KV Cache is 1 Bit Per Channel: Efficient Large Language Model Inference with Coupled Quantization
作者: Tianyi Zhang, Jonah Yi, Zhaozhuo Xu, Anshumali Shrivastava
分类: cs.LG
发布日期: 2024-05-07
💡 一句话要点
提出耦合量化(CQ),实现KV缓存1比特量化,提升大语言模型推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 KV缓存 量化 耦合量化 低比特量化
📋 核心要点
- 大语言模型推理时,KV缓存占用大量GPU内存,成为性能瓶颈,尤其是在低比特量化下。
- 论文提出耦合量化(CQ)方法,通过耦合多个KV通道,利用通道间依赖性,实现更高效的信息编码。
- 实验表明,CQ在极低比特(1比特)量化下,仍能保持模型质量,优于或媲美现有方法。
📝 摘要(中文)
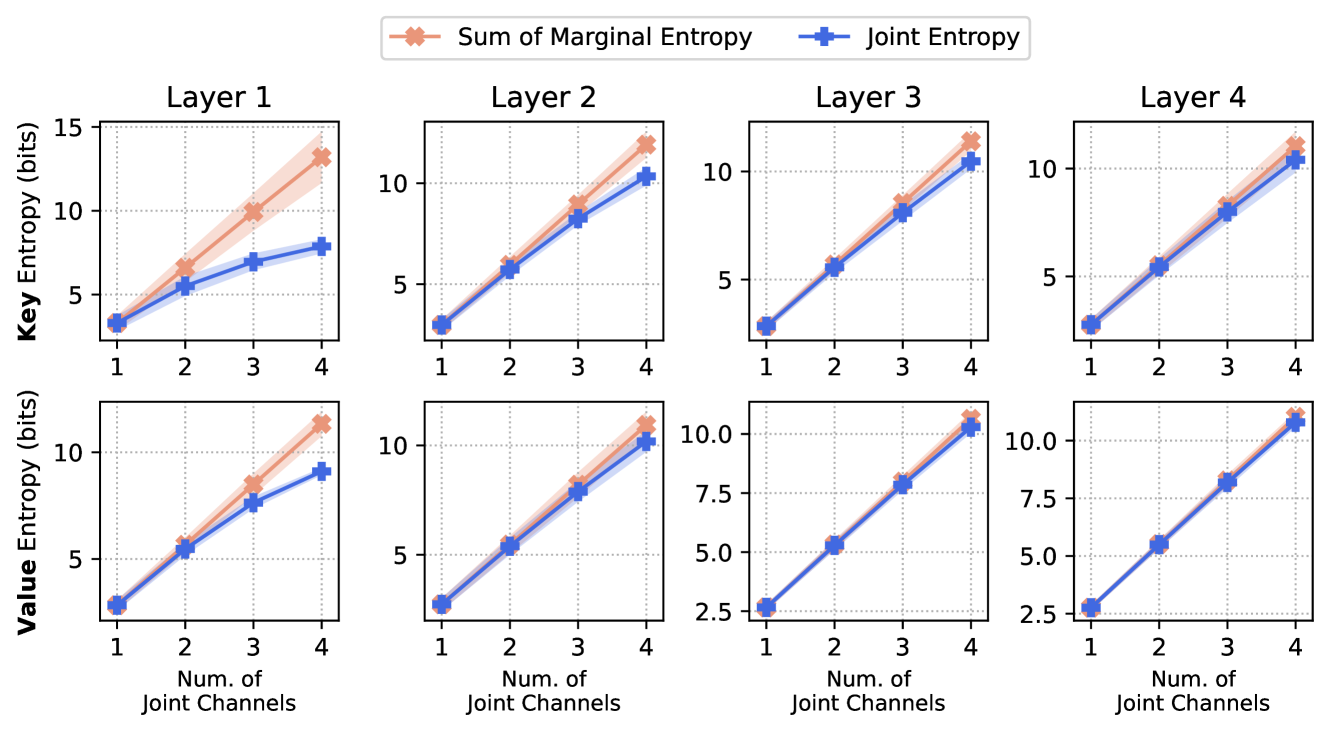
为了高效部署大型语言模型(LLMs),通常需要批量处理多个请求以提高吞吐量。随着批大小、上下文长度或模型大小的增加,键值(KV)缓存的大小迅速成为GPU内存使用的主要因素和推理延迟的瓶颈。量化已成为一种有效的KV缓存压缩技术,但现有方法在极低比特宽度下仍然失效。我们观察到,键/值激活嵌入的不同通道高度相互依赖,并且多个通道的联合熵的增长速度低于其边际熵之和。基于这一观察,我们提出了耦合量化(CQ),它将多个键/值通道耦合在一起,以利用它们的相互依赖性,并以更信息高效的方式编码激活。大量实验表明,CQ在保持模型质量方面优于或与现有基线具有竞争力。此外,我们证明了CQ可以在KV缓存量化到1比特时保持模型质量。
🔬 方法详解
问题定义:现有的大语言模型推理过程中,KV缓存占据了大量的GPU内存,尤其是在需要处理长序列或者大批量请求时。现有的量化方法在较低的比特宽度下,例如1比特量化,通常会导致模型性能显著下降,无法满足实际应用的需求。因此,如何在极低比特宽度下有效地压缩KV缓存,同时保持模型性能,是一个亟待解决的问题。
核心思路:论文的核心思路是观察到KV缓存中不同通道之间存在高度的相互依赖性。传统的量化方法通常独立地量化每个通道,忽略了通道间的关联信息。CQ方法通过耦合多个通道,共同进行量化,从而能够更好地利用通道间的冗余信息,实现更高效的压缩。这种耦合量化的方式能够更有效地保留原始数据的信息,从而在极低比特宽度下保持模型性能。
技术框架:CQ方法主要包含以下几个步骤:首先,选择需要进行量化的KV缓存层。然后,将多个通道进行分组,每个组内的通道将被耦合在一起进行量化。接下来,对于每个通道组,计算其联合分布,并基于联合分布设计量化方案。最后,使用量化后的值替换原始的KV缓存值。在推理过程中,需要进行反量化操作,将量化后的值恢复到原始的数值范围。
关键创新:CQ方法的关键创新在于提出了耦合量化的概念,打破了传统量化方法中通道间独立的假设。通过耦合多个通道,CQ方法能够更好地利用通道间的依赖关系,从而实现更高效的压缩。与现有的量化方法相比,CQ方法能够在极低比特宽度下保持更高的模型性能。
