Foundation Models for Structural Health Monitoring
作者: Luca Benfenati, Daniele Jahier Pagliari, Luca Zanatta, Yhorman Alexander Bedoya Velez, Andrea Acquaviva, Massimo Poncino, Enrico Macii, Luca Benini, Alessio Burrello
分类: cs.LG, cs.AI, eess.SY
发布日期: 2024-04-03 (更新: 2025-10-09)
备注: 17 pages, 6 tables, 9 figures
DOI: 10.1109/TSUSC.2025.3592097
💡 一句话要点
提出Transformer神经网络作为结构健康监测的基础模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 结构健康监测 Transformer 自监督学习 异常检测 交通负载估计 知识蒸馏 深度学习
📋 核心要点
- 现有的结构健康监测方法在准确性和实时性上存在不足,传统技术难以处理复杂的监测任务。
- 本文提出使用Transformer神经网络,结合自监督学习和任务特定微调,提升SHM的表现。
- 实验结果显示,所提模型在异常检测和交通负载估计任务上均超越了现有最优方法,表现出显著的性能提升。
📝 摘要(中文)
结构健康监测(SHM)是确保土木基础设施安全性和可靠性的关键任务,通常通过振动监测实现。本文首次提出使用Transformer神经网络,结合掩码自编码器架构,作为SHM的基础模型。我们展示了这些模型通过自监督预训练从多个大型数据集中学习可泛化表示的能力,结合任务特定的微调,使其在异常检测和交通负载估计等多种任务上超越传统方法。我们还深入探讨了模型大小与准确性之间的权衡,并实验知识蒸馏以提升小型Transformer的性能,使其能够直接嵌入SHM边缘节点。通过对三座运营高架桥的数据进行验证,我们在异常检测中实现了99.9%的近乎完美准确率,而基于主成分分析的传统方法仅为95.03%。
🔬 方法详解
问题定义:本文旨在解决结构健康监测中传统方法的准确性和实时性不足的问题。现有方法如主成分分析在处理复杂数据时表现不佳,难以满足实际应用需求。
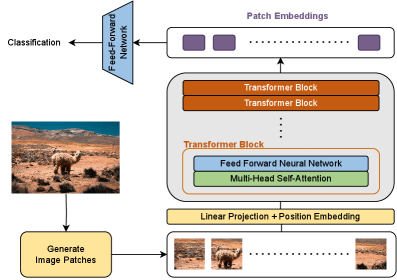
核心思路:论文提出使用Transformer神经网络,结合掩码自编码器架构,通过自监督学习从多个大型数据集中学习可泛化的表示,进而提升SHM的性能。
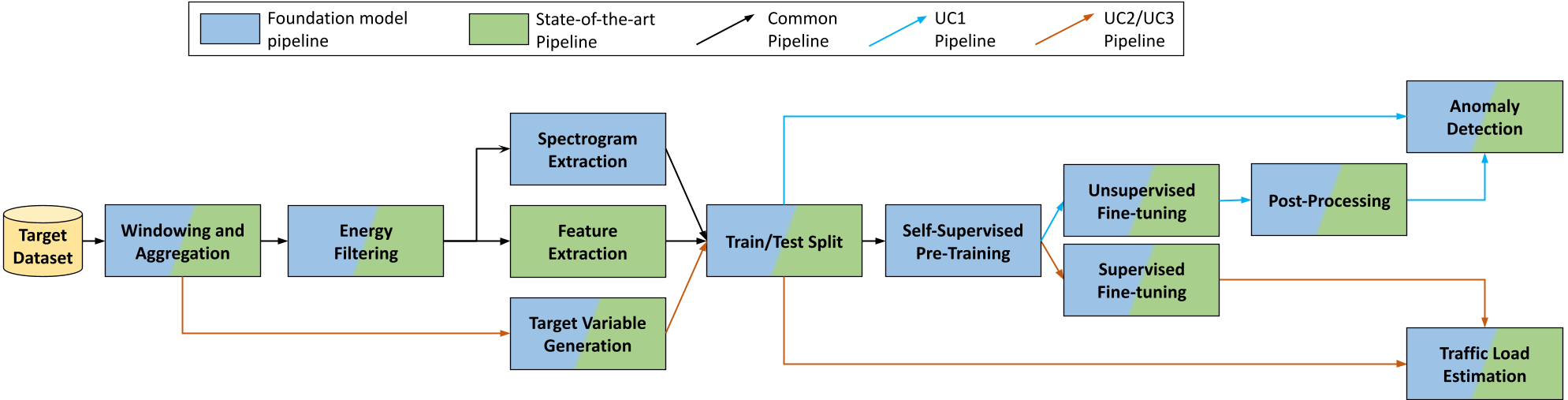
技术框架:整体架构包括自监督预训练和任务特定微调两个阶段。首先,模型在大规模数据集上进行预训练,然后针对具体任务进行微调,以优化性能。
关键创新:最重要的创新在于将Transformer应用于SHM领域,利用其强大的表示学习能力,显著提升了异常检测和交通负载估计的准确性。与传统方法相比,本文方法在处理复杂数据时表现出更好的泛化能力。
关键设计:在模型设计上,采用了掩码自编码器架构,并通过知识蒸馏技术优化小型Transformer的性能,确保其能够有效嵌入SHM边缘节点。
🖼️ 关键图片

📊 实验亮点
在实验中,我们的模型在异常检测任务中实现了99.9%的准确率,仅需15个监测窗口,而传统方法在120个窗口下的准确率为95.03%。在交通负载估计任务中,我们的模型在多个评估指标上均表现出色,R²得分分别达到0.97和0.90,显著超越了现有最佳方法。
🎯 应用场景
该研究的潜在应用领域包括桥梁、隧道等土木基础设施的实时监测与维护。通过提高监测的准确性和效率,可以显著降低维护成本,延长基础设施的使用寿命,提升公共安全。未来,该技术有望推广至更广泛的工程监测领域。
📄 摘要(原文)
Structural Health Monitoring (SHM) is a critical task for ensuring the safety and reliability of civil infrastructures, typically realized on bridges and viaducts by means of vibration monitoring. In this paper, we propose for the first time the use of Transformer neural networks, with a Masked Auto-Encoder architecture, as Foundation Models for SHM. We demonstrate the ability of these models to learn generalizable representations from multiple large datasets through self-supervised pre-training, which, coupled with task-specific fine-tuning, allows them to outperform state-of-the-art traditional methods on diverse tasks, including Anomaly Detection (AD) and Traffic Load Estimation (TLE). We then extensively explore model size versus accuracy trade-offs and experiment with Knowledge Distillation (KD) to improve the performance of smaller Transformers, enabling their embedding directly into the SHM edge nodes. We showcase the effectiveness of our foundation models using data from three operational viaducts. For AD, we achieve a near-perfect 99.9% accuracy with a monitoring time span of just 15 windows. In contrast, a state-of-the-art method based on Principal Component Analysis (PCA) obtains its first good result (95.03% accuracy), only considering 120 windows. On two different TLE tasks, our models obtain state-of-the-art performance on multiple evaluation metrics (R$^2$ score, MAE% and MSE%). On the first benchmark, we achieve an R$^2$ score of 0.97 and 0.90 for light and heavy vehicle traffic, respectively, while the best previous approach (a Random Forest) stops at 0.91 and 0.84. On the second one, we achieve an R$^2$ score of 0.54 versus the 0.51 of the best competitor method, a Long-Short Term Memory network.