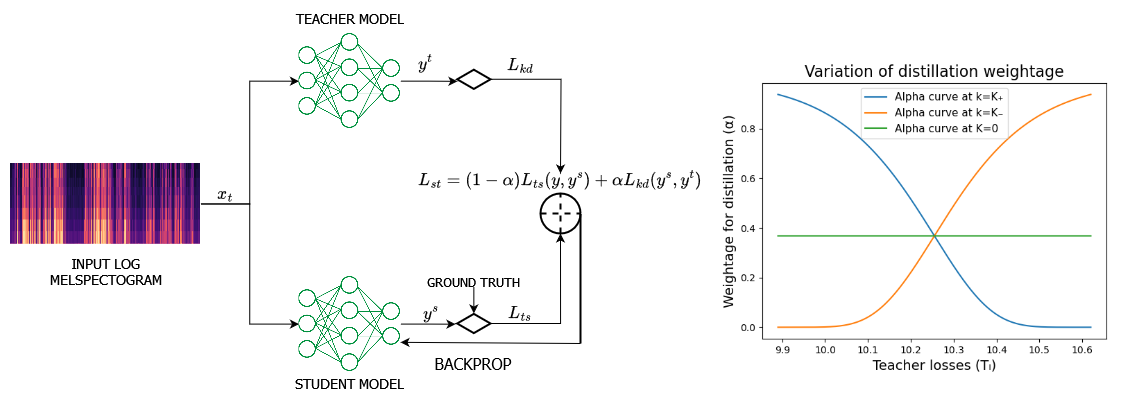
核心思路:论文的核心思路是借鉴课程学习的思想,认为样本的难度与教师模型的损失相关。因此,提出根据教师模型的损失大小,自适应地调整每个样本的知识蒸馏损失权重。对于教师模型损失较大的难样本,赋予更高的蒸馏损失权重,促使学生模型更好地学习这些样本的知识。
技术框架:AdaKD 遵循即插即用的范式,可以应用于任何现有的知识蒸馏框架。其主要流程如下:首先,使用教师模型对输入样本进行预测,并计算教师模型的损失。然后,根据教师模型的损失,计算每个样本的自适应权重。最后,使用自适应权重对知识蒸馏损失进行加权,并与任务特定损失一起优化学生模型。整体框架简单易用,易于集成到现有系统中。
关键创新:AdaKD 最重要的技术创新点在于提出了自适应损失权重调整策略。与现有方法中静态的损失权重分配方式不同,AdaKD 能够根据样本的难易程度动态调整损失权重,从而更好地利用教师模型的知识。这种自适应调整策略能够有效地提高学生模型的性能,尤其是在处理难样本时。
关键设计:AdaKD 的关键设计在于自适应权重的计算方式。论文中,自适应权重通常是教师模型损失的函数,例如可以使用 sigmoid 函数将教师模型损失映射到 [0, 1] 之间,作为蒸馏损失的权重。具体的函数形式可以根据实际情况进行调整。此外,损失函数的选择也很重要,常见的知识蒸馏损失函数包括 KL 散度、L2 损失等。论文中并没有限定具体的损失函数,用户可以根据自己的需求进行选择。
🖼️ 关键图片
📊 实验亮点
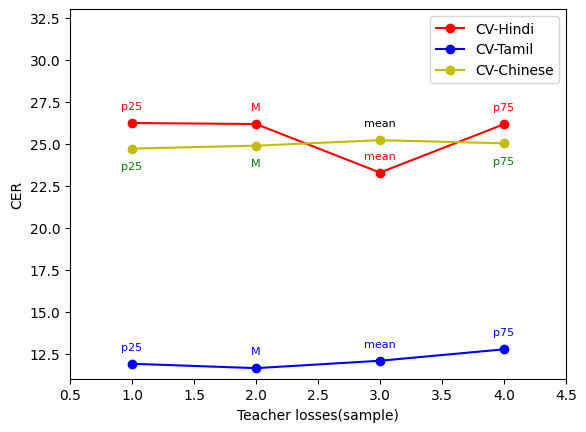
实验结果表明,AdaKD 在语音识别任务上优于传统的知识蒸馏方法和现有的实例级损失函数。具体来说,AdaKD 能够在保持模型大小不变的情况下,显著提高学生模型的识别精度。与基线方法相比,AdaKD 能够降低词错误率(WER),证明了其有效性。
🎯 应用场景
AdaKD 可广泛应用于语音识别模型的压缩和加速,尤其适用于资源受限的设备,如移动端和嵌入式系统。通过知识蒸馏,可以将大型、高性能的语音识别模型压缩成小型、轻量级的模型,同时保持较高的识别精度。此外,该方法也可推广到其他序列模型,例如机器翻译、文本摘要等。
📄 摘要(原文)
Knowledge distillation, a widely used model compression technique, works on the basis of transferring knowledge from a cumbersome teacher model to a lightweight student model. The technique involves jointly optimizing the task specific and knowledge distillation losses with a weight assigned to them. Despite these weights playing a crucial role in the performance of the distillation process, current methods provide equal weight to both losses, leading to suboptimal performance. In this paper, we propose Adaptive Knowledge Distillation, a novel technique inspired by curriculum learning to adaptively weigh the losses at instance level. This technique goes by the notion that sample difficulty increases with teacher loss. Our method follows a plug-and-play paradigm that can be applied on top of any task-specific and distillation objectives. Experiments show that our method performs better than conventional knowledge distillation method and existing instance-level loss functions.