TED: Accelerate Model Training by Internal Generalization
作者: Jinying Xiao, Ping Li, Jie Nie
分类: cs.LG
发布日期: 2024-05-06 (更新: 2025-09-15)
备注: ECAI 2024
DOI: 10.3233/FAIA240823
💡 一句话要点
提出TED剪枝方法,通过内部泛化加速模型训练并压缩数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型剪枝 内部泛化 数据集压缩 高效训练 大型语言模型
📋 核心要点
- 大型模型训练成本高昂,数据集压缩需求迫切,但高剪枝率易导致过拟合。
- TED剪枝通过量化模型在剪枝数据上的内部泛化能力,优化剪枝策略,实现隐式正则化。
- 实验表明,TED在图像分类、自然语言理解和LLM微调上,仅用60-70%数据即可达到无损性能。
📝 摘要(中文)
近年来,大型语言模型展现出强大的性能,但高昂的训练成本推动了对高效数据集压缩方法的需求。我们提出了TED剪枝,该方法通过量化模型在拟合保留数据的同时改进剪枝数据性能的能力(称为内部泛化(IG)),从而解决了高剪枝率下的过拟合挑战。TED使用基于内部泛化距离(IGD)的优化目标,测量剪枝前后IG的变化,以与真实泛化性能对齐并实现隐式正则化。IGD优化目标被验证可以使模型达到泛化误差的最小上界。通过掩码和泰勒近似研究了小掩码波动对IG的影响,并实现了IGD的快速估计。在分析连续训练动态时,验证了IGD的先验效应,并提出了一种渐进式剪枝策略。在图像分类、自然语言理解和大型语言模型微调上的实验表明,TED在保留60-70%数据的情况下实现了无损性能。代码将在接收后公开。
🔬 方法详解
问题定义:论文旨在解决大型模型训练中,由于数据集规模庞大而导致的训练成本高昂问题。现有数据集剪枝方法在高剪枝率下容易导致模型过拟合,泛化能力下降,无法在减少数据量的同时保持模型性能。
核心思路:论文的核心思路是利用“内部泛化(Internal Generalization, IG)”的概念,即模型在拟合保留数据的同时,改进剪枝数据的性能的能力。通过优化剪枝策略,使得剪枝后的模型能够更好地在内部泛化,从而提升整体的泛化能力,避免过拟合。
