SKVQ: Sliding-window Key and Value Cache Quantization for Large Language Models
作者: Haojie Duanmu, Zhihang Yuan, Xiuhong Li, Jiangfei Duan, Xingcheng Zhang, Dahua Lin
分类: cs.LG, cs.CL
发布日期: 2024-05-10 (更新: 2024-11-12)
💡 一句话要点
SKVQ:滑动窗口键值缓存量化,用于压缩大语言模型KV缓存
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 KV缓存 量化 低比特量化 滑动窗口 模型压缩 长上下文
📋 核心要点
- 大语言模型处理长序列时,KV缓存占用大量内存,成为部署瓶颈,尤其是在资源受限的设备上。
- SKVQ通过重排KV缓存通道提高量化组内相似性,并采用裁剪动态量化,同时高精度保留最近窗口token。
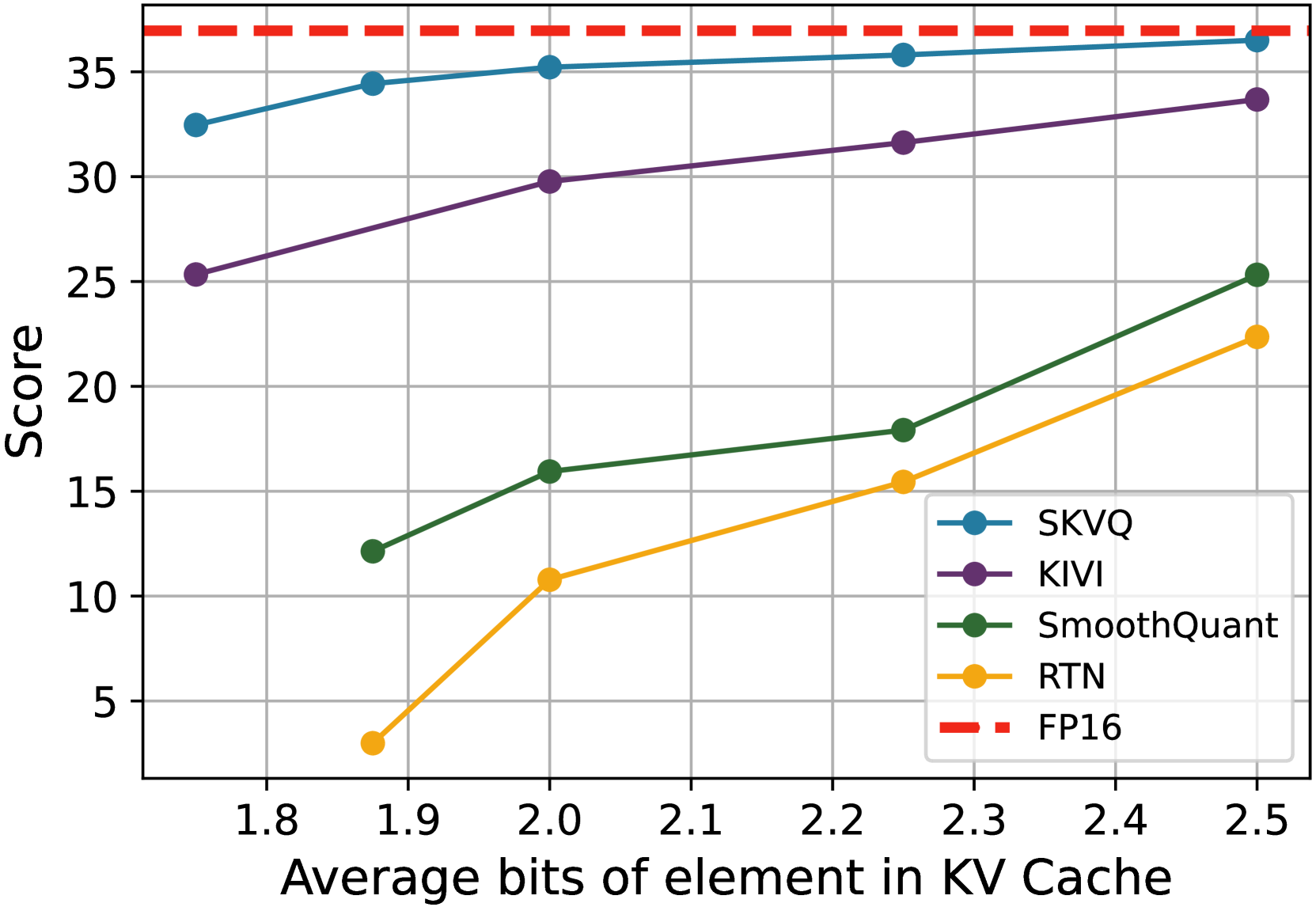
- 实验表明,SKVQ能将KV缓存量化到2bit(key)和1.5bit(value),精度损失小,并显著提升解码速度。
📝 摘要(中文)
大型语言模型(LLMs)现在可以处理更长的token序列,从而实现诸如书籍理解和生成长篇小说等复杂任务。然而,随着上下文长度的增加,LLMs所需的键-值(KV)缓存消耗大量内存,成为部署的瓶颈。本文提出了一种名为SKVQ的策略,即滑动窗口KV缓存量化,以解决极低比特宽度KV缓存量化的问题。为了实现这一点,SKVQ重新排列KV缓存的通道,以提高量化组中通道的相似性,并在组级别应用裁剪动态量化。此外,SKVQ确保KV缓存中最近的窗口token以高精度保存。这有助于保持KV缓存中一小部分重要部分的准确性。SKVQ实现了高压缩率,同时保持了准确性。在LLMs上的评估表明,SKVQ超越了以前的量化方法,允许将KV缓存量化为2比特的键和1.5比特的值,而精度损失最小。使用SKVQ,可以在具有80GB内存GPU上处理高达1M的上下文长度,对于7b模型,解码速度提高高达7倍。
🔬 方法详解
问题定义:论文旨在解决大语言模型中KV缓存占用内存过大的问题,尤其是在长上下文场景下。现有的量化方法在极低比特宽度下会造成显著的精度损失,限制了模型部署和推理效率。
