From Algorithm to Hardware: A Survey on Efficient and Safe Deployment of Deep Neural Networks
作者: Xue Geng, Zhe Wang, Chunyun Chen, Qing Xu, Kaixin Xu, Chao Jin, Manas Gupta, Xulei Yang, Zhenghua Chen, Mohamed M. Sabry Aly, Jie Lin, Min Wu, Xiaoli Li
分类: cs.LG, cs.AI
发布日期: 2024-05-09
备注: This manuscript is the accepted version for TNNLS(IEEE Transactions on Neural Networks and Learning Systems)
💡 一句话要点
综述深度神经网络高效安全部署:算法、硬件加速与安全
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 深度神经网络 模型压缩 硬件加速 安全部署 模型量化 模型剪枝 知识蒸馏 同态加密
📋 核心要点
- 深度神经网络部署面临内存、能耗和计算成本的挑战,现有方法难以兼顾效率与性能。
- 该综述旨在全面回顾DNN模型压缩、硬件加速和安全部署的最新研究进展,提供整体视角。
- 综述涵盖模型量化、剪枝、知识蒸馏等压缩技术,以及定制硬件加速器和同态加密等安全方案。
📝 摘要(中文)
深度神经网络(DNNs)已广泛应用于众多人工智能(AI)任务中。然而,由于内存、能源和计算成本巨大,部署它们面临着严峻的挑战。为了应对这些挑战,研究人员开发了各种模型压缩技术,如模型量化和模型剪枝。最近,压缩方法的研究激增,旨在实现模型效率的同时保持性能。此外,越来越多的工作致力于定制DNN硬件加速器,以更好地利用模型压缩技术。除了效率之外,保持安全性和隐私对于部署DNN至关重要。然而,大量且多样化的相关工作可能会让人应接不暇。这促使我们对近期关于高性能、高性价比和安全部署DNN的研究进行全面综述。我们的综述首先涵盖了主流模型压缩技术,如模型量化、模型剪枝、知识蒸馏和非线性运算优化。然后,我们介绍了在设计能够适应高效模型压缩方法的硬件加速器方面的最新进展。此外,我们还讨论了如何集成同态加密以确保DNN部署的安全性。最后,我们讨论了几个问题,如硬件评估、泛化以及各种压缩方法的集成。总的来说,我们的目标是从算法到硬件加速器和安全角度,提供高效DNN的全貌。
🔬 方法详解
问题定义:深度神经网络在部署时面临着巨大的计算、存储和能耗开销,这限制了它们在资源受限设备上的应用。现有的模型压缩方法虽然能够在一定程度上降低模型复杂度,但往往会牺牲模型的精度或泛化能力。此外,如何保证模型在部署过程中的安全性,防止恶意攻击和数据泄露,也是一个重要的挑战。
核心思路:该综述的核心思路是从算法、硬件和安全三个维度,全面梳理深度神经网络高效部署的相关技术。通过对模型压缩算法、硬件加速器设计和安全部署方案的分析,为研究人员提供一个系统性的参考框架,帮助他们更好地理解和解决深度神经网络部署所面临的挑战。
技术框架:该综述的技术框架主要包括三个部分:模型压缩算法、硬件加速器设计和安全部署方案。模型压缩算法部分涵盖了模型量化、模型剪枝、知识蒸馏等主流技术;硬件加速器设计部分介绍了针对压缩模型的定制化硬件加速器;安全部署方案部分讨论了同态加密等技术在保护模型隐私方面的应用。此外,综述还讨论了硬件评估、泛化能力和多种压缩方法集成等问题。
关键创新:该综述的关键创新在于其全面性和系统性。它不仅涵盖了模型压缩算法,还涉及了硬件加速器设计和安全部署方案,从而为研究人员提供了一个更完整的视角。此外,该综述还对未来的研究方向进行了展望,例如如何更好地集成不同的压缩方法,如何设计更高效的硬件加速器,以及如何提高模型的安全性。
关键设计:该综述并没有提出新的算法或模型,而是对现有技术进行了梳理和总结。在模型压缩算法部分,综述重点介绍了量化、剪枝和知识蒸馏等技术的基本原理和优缺点。在硬件加速器设计部分,综述介绍了针对不同压缩模型的定制化硬件加速器的设计思路。在安全部署方案部分,综述介绍了同态加密等技术在保护模型隐私方面的应用。
🖼️ 关键图片

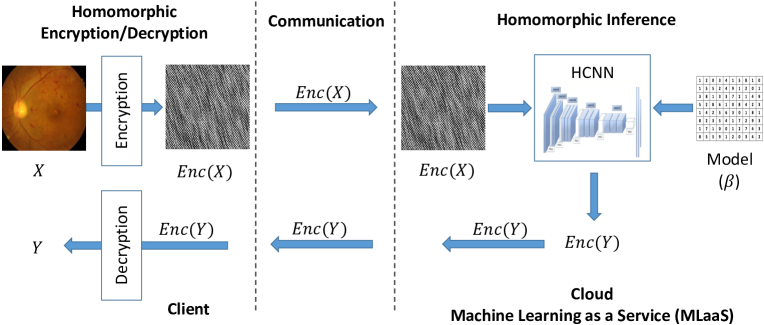
📊 实验亮点
该综述全面梳理了深度神经网络高效部署的各个方面,从算法到硬件再到安全,为研究人员提供了一个系统性的参考框架。它总结了各种模型压缩技术的优缺点,介绍了硬件加速器的设计思路,并讨论了安全部署方案。该综述有助于研究人员更好地理解和解决深度神经网络部署所面临的挑战,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果对人工智能的广泛应用具有重要意义,尤其是在资源受限的边缘设备上部署高性能深度学习模型。例如,在自动驾驶、智能监控、移动医疗等领域,高效的模型部署能够降低成本、提高响应速度,并保护用户隐私。未来,随着技术的不断发展,该研究将推动人工智能在更多领域的应用。
📄 摘要(原文)
Deep neural networks (DNNs) have been widely used in many artificial intelligence (AI) tasks. However, deploying them brings significant challenges due to the huge cost of memory, energy, and computation. To address these challenges, researchers have developed various model compression techniques such as model quantization and model pruning. Recently, there has been a surge in research of compression methods to achieve model efficiency while retaining the performance. Furthermore, more and more works focus on customizing the DNN hardware accelerators to better leverage the model compression techniques. In addition to efficiency, preserving security and privacy is critical for deploying DNNs. However, the vast and diverse body of related works can be overwhelming. This inspires us to conduct a comprehensive survey on recent research toward the goal of high-performance, cost-efficient, and safe deployment of DNNs. Our survey first covers the mainstream model compression techniques such as model quantization, model pruning, knowledge distillation, and optimizations of non-linear operations. We then introduce recent advances in designing hardware accelerators that can adapt to efficient model compression approaches. Additionally, we discuss how homomorphic encryption can be integrated to secure DNN deployment. Finally, we discuss several issues, such as hardware evaluation, generalization, and integration of various compression approaches. Overall, we aim to provide a big picture of efficient DNNs, from algorithm to hardware accelerators and security perspectives.