Methodology for Interpretable Reinforcement Learning for Optimizing Mechanical Ventilation
作者: Joo Seung Lee, Malini Mahendra, Anil Aswani
分类: cs.LG, math.OC
发布日期: 2024-04-03 (更新: 2025-01-09)
💡 一句话要点
提出可解释的强化学习方法以优化机械通气控制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机械通气 可解释强化学习 决策树 个性化医疗 重症监护 数据驱动决策 因果模型 离线策略评估
📋 核心要点
- 现有的数据驱动方法在优化机械通气控制策略时缺乏可解释性,限制了其在临床中的应用。
- 本文提出了一种基于可解释强化学习的方法,通过因果模型评估策略,旨在提高患者的血氧水平。
- 实验结果表明,所提出的可解释决策树策略在性能上与深度强化学习方法相当,并优于传统的行为克隆方法。
📝 摘要(中文)
机械通气是关键的生命支持干预措施,能够向患者的肺部提供控制的空气和氧气,辅助或替代自发呼吸。尽管已有多种数据驱动的方法被提出以优化通气器控制策略,但它们往往缺乏可解释性和与领域知识的一致性,阻碍了临床应用。本文提出了一种可解释的强化学习方法,旨在改善机械通气控制,作为连接健康系统的一部分。通过因果的非参数模型基础的离线策略评估,我们评估了强化学习策略在提高患者特定结果(特别是增加血氧水平)方面的能力,同时避免可能导致通气器诱导肺损伤的激进通气设置。通过对MIMIC-III数据库中的真实ICU数据进行数值实验,我们证明了我们的可解释决策树策略在性能上与最先进的深度强化学习方法相当,同时优于标准的行为克隆方法。结果突显了可解释的数据驱动决策支持系统在个性化通气策略中提高安全性和效率的潜力,为无缝集成到连接医疗环境中铺平了道路。
🔬 方法详解
问题定义:本文旨在解决现有机械通气控制策略缺乏可解释性的问题,导致临床应用受限。现有方法往往无法与领域知识对齐,影响了医生的决策信心。
核心思路:提出了一种可解释的强化学习方法,利用因果非参数模型进行离线策略评估,重点关注提高患者特定的血氧水平,同时避免激进的通气设置。
技术框架:整体架构包括数据收集、因果模型构建、策略评估和决策树生成四个主要模块。数据来自真实的ICU环境,模型通过离线评估优化策略。
关键创新:最重要的创新在于将可解释性与强化学习结合,提出了一种新的决策树策略,能够在保证性能的同时提供可解释的决策依据,与传统的深度学习方法形成鲜明对比。
关键设计:在模型设计中,采用了特定的损失函数来平衡血氧水平的提高与通气设置的安全性,决策树的构建则基于患者的具体数据,确保了策略的个性化和可解释性。
🖼️ 关键图片
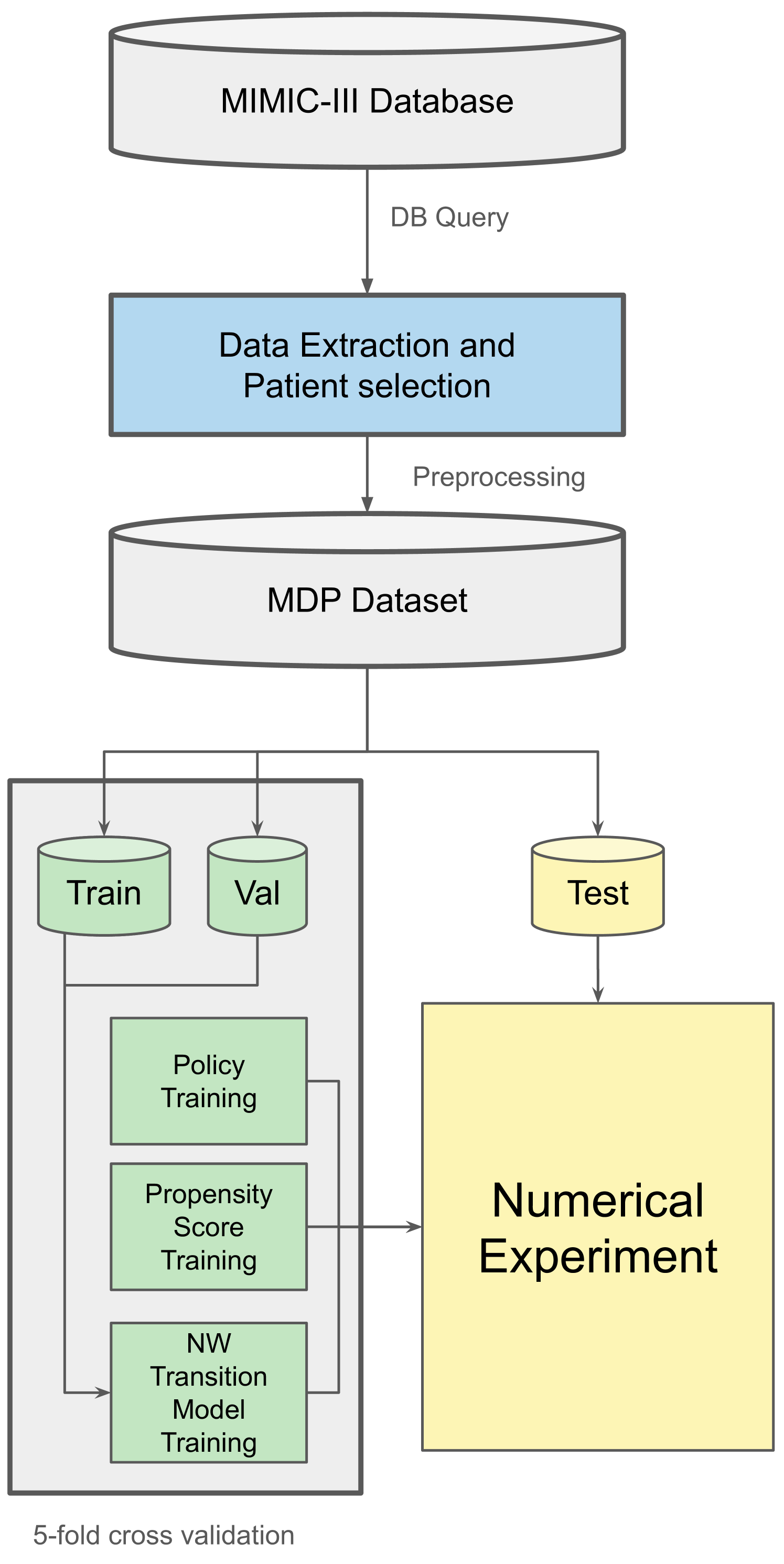

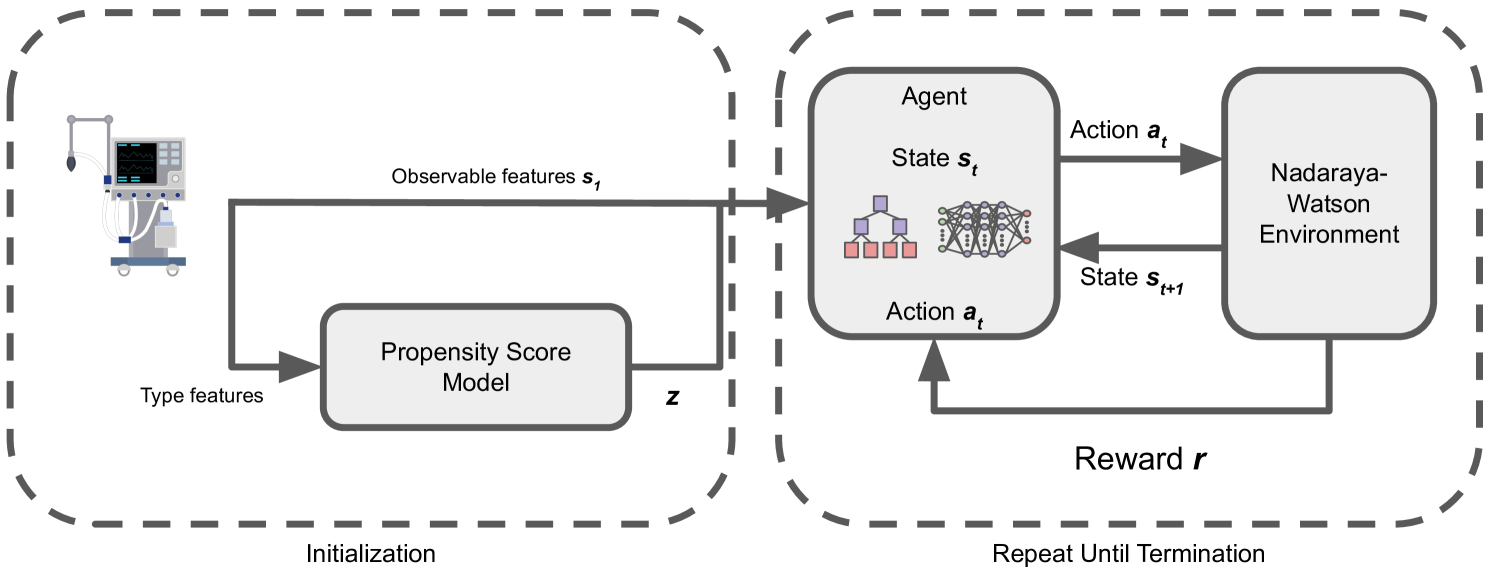
📊 实验亮点
实验结果显示,所提出的可解释决策树策略在提高血氧水平方面表现出色,其性能与最先进的深度强化学习方法相当,同时在标准行为克隆方法上实现了显著的性能提升,具体提升幅度未知。
🎯 应用场景
