Decentralized Online Learning in General-Sum Stackelberg Games
作者: Yaolong Yu, Haipeng Chen
分类: cs.LG
发布日期: 2024-05-06
备注: Accepted for the 40th Conference on Uncertainty in Artificial Intelligence (UAI 2024)
期刊: Proceedings of the Fortieth Conference on Uncertainty in Artificial Intelligence, PMLR 244:4056-4077, 2024
💡 一句话要点
研究一般和Stackelberg博弈中的分散式在线学习,提出信息操纵策略。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: Stackelberg博弈 在线学习 分散式学习 信息操纵 策略学习
📋 核心要点
- 现有分散式在线学习方法在Stackelberg博弈中,未能充分考虑跟随者对领导者奖励信号的操纵。
- 论文提出一种新的跟随者操纵策略,通过战略行动影响领导者的策略收敛,从而获得更好的均衡。
- 理论分析和实验结果表明,该操纵策略在侧信息设置下优于最佳响应策略,具有内在优势。
📝 摘要(中文)
本文研究了一般和Stackelberg博弈中的在线学习问题,其中参与者以分散和战略的方式行动。我们研究了两种设置,具体取决于跟随者的信息类型:(1)有限信息设置,其中跟随者仅观察到自己的奖励;(2)侧信息设置,其中跟随者具有关于领导者奖励的额外侧信息。我们表明,对于跟随者而言,对领导者的行为做出短视的最佳反应是有限信息设置的最佳策略,但对于侧信息设置则不一定如此——跟随者可以通过战略行为操纵领导者的奖励信号,从而引导领导者的策略收敛到对其自身更有利的均衡。