Characterizing the Accuracy -- Efficiency Trade-off of Low-rank Decomposition in Language Models
作者: Chakshu Moar, Faraz Tahmasebi, Michael Pellauer, Hyoukjun Kwon
分类: cs.LG, cs.CL
发布日期: 2024-05-10 (更新: 2024-10-22)
💡 一句话要点
针对LLM,论文提出低秩分解方法,在精度损失可控下实现模型压缩。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩分解 模型压缩 大型语言模型 Tucker分解 精度-效率权衡
📋 核心要点
- 大型语言模型参数众多,导致内存占用高、推理速度慢,现有压缩方法在精度和效率间权衡不足。
- 论文探索了低秩分解(Tucker分解)在LLM压缩中的应用,旨在降低模型大小,提升推理效率。
- 实验表明,在BERT和Llama 2模型上,通过低秩分解可实现模型大小显著降低,同时精度损失控制在可接受范围内。
📝 摘要(中文)
当前的大型语言模型(LLM)依赖数十亿的参数来实现广泛的问题解决能力。由于矩阵-向量和矩阵-矩阵乘法占据主导地位且算术强度较低,这些模型通常受限于内存。因此,优化LLM的内存占用和流量是一个重要的优化方向。模型压缩方法,如量化和参数剪枝,已被积极探索以实现内存占用和流量优化。然而,对于LLM,秩剪枝(即低秩分解)的精度-效率权衡尚未得到充分理解。因此,本文针对包括开源LLM Llama 2在内的最新语言模型,对低秩分解方法(特别是Tucker分解)的精度-效率权衡进行了表征。我们形式化了低秩分解设计空间,并表明该设计空间非常巨大(例如,对于Llama2-7B,为O($2^{39}$))。为了驾驭如此庞大的设计空间,我们对其进行了形式化,并使用BERT和Llama 2模型在六个广泛使用的LLM基准上进行了彻底的案例研究,以分析精度-效率权衡。结果表明,我们可以在模型大小减少9%的情况下,实现最小的精度下降,根据基准测试的难度,精度下降范围从4%p到10%p不等,而无需在分解后进行任何再训练来恢复精度。结果表明,对于需要大规模实时服务的基于LLM的应用(例如,AI代理和实时编码助手),低秩分解可能是一个有希望的方向,在这些应用中,延迟与模型精度同等重要。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)参数量巨大,导致内存占用高、推理速度慢的问题。现有模型压缩方法,如量化和剪枝,虽然可以降低模型大小,但在精度和效率之间存在权衡,尤其是在低秩分解方面,缺乏对LLM的深入研究。
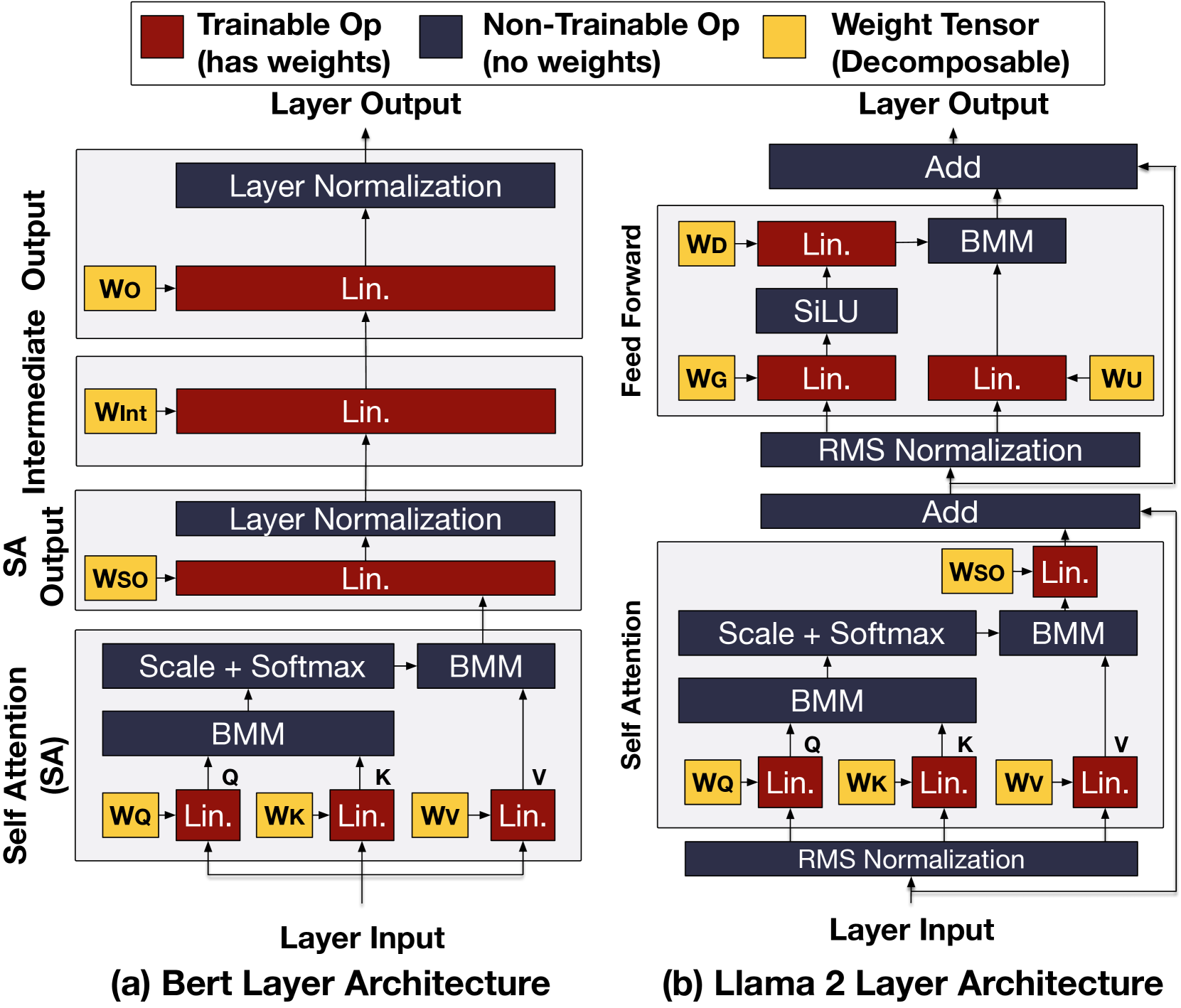
核心思路:论文的核心思路是利用低秩分解(特别是Tucker分解)来压缩LLM中的权重矩阵。通过将原始矩阵分解为多个低秩矩阵的乘积,从而减少参数数量,降低内存占用,并提高推理速度。这种方法的核心在于找到合适的低秩分解配置,以在精度和效率之间取得最佳平衡。
技术框架:论文的技术框架主要包括以下几个步骤:1) 形式化低秩分解的设计空间,分析不同分解配置对模型大小和精度的影响。2) 选择Tucker分解作为主要的低秩分解方法。3) 在BERT和Llama 2等LLM上应用Tucker分解。4) 在多个基准测试数据集上评估分解后的模型的精度和效率。5) 分析精度-效率的权衡,找到最佳的分解配置。
关键创新:论文的关键创新在于对LLM的低秩分解设计空间进行了全面的形式化和探索。论文强调了设计空间的巨大性,并提出了通过案例研究来分析精度-效率权衡的方法。与现有方法相比,该研究更系统地研究了低秩分解在LLM上的应用,并提供了关于如何选择合适的分解配置的指导。
关键设计:论文的关键设计包括:1) 使用Tucker分解作为主要的低秩分解方法。2) 针对不同的LLM层,探索不同的秩配置。3) 在分解后不进行再训练,以评估低秩分解的原始效果。4) 使用多个基准测试数据集来评估模型的泛化能力。论文还特别关注了在精度损失最小化的前提下,尽可能地降低模型大小。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过Tucker分解,可以在Llama 2模型上实现9%的模型大小缩减,同时在六个广泛使用的LLM基准测试中,精度下降范围仅为4%p到10%p,且无需进行任何再训练。这表明低秩分解是一种有效的LLM压缩方法,可以在精度损失可控的情况下显著降低模型大小。