核心思路:SKVQ的核心思路是在量化过程中,尽可能保证重要信息的精度,同时提高量化的压缩率。通过滑动窗口机制,保证最近的token信息以较高精度存储,并通过通道重排提高量化组内的相似性,从而减少量化误差。
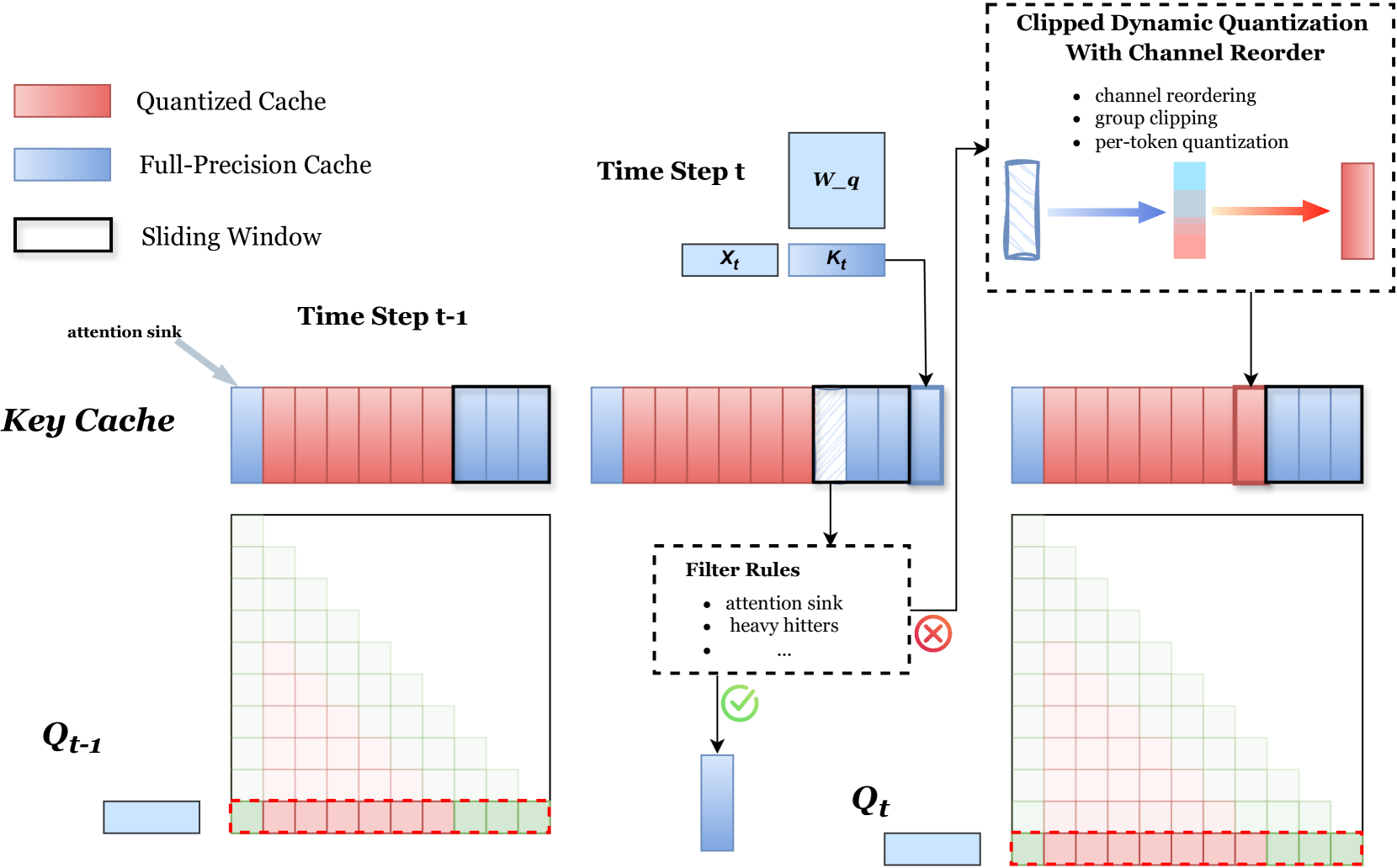
技术框架:SKVQ主要包含以下几个阶段:1) KV缓存通道重排:重新排列KV缓存的通道,使得相似的通道在同一个量化组内。2) 滑动窗口高精度保留:将最近的token信息保留在滑动窗口内,并使用较高的精度进行存储。3) 裁剪动态量化:在量化组级别应用裁剪动态量化,进一步压缩KV缓存的大小。
关键创新:SKVQ的关键创新在于结合了滑动窗口和通道重排的量化策略。滑动窗口保证了最近token信息的精度,通道重排提高了量化组内的相似性,从而减少了量化误差。这种结合使得SKVQ能够在极低比特宽度下保持较高的精度。
关键设计:SKVQ的关键设计包括:1) 通道重排策略:具体如何确定通道之间的相似性,并进行重排?(论文未明确说明,未知)2) 滑动窗口大小的确定:如何根据不同的任务和模型选择合适的滑动窗口大小?(论文未明确说明,未知)3) 裁剪动态量化的参数设置:如何确定裁剪的阈值和量化的比特宽度?(论文未明确说明,未知)
🖼️ 关键图片

📊 实验亮点
SKVQ在LLMs上的评估表明,它超越了以往的量化方法,允许将KV缓存量化到2比特的键和1.5比特的值,同时精度损失最小。对于7b模型,使用SKVQ可以在具有80GB内存的GPU上处理高达1M的上下文长度,并且解码速度提高了高达7倍。这些结果表明SKVQ在压缩KV缓存和提高推理效率方面具有显著优势。
🎯 应用场景
SKVQ可应用于各种需要处理长上下文的大语言模型部署场景,例如移动设备、边缘计算设备等资源受限的环境。通过降低KV缓存的内存占用,SKVQ能够支持更长的上下文长度,并提高推理速度,从而提升用户体验。该技术还有助于降低大语言模型的部署成本,加速其在各行业的应用。
📄 摘要(原文)
Large language models (LLMs) can now handle longer sequences of tokens, enabling complex tasks like book understanding and generating lengthy novels. However, the key-value (KV) cache required for LLMs consumes substantial memory as context length increasing, becoming the bottleneck for deployment. In this paper, we present a strategy called SKVQ, which stands for sliding-window KV cache quantization, to address the issue of extremely low bitwidth KV cache quantization. To achieve this, SKVQ rearranges the channels of the KV cache in order to improve the similarity of channels in quantization groups, and applies clipped dynamic quantization at the group level. Additionally, SKVQ ensures that the most recent window tokens in the KV cache are preserved with high precision. This helps maintain the accuracy of a small but important portion of the KV cache.SKVQ achieves high compression ratios while maintaining accuracy. Our evaluation on LLMs demonstrates that SKVQ surpasses previous quantization approaches, allowing for quantization of the KV cache to 2-bit keys and 1.5-bit values with minimal loss of accuracy. With SKVQ, it is possible to process context lengths of up to 1M on an 80GB memory GPU for a 7b model and up to 7 times faster decoding.