PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
作者: Fanxu Meng, Zhaohui Wang, Muhan Zhang
分类: cs.LG, cs.AI
发布日期: 2024-04-03 (更新: 2025-04-09)
备注: NeurIPS 2024 spotlight
🔗 代码/项目: GITHUB
💡 一句话要点
提出PiSSA以加速大语言模型的参数高效微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 低秩适应 主成分分析 微调技术 自然语言处理 模型优化 量化技术
📋 核心要点
- 现有的LoRA方法在微调过程中收敛速度较慢,限制了其在实际应用中的效率。
- 本文提出的PiSSA方法通过主成分初始化适配器矩阵,允许在冻结残差部分的同时更新主成分,从而加速收敛。
- 在多个模型和任务上的实验结果显示,PiSSA在性能上显著优于LoRA,尤其在GSM8K基准测试中表现突出。
📝 摘要(中文)
为高效微调大语言模型(LLMs),低秩适应(LoRA)方法通过两个矩阵的乘积来近似模型变化。然而,LoRA在更新适配器时可能导致收敛速度慢。为此,本文提出了主奇异值和奇异向量适应(PiSSA),该方法通过将适配器矩阵初始化为原始矩阵的主成分来加速收敛。实验表明,PiSSA在12个不同模型上均优于LoRA,特别是在GSM8K基准测试中,Mistral-7B的准确率达到72.86%,超出LoRA的67.7%。此外,PiSSA与量化兼容,能够进一步降低微调的内存需求。
🔬 方法详解
问题定义:本文旨在解决现有LoRA方法在微调大语言模型时收敛速度慢的问题。LoRA通过固定原始模型并更新适配器,导致模型更新效率低下。
核心思路:PiSSA方法的核心在于使用原始模型的主成分初始化适配器矩阵,从而在更新主成分的同时冻结残差部分,提升收敛速度和性能。
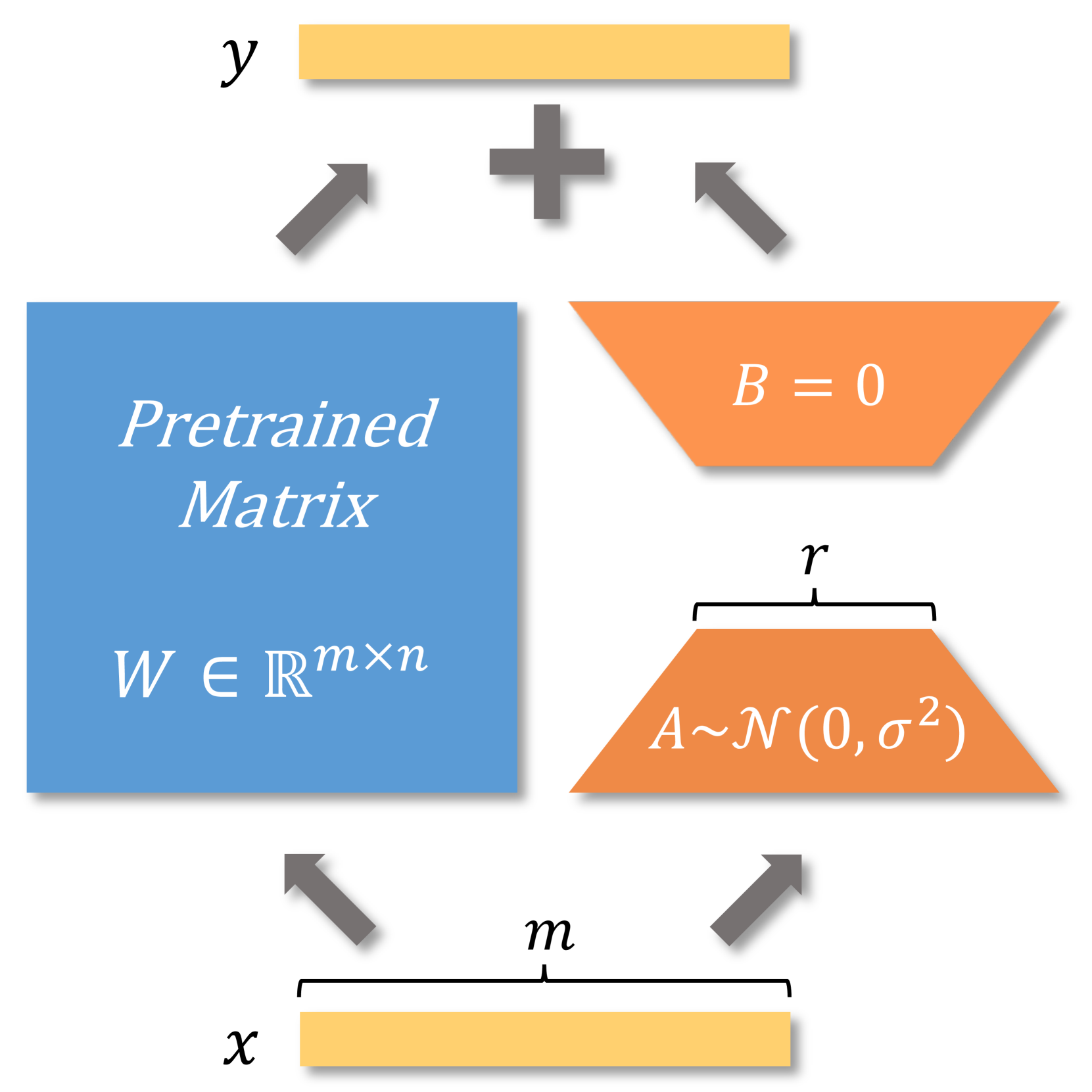
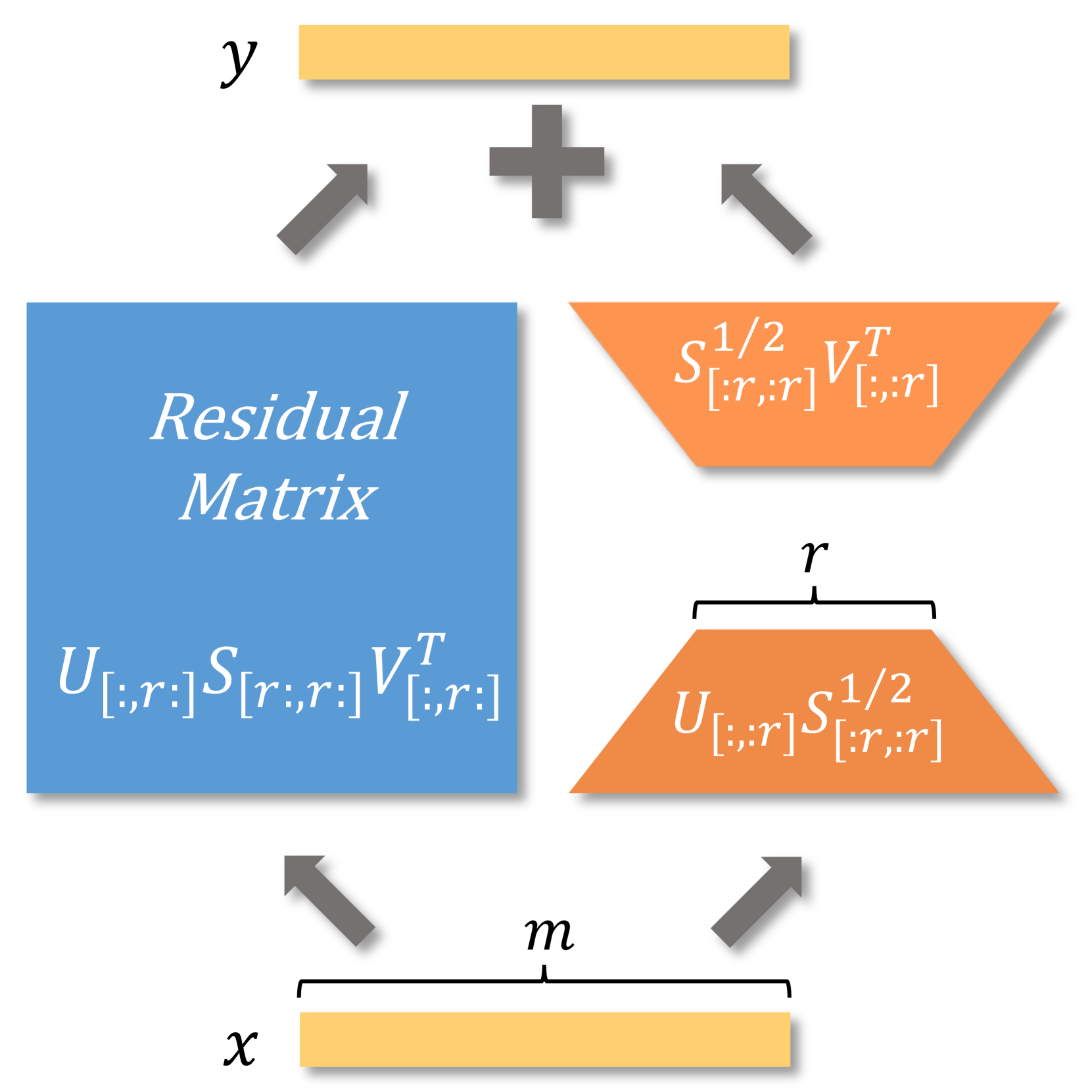
技术框架:PiSSA与LoRA共享相同的架构,主要模块包括初始化适配器矩阵、冻结残差矩阵和更新主成分。通过快速的奇异值分解(SVD)技术,PiSSA能够在几秒钟内完成初始化。
关键创新:PiSSA的主要创新在于通过主成分适应来替代LoRA的随机初始化,显著提高了模型的收敛速度和最终性能。
