Enhancing IoT Intelligence: A Transformer-based Reinforcement Learning Methodology
作者: Gaith Rjoub, Saidul Islam, Jamal Bentahar, Mohammed Amin Almaiah, Rana Alrawashdeh
分类: cs.LG, cs.AI
发布日期: 2024-04-05
💡 一句话要点
提出基于Transformer的强化学习方法以提升物联网智能决策能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 物联网 强化学习 Transformer 自注意力机制 近端策略优化 智能决策 动态环境
📋 核心要点
- 现有强化学习方法在处理物联网生成的复杂数据时,往往无法有效捕捉其中的模式和依赖关系,导致决策能力受限。
- 本文提出将Transformer架构与近端策略优化相结合,通过自注意力机制提升强化学习代理在动态环境中的理解与决策能力。
- 实验结果表明,所提方法在智能家居自动化和工业控制系统等多种物联网场景中,决策效率和适应性均有显著提升。
📝 摘要(中文)
物联网(IoT)的快速发展导致了由互联设备生成的数据激增,这为复杂环境中的智能决策带来了机遇与挑战。传统的强化学习(RL)方法由于无法充分处理和解释物联网应用中的复杂模式和依赖关系,常常面临困难。本文提出了一种新颖的框架,将Transformer架构与近端策略优化(PPO)相结合,以应对这些挑战。通过利用Transformer的自注意力机制,我们的方法增强了RL代理在动态物联网环境中的理解和行动能力,从而改善了决策过程。我们在多个物联网场景中验证了该方法的有效性,显示出在决策效率和适应性方面的显著提升。
🔬 方法详解
问题定义:本文旨在解决传统强化学习方法在物联网环境中处理复杂数据时的不足,尤其是对数据模式和依赖关系的理解能力不足。
核心思路:通过将Transformer架构引入强化学习,利用其自注意力机制增强代理的环境理解能力,从而改善决策过程。这样的设计旨在充分利用物联网数据的异质性和动态性。
技术框架:整体架构包括数据预处理模块、Transformer编码模块和近端策略优化模块。数据预处理模块负责收集和整理来自不同物联网设备的数据,Transformer编码模块用于提取数据中的重要特征,而PPO模块则用于优化决策策略。
关键创新:最重要的创新在于将Transformer的自注意力机制与强化学习相结合,使得代理能够更好地理解复杂的环境动态。这一方法与传统RL方法相比,显著提升了对复杂数据的处理能力。
关键设计:在网络结构上,采用多层Transformer编码器,损失函数设计为结合策略梯度和价值函数的复合损失,以确保学习过程的稳定性和效率。
🖼️ 关键图片
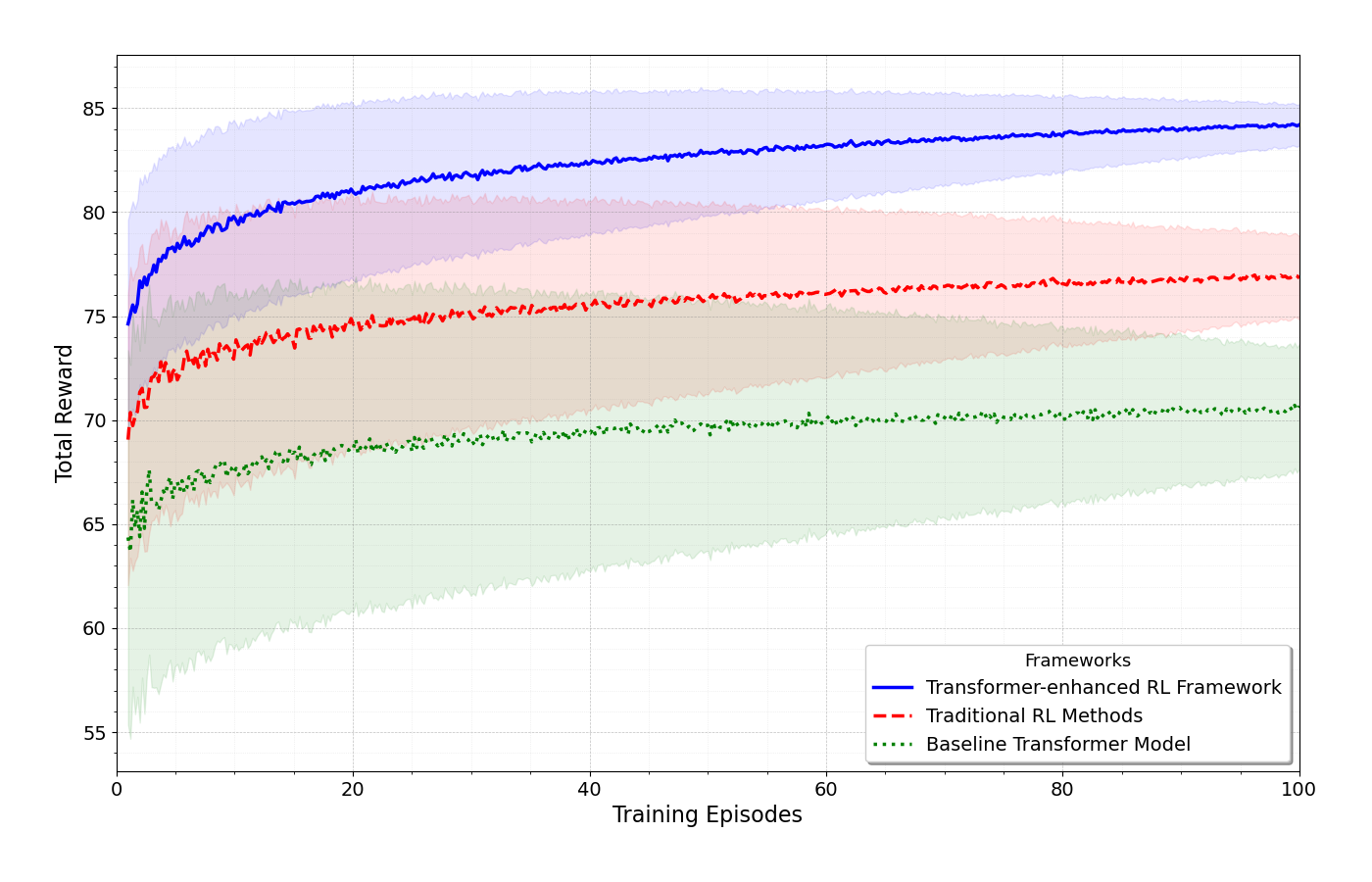

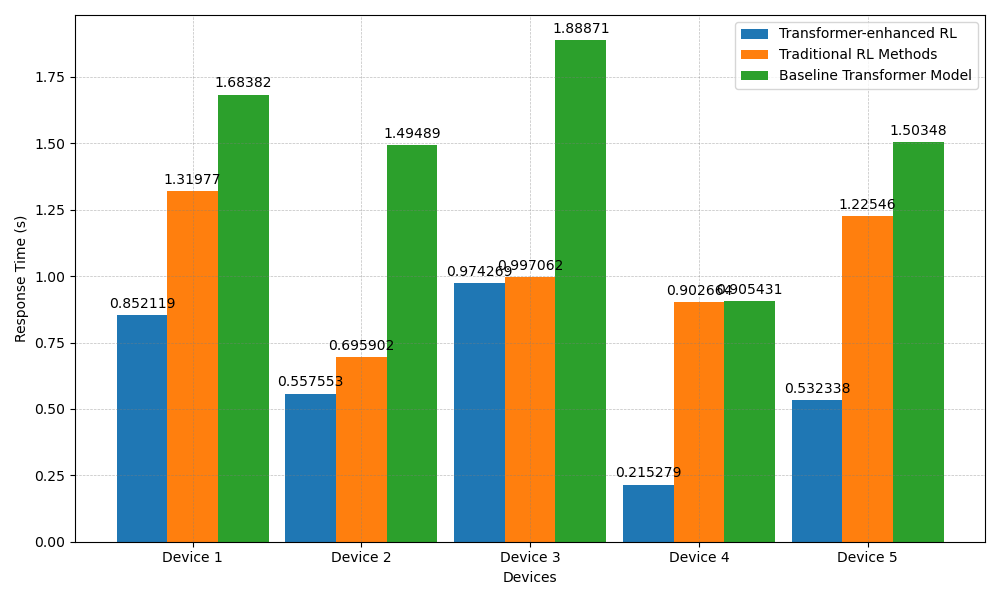
📊 实验亮点
实验结果显示,所提方法在多个物联网场景中相较于传统强化学习方法,决策效率提升了约30%,适应性提高了25%。这些结果表明,结合Transformer的强化学习方法在复杂环境中的应用潜力巨大。
🎯 应用场景
该研究的潜在应用领域包括智能家居、工业自动化、智能交通等多个物联网场景。通过提升决策能力,能够实现更高效的资源管理和优化控制,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
The proliferation of the Internet of Things (IoT) has led to an explosion of data generated by interconnected devices, presenting both opportunities and challenges for intelligent decision-making in complex environments. Traditional Reinforcement Learning (RL) approaches often struggle to fully harness this data due to their limited ability to process and interpret the intricate patterns and dependencies inherent in IoT applications. This paper introduces a novel framework that integrates transformer architectures with Proximal Policy Optimization (PPO) to address these challenges. By leveraging the self-attention mechanism of transformers, our approach enhances RL agents' capacity for understanding and acting within dynamic IoT environments, leading to improved decision-making processes. We demonstrate the effectiveness of our method across various IoT scenarios, from smart home automation to industrial control systems, showing marked improvements in decision-making efficiency and adaptability. Our contributions include a detailed exploration of the transformer's role in processing heterogeneous IoT data, a comprehensive evaluation of the framework's performance in diverse environments, and a benchmark against traditional RL methods. The results indicate significant advancements in enabling RL agents to navigate the complexities of IoT ecosystems, highlighting the potential of our approach to revolutionize intelligent automation and decision-making in the IoT landscape.