基于这些见解,我们研究了两种设置中双方的分散式在线学习。我们的主要贡献是在两种设置中推导出最后一次迭代的收敛性和样本复杂度结果。值得注意的是,我们为后一种设置中的跟随者设计了一种新的操纵策略,并表明它相对于最佳响应策略具有内在优势。我们的理论也得到了经验结果的支持。
🔬 方法详解
问题定义:论文研究一般和Stackelberg博弈中的分散式在线学习问题。现有方法未能充分考虑跟随者利用侧信息操纵领导者奖励信号的可能性,从而可能导致次优结果。特别是在跟随者可以观察到领导者奖励相关信息的情况下,简单地采取最佳响应策略可能不是最优的。
核心思路:论文的核心思路是跟随者可以通过策略性地选择行动,来影响领导者观察到的奖励信号,从而引导领导者的策略向对跟随者更有利的均衡收敛。这种操纵策略的关键在于,跟随者不再仅仅追求当前奖励的最大化,而是考虑其行为对领导者长期策略的影响。
技术框架:论文针对两种信息设置(有限信息和侧信息)分别设计了在线学习算法。在有限信息设置下,跟随者采取最佳响应策略。在侧信息设置下,跟随者采用一种新的操纵策略,该策略基于对领导者学习动态的建模,并选择能够最大化跟随者长期收益的行动。整体框架包括领导者和跟随者两个参与者,他们通过重复博弈进行交互,并根据观察到的奖励和侧信息更新自己的策略。
关键创新:论文的关键创新在于提出了跟随者在侧信息设置下的信息操纵策略。与传统的最佳响应策略不同,该策略考虑了跟随者的行为对领导者学习过程的影响,从而能够引导领导者的策略向对跟随者更有利的均衡收敛。这种策略的提出打破了以往研究中跟随者被动接受领导者策略的假设。
关键设计:论文设计了一种具体的操纵策略,该策略基于对领导者学习算法的建模。具体来说,跟随者需要估计领导者的学习率和奖励函数,并根据这些估计值选择能够最大化其长期收益的行动。该策略的关键参数包括学习率、探索率和时间折扣因子。论文还分析了该策略的收敛性和样本复杂度,并证明了其在特定条件下的最优性。