关键设计:在参数设置上,适配器矩阵A和B分别初始化为原始矩阵W的主成分和零矩阵,残差矩阵W^{res}则保持冻结状态,确保在微调过程中有效利用主成分信息。
🖼️ 关键图片

📊 实验亮点
在GSM8K基准测试中,使用PiSSA微调的Mistral-7B模型达到了72.86%的准确率,超出LoRA的67.7%高出5.16%。此外,QPiSSA在量化初期表现出更小的量化误差,进一步提升了微调效率和模型性能。
🎯 应用场景
PiSSA方法在自然语言处理任务中具有广泛的应用潜力,尤其是在需要快速适应新任务的场景中。其高效的微调能力和与量化的兼容性,使得在资源受限的环境中也能实现高性能的模型应用,推动了大语言模型在实际应用中的普及和发展。
📄 摘要(原文)
To parameter-efficiently fine-tune (PEFT) large language models (LLMs), the low-rank adaptation (LoRA) method approximates the model changes $ΔW \in \mathbb{R}^{m \times n}$ through the product of two matrices $A \in \mathbb{R}^{m \times r}$ and $B \in \mathbb{R}^{r \times n}$, where $r \ll \min(m, n)$, $A$ is initialized with Gaussian noise, and $B$ with zeros. LoRA freezes the original model $W$ and updates the "Noise & Zero" adapter, which may lead to slow convergence. To overcome this limitation, we introduce Principal Singular values and Singular vectors Adaptation (PiSSA). PiSSA shares the same architecture as LoRA, but initializes the adaptor matrices $A$ and $B$ with the principal components of the original matrix $W$, and put the remaining components into a residual matrix $W^{res} \in \mathbb{R}^{m \times n}$ which is frozen during fine-tuning. Compared to LoRA, PiSSA updates the principal components while freezing the "residual" parts, allowing faster convergence and enhanced performance. Comparative experiments of PiSSA and LoRA across 12 different models, ranging from 184M to 70B, encompassing 5 NLG and 8 NLU tasks, reveal that PiSSA consistently outperforms LoRA under identical experimental setups. On the GSM8K benchmark, Mistral-7B fine-tuned with PiSSA achieves an accuracy of 72.86%, surpassing LoRA's 67.7% by 5.16%. Due to the same architecture, PiSSA is also compatible with quantization to further reduce the memory requirement of fine-tuning. Compared to QLoRA, QPiSSA exhibits smaller quantization errors in the initial stages. Fine-tuning LLaMA-3-70B on GSM8K, QPiSSA attains an accuracy of 86.05%, exceeding the performances of QLoRA at 81.73%. Leveraging a fast SVD technique, PiSSA can be initialized in only a few seconds, presenting a negligible cost for transitioning from LoRA to PiSSA. Code is available at https://github.com/GraphPKU/PiSSA.