该研究具有广泛的应用潜力,特别是在重症监护和个性化医疗领域。通过提供可解释的决策支持,医生可以更好地理解和信任通气策略,从而提高患者的安全性和治疗效果。未来,该方法有望与其他健康监测系统集成,进一步提升医疗服务的质量。
📄 摘要(原文)
Mechanical ventilation is a critical life support intervention that delivers controlled air and oxygen to a patient's lungs, assisting or replacing spontaneous breathing. While several data-driven approaches have been proposed to optimize ventilator control strategies, they often lack interpretability and alignment with domain knowledge, hindering clinical adoption. This paper presents a methodology for interpretable reinforcement learning (RL) aimed at improving mechanical ventilation control as part of connected health systems. Using a causal, nonparametric model-based off-policy evaluation, we assess RL policies for their ability to enhance patient-specific outcomes-specifically, increasing blood oxygen levels (SpO2), while avoiding aggressive ventilator settings that may cause ventilator-induced lung injuries and other complications. Through numerical experiments on real-world ICU data from the MIMIC-III database, we demonstrate that our interpretable decision tree policy achieves performance comparable to state-of-the-art deep RL methods while outperforming standard behavior cloning approaches. The results highlight the potential of interpretable, data-driven decision support systems to improve safety and efficiency in personalized ventilation strategies, paving the way for seamless integration into connected healthcare environments.