关键设计:CQ方法的关键设计包括通道分组策略和联合量化方案。通道分组策略决定了哪些通道将被耦合在一起进行量化。一个有效的分组策略应该将具有高度相关性的通道分到同一组。联合量化方案则决定了如何基于通道组的联合分布进行量化。一个好的联合量化方案应该能够最小化量化误差,同时保证量化后的值能够有效地表示原始数据。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CQ方法在KV缓存量化到1比特时,仍能保持较高的模型性能。与现有的量化方法相比,CQ方法在多个benchmark上取得了显著的提升。例如,在某些任务上,CQ方法能够达到与未量化模型相当的性能,同时将KV缓存的内存占用降低到原来的1/32。
🎯 应用场景
该研究成果可广泛应用于大语言模型的部署和推理加速,尤其是在资源受限的边缘设备或移动设备上。通过极低比特的KV缓存量化,可以显著降低内存占用,提高推理速度,使得大语言模型能够在更多场景下应用,例如智能助手、对话机器人、文本生成等。
📄 摘要(原文)
Efficient deployment of Large Language Models (LLMs) requires batching multiple requests together to improve throughput. As the batch size, context length, or model size increases, the size of the key and value (KV) cache can quickly become the main contributor to GPU memory usage and the bottleneck of inference latency. Quantization has emerged as an effective technique for KV cache compression, but existing methods still fail at very low bit widths. We observe that distinct channels of a key/value activation embedding are highly inter-dependent, and the joint entropy of multiple channels grows at a slower rate than the sum of their marginal entropies. Based on this insight, we propose Coupled Quantization (CQ), which couples multiple key/value channels together to exploit their inter-dependency and encode the activations in a more information-efficient manner. Extensive experiments reveal that CQ outperforms or is competitive with existing baselines in preserving model quality. Furthermore, we demonstrate that CQ can preserve model quality with KV cache quantized down to 1-bit.