🖼️ 关键图片
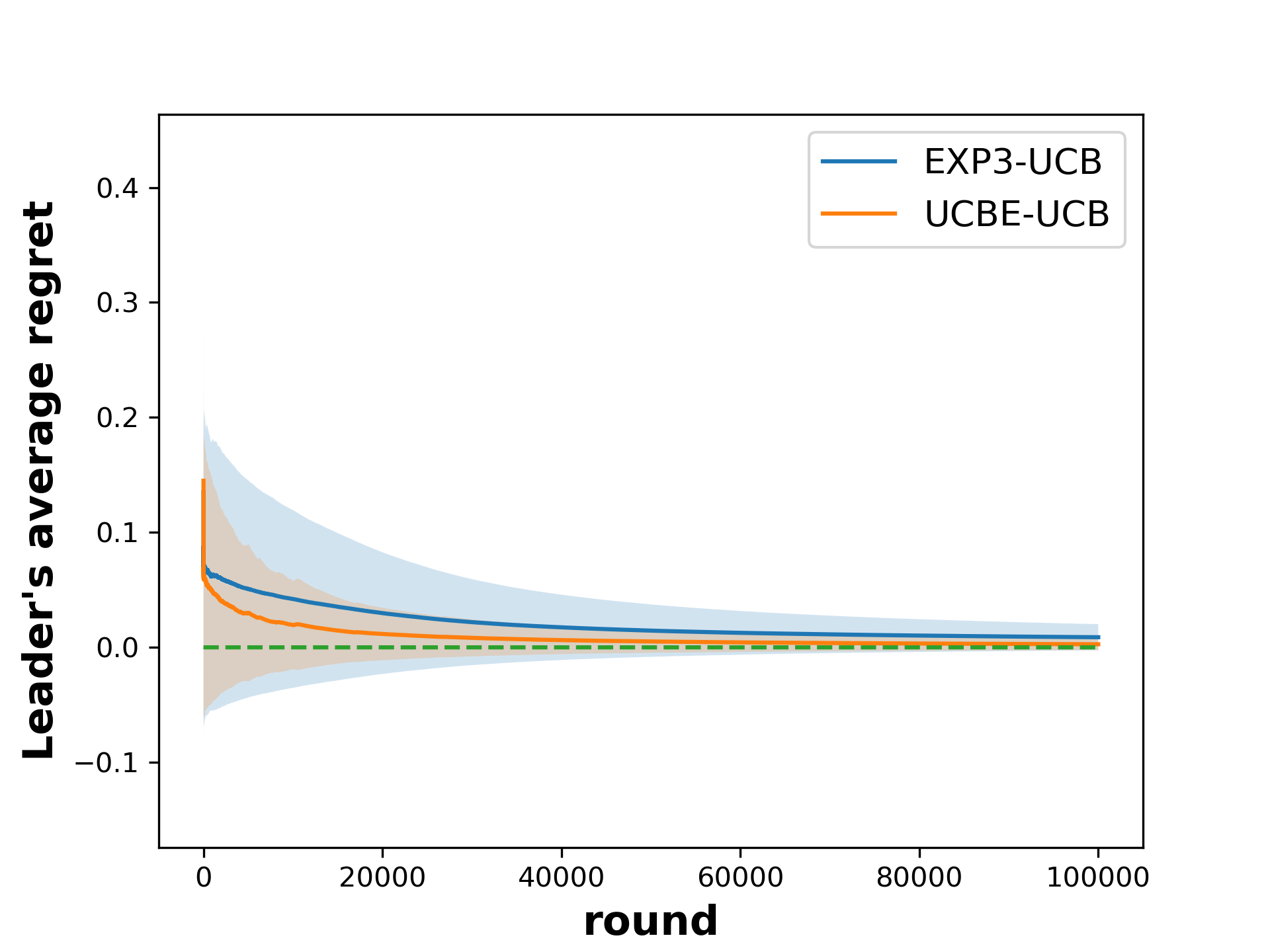
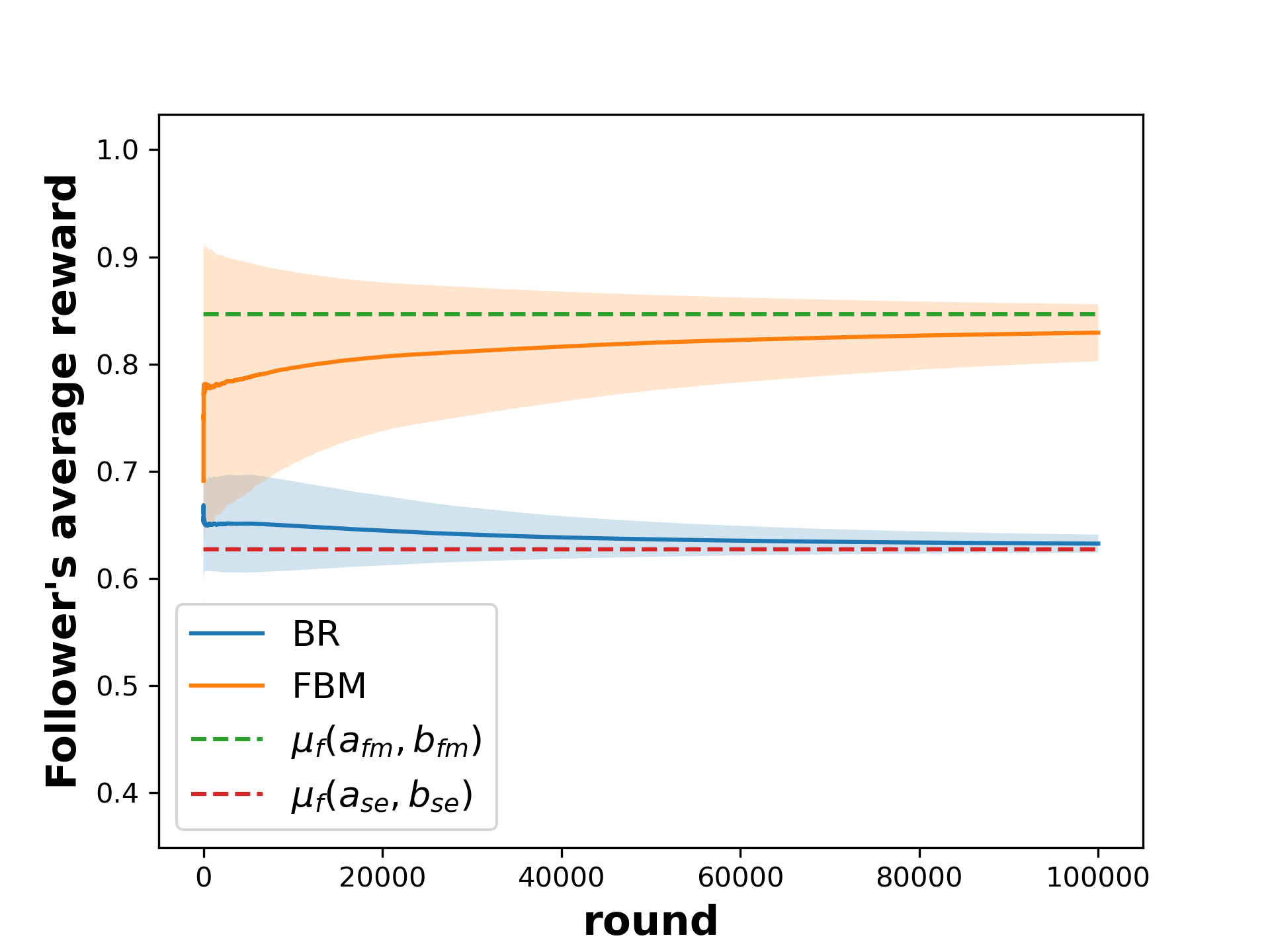
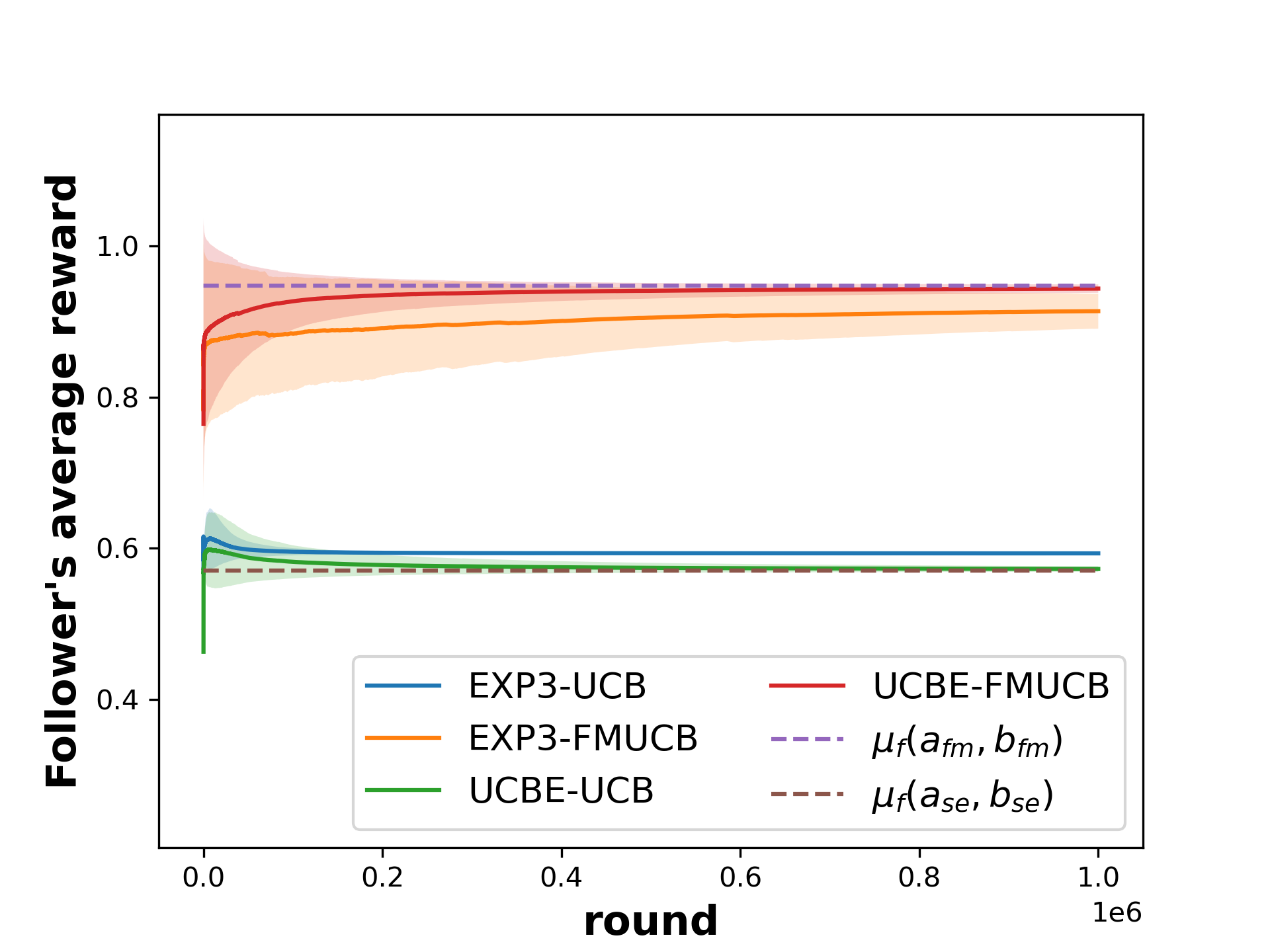
📊 实验亮点
论文在侧信息设置下,通过实验验证了所提出的信息操纵策略的有效性。实验结果表明,与最佳响应策略相比,该操纵策略能够显著提高跟随者的长期收益,并引导领导者的策略向对跟随者更有利的均衡收敛。具体的性能提升幅度取决于博弈的结构和参数设置,但总体趋势是操纵策略优于最佳响应策略。
🎯 应用场景
该研究成果可应用于智能交通、资源分配、网络安全等领域。例如,在智能交通中,跟随者可以是车辆,领导者可以是交通管理系统。车辆可以通过操纵其行为(例如,选择不同的路线)来影响交通管理系统的策略,从而减少拥堵和提高通行效率。在网络安全中,跟随者可以是攻击者,领导者可以是防御系统。攻击者可以通过操纵其攻击行为来影响防御系统的策略,从而提高攻击成功率。
📄 摘要(原文)
We study an online learning problem in general-sum Stackelberg games, where players act in a decentralized and strategic manner. We study two settings depending on the type of information for the follower: (1) the limited information setting where the follower only observes its own reward, and (2) the side information setting where the follower has extra side information about the leader's reward. We show that for the follower, myopically best responding to the leader's action is the best strategy for the limited information setting, but not necessarily so for the side information setting -- the follower can manipulate the leader's reward signals with strategic actions, and hence induce the leader's strategy to converge to an equilibrium that is better off for itself. Based on these insights, we study decentralized online learning for both players in the two settings. Our main contribution is to derive last-iterate convergence and sample complexity results in both settings. Notably, we design a new manipulation strategy for the follower in the latter setting, and show that it has an intrinsic advantage against the best response strategy. Our theories are also supported by empirical results.