🎯 应用场景
该研究成果可应用于各种需要实时响应的大规模LLM应用,例如AI助手、实时代码辅助、智能客服等。通过降低模型大小和提高推理速度,可以降低部署成本,提升用户体验,并促进LLM在资源受限设备上的应用。未来,该方法有望与其他模型压缩技术结合,进一步提升LLM的效率。
📄 摘要(原文)
Recent large language models (LLMs) employ billions of parameters to enable broad problem-solving capabilities. Such language models also tend to be memory-bound because of the dominance of matrix-vector and matrix-matrix multiplications with low arithmetic intensity. Therefore, optimizing the memory footprint and traffic is an important optimization direction for LLMs today. Model compression methods such as quantization and parameter pruning have been actively explored to achieve memory footprint and traffic optimization. However, the accuracy-efficiency trade-off of rank pruning (i.e., low-rank decomposition) for LLMs is not well-understood yet. Therefore, in this work, we characterize the accuracy-efficiency trade-off of a low-rank decomposition method, specifically Tucker decomposition, on recent language models, including an open-source LLM, Llama 2. We formalize the low-rank decomposition design space and show that the decomposition design space is enormous (e.g., O($2^{39}$) for Llama2-7B). To navigate such a vast design space, we formulate it and perform thorough case studies of accuracy-efficiency trade-offs using six widely used LLM benchmarks on BERT and Llama 2 models. Our results show that we can achieve a 9\% model size reduction with minimal accuracy drops, which range from 4\%p (\%p refers to "percentage point," which refers to the absolute difference between two percentage numbers; 74\% -> 78\% = 4\%p increase) to 10\%p, depending on the difficulty of the benchmark, without any retraining to recover accuracy after decomposition. The results show that low-rank decomposition can be a promising direction for LLM-based applications that require real-time service at scale (e.g., AI agent and real-time coding assistant), where the latency is as important as the model accuracy.