Open Challenges and Opportunities in Federated Foundation Models Towards Biomedical Healthcare
作者: Xingyu Li, Lu Peng, Yuping Wang, Weihua Zhang
分类: cs.LG
发布日期: 2024-05-10
备注: 42 pages
💡 一句话要点
综述联邦学习与预训练模型在生物医学健康领域的应用、挑战与机遇。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 预训练模型 生物医学 医疗健康 数据隐私
📋 核心要点
- 现有方法难以在保护患者隐私的前提下,有效利用大规模医疗数据训练强大的预训练模型。
- 核心思想是将联邦学习与预训练模型相结合,在本地训练模型并聚合参数,实现知识共享和隐私保护。
- 综述总结了当前应用、挑战和未来方向,旨在鼓励更多研究,推动医疗保健领域的创新。
📝 摘要(中文)
本综述探讨了预训练模型(FMs)在人工智能领域的变革性影响,重点关注其与联邦学习(FL)的结合,以推进生物医学研究。诸如ChatGPT、LLaMa和CLIP等预训练模型,通过无监督预训练、自监督学习、指令微调以及基于人类反馈的强化学习等方法在海量数据集上进行训练,代表了机器学习的重大进步。这些模型具有生成连贯文本和逼真图像的能力,对于需要处理临床报告、诊断图像和多模态患者交互等多样化数据形式的生物医学应用至关重要。将FL与这些复杂模型相结合,为利用其分析能力同时保护敏感医疗数据的隐私提供了一种有前景的策略。这种方法不仅增强了FMs在医学诊断和个性化治疗方面的能力,还解决了医疗保健中关于数据隐私和安全的关键问题。本综述回顾了FMs在联邦环境中的当前应用,强调了挑战,并确定了未来的研究方向,包括扩展FMs、管理数据多样性以及提高FL框架内的通信效率。目标是鼓励进一步研究FMs和FL的结合潜力,为突破性的医疗保健创新奠定基础。
🔬 方法详解
问题定义:论文旨在解决如何在保护患者隐私的前提下,利用大规模异构生物医学数据训练和部署强大的预训练模型。现有方法要么依赖中心化数据训练,存在隐私泄露风险,要么难以处理不同机构之间的数据差异性,导致模型泛化能力不足。
核心思路:论文的核心思路是将联邦学习(FL)与预训练模型(FMs)相结合。FL允许在本地设备上训练模型,然后仅共享模型更新或参数,而不是原始数据,从而保护隐私。同时,利用FMs强大的表征学习能力,可以更好地处理生物医学数据的复杂性和多样性。
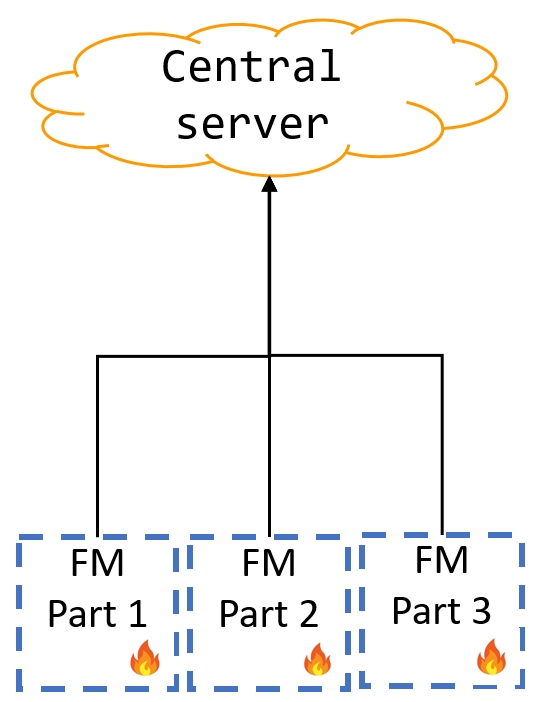
技术框架:整体框架涉及多个参与方(例如医院或研究机构),每个参与方拥有本地数据集。每个参与方首先使用本地数据对预训练模型进行微调或训练。然后,使用联邦平均等算法,将各个参与方的模型更新或参数进行聚合,得到一个全局模型。这个全局模型可以部署到各个参与方,用于诊断、预测或其他任务。
关键创新:关键创新在于将FL的隐私保护特性与FMs强大的学习能力相结合,从而能够在不泄露敏感数据的前提下,构建高性能的生物医学模型。此外,论文还探讨了如何解决FL中数据异构性、通信效率等挑战,并提出了相应的解决方案。
关键设计:关键设计包括选择合适的预训练模型架构(例如Transformer、CNN等),设计有效的联邦学习聚合算法(例如FedAvg、FedProx等),以及采用差分隐私等技术进一步增强隐私保护。此外,还需要考虑如何处理不同机构之间的数据格式、标注标准等差异,以提高模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
该综述总结了当前联邦学习与预训练模型在生物医学领域的应用,并指出了现有方法的局限性,例如数据异构性、通信效率等。同时,论文还提出了未来研究方向,例如扩展预训练模型规模、管理数据多样性、提高通信效率等,为后续研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于多种生物医学健康领域,例如疾病诊断、药物发现、个性化治疗等。通过联邦学习和预训练模型,可以在保护患者隐私的前提下,利用全球范围内的医疗数据,构建更准确、更可靠的医疗AI系统,从而改善患者的治疗效果和生活质量。
📄 摘要(原文)
This survey explores the transformative impact of foundation models (FMs) in artificial intelligence, focusing on their integration with federated learning (FL) for advancing biomedical research. Foundation models such as ChatGPT, LLaMa, and CLIP, which are trained on vast datasets through methods including unsupervised pretraining, self-supervised learning, instructed fine-tuning, and reinforcement learning from human feedback, represent significant advancements in machine learning. These models, with their ability to generate coherent text and realistic images, are crucial for biomedical applications that require processing diverse data forms such as clinical reports, diagnostic images, and multimodal patient interactions. The incorporation of FL with these sophisticated models presents a promising strategy to harness their analytical power while safeguarding the privacy of sensitive medical data. This approach not only enhances the capabilities of FMs in medical diagnostics and personalized treatment but also addresses critical concerns about data privacy and security in healthcare. This survey reviews the current applications of FMs in federated settings, underscores the challenges, and identifies future research directions including scaling FMs, managing data diversity, and enhancing communication efficiency within FL frameworks. The objective is to encourage further research into the combined potential of FMs and FL, laying the groundwork for groundbreaking healthcare innovations.