技术框架:TED剪枝方法主要包含以下几个阶段:1) IGD的定义与计算:定义内部泛化距离(Internal Generalization Distance, IGD),用于量化剪枝前后内部泛化的变化。2) IGD的快速估计:利用掩码和泰勒近似,实现IGD的快速估计,降低计算复杂度。3) 优化目标构建:构建基于IGD的优化目标,指导剪枝过程,使模型达到泛化误差的最小上界。4) 渐进式剪枝策略:根据连续训练动态,提出渐进式剪枝策略,逐步减少数据量。
关键创新:论文的关键创新在于提出了基于内部泛化的剪枝策略。与传统的基于数据重要性或模型参数重要性的剪枝方法不同,TED剪枝关注模型在剪枝数据上的泛化能力,通过优化IGD来指导剪枝过程,从而实现更好的泛化性能。
关键设计:论文的关键设计包括:1) IGD的定义:IGD被定义为剪枝前后内部泛化的变化,用于衡量剪枝对模型泛化能力的影响。2) IGD的快速估计方法:利用泰勒展开近似计算IGD,避免了直接计算内部泛化的复杂性。3) 基于IGD的优化目标:通过最小化IGD,使剪枝后的模型能够更好地在内部泛化,从而提升整体的泛化能力。4) 渐进式剪枝策略:根据训练过程中的IGD变化,逐步调整剪枝比例,实现更精细的剪枝。
🖼️ 关键图片
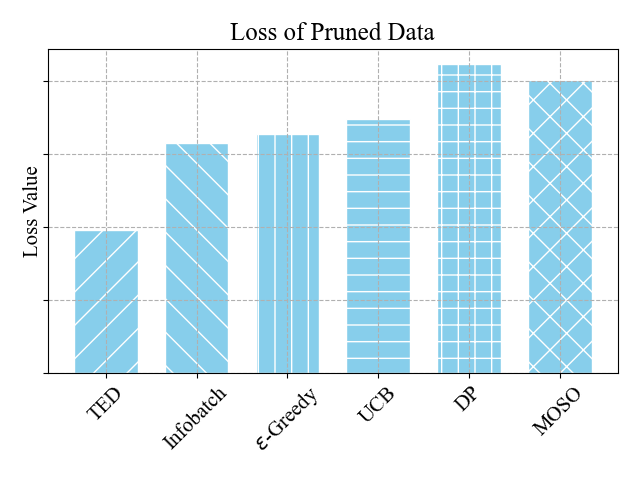
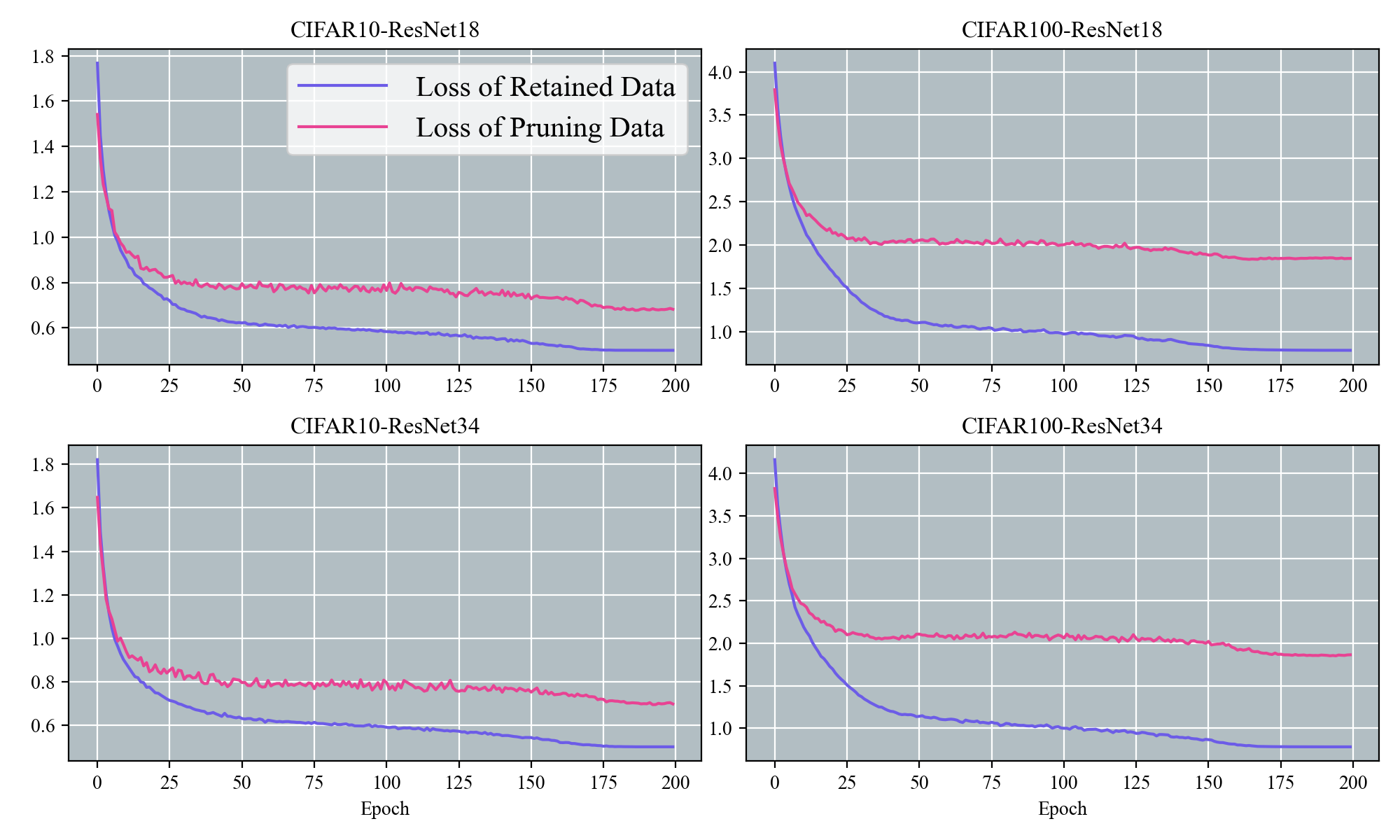
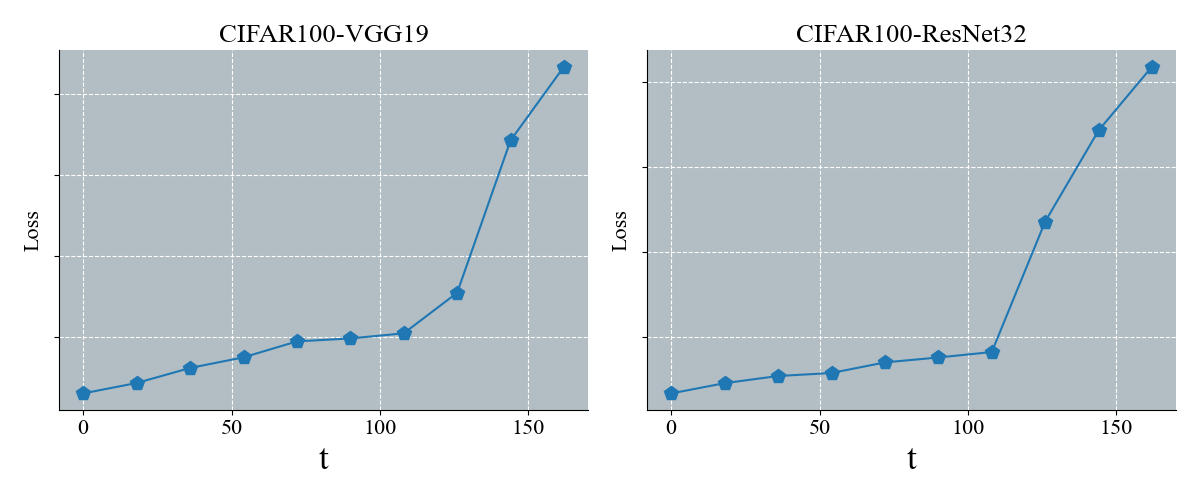
📊 实验亮点
实验结果表明,TED剪枝在图像分类、自然语言理解和大型语言模型微调等任务上均取得了显著效果。在保留60-70%的数据的情况下,TED能够实现与使用完整数据集相当甚至更好的性能,实现了无损甚至有增益的压缩效果。这表明TED能够有效地避免过拟合,提升模型的泛化能力。
🎯 应用场景
TED剪枝方法可应用于各种需要加速模型训练和压缩数据集的场景,例如:资源受限设备上的模型部署、大规模数据集上的模型训练、以及需要快速迭代的模型开发。通过减少训练数据量,可以显著降低计算成本和时间成本,加速AI应用的落地。
📄 摘要(原文)
Large language models have demonstrated strong performance in recent years, but the high cost of training drives the need for efficient methods to compress dataset sizes. We propose TED pruning, a method that addresses the challenge of overfitting under high pruning ratios by quantifying the model's ability to improve performance on pruned data while fitting retained data, known as Internal Generalization (IG). TED uses an optimization objective based on Internal Generalization Distance (IGD), measuring changes in IG before and after pruning to align with true generalization performance and achieve implicit regularization. The IGD optimization objective was verified to allow the model to achieve the smallest upper bound on generalization error. The impact of small mask fluctuations on IG is studied through masks and Taylor approximation, and fast estimation of IGD is enabled. In analyzing continuous training dynamics, the prior effect of IGD is validated, and a progressive pruning strategy is proposed. Experiments on image classification, natural language understanding, and large language model fine-tuning show TED achieves lossless performance with 60-70\% of the data. Upon acceptance, our code will be made publicly available.