How Sparse Attention Approximates Exact Attention? Your Attention is Naturally $n^C$-Sparse
作者: Yichuan Deng, Zhao Song, Jing Xiong, Chiwun Yang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2024-04-03 (更新: 2025-02-12)
💡 一句话要点
提出稀疏注意力理论框架以优化传统注意力计算
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 大型语言模型 理论框架 自适应策略 计算效率 自然语言处理 深度学习
📋 核心要点
- 现有的稀疏注意力方法缺乏理论支持,无法明确其在何种条件下能与传统注意力相媲美。
- 本文提出了一种理论框架,揭示了标准注意力过程的内在稀疏性,并提出了自适应窗口大小策略。
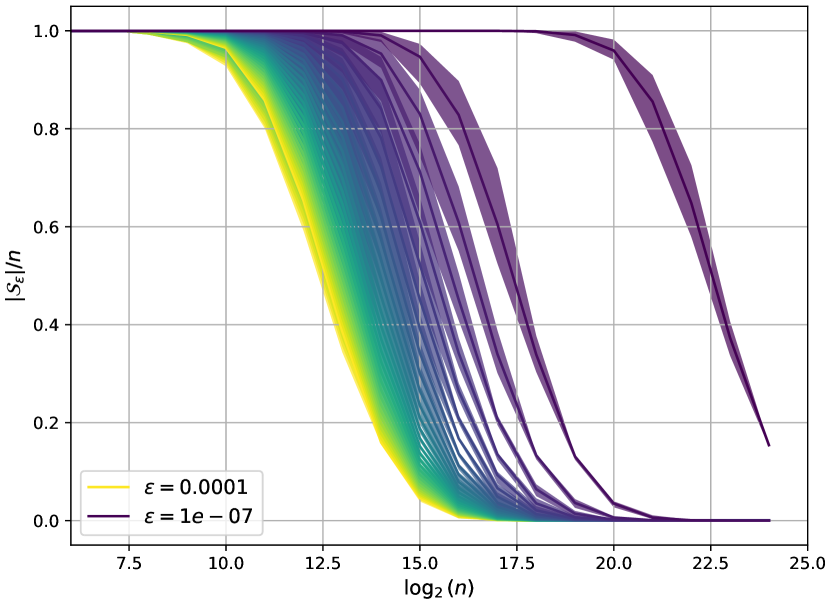
- 研究表明,考虑最大的$Ω(n^{C})$条目足以近似精确注意力,且稳定的稀疏注意力可能存在误差下限。
📝 摘要(中文)
稀疏注意力是一种通过选择性忽略注意力矩阵中较小的条目来近似标准注意力计算的技术,从而实现亚平方复杂度。尽管稀疏注意力在大型语言模型的高效部署中得到了广泛应用,但其理论基础尚不明确。本文旨在通过研究标准注意力过程的内在稀疏性来填补这一空白,提出了几个关键见解,包括注意力是$n^{C}$-稀疏的,稳定的$o( ext{log}(n))$-稀疏注意力可能不可行,以及自适应窗口大小策略的有效性。
🔬 方法详解
问题定义:本文旨在解决稀疏注意力在理论上的不足,尤其是缺乏对其性能与传统注意力比较的明确条件的理解。现有方法在应用中常常面临效率与准确性之间的权衡。
核心思路:论文通过分析标准注意力的内在稀疏性,提出了注意力是$n^{C}$-稀疏的理论,强调只需考虑最大的$Ω(n^{C})$条目即可有效近似精确注意力。
技术框架:整体架构包括对标准注意力的稀疏性分析、误差评估以及自适应窗口大小策略的设计。主要模块包括理论分析、实验验证和策略优化。
关键创新:最重要的创新在于提出了注意力的稀疏性理论框架,明确了稀疏注意力的有效性条件,与传统方法相比,提供了更深层次的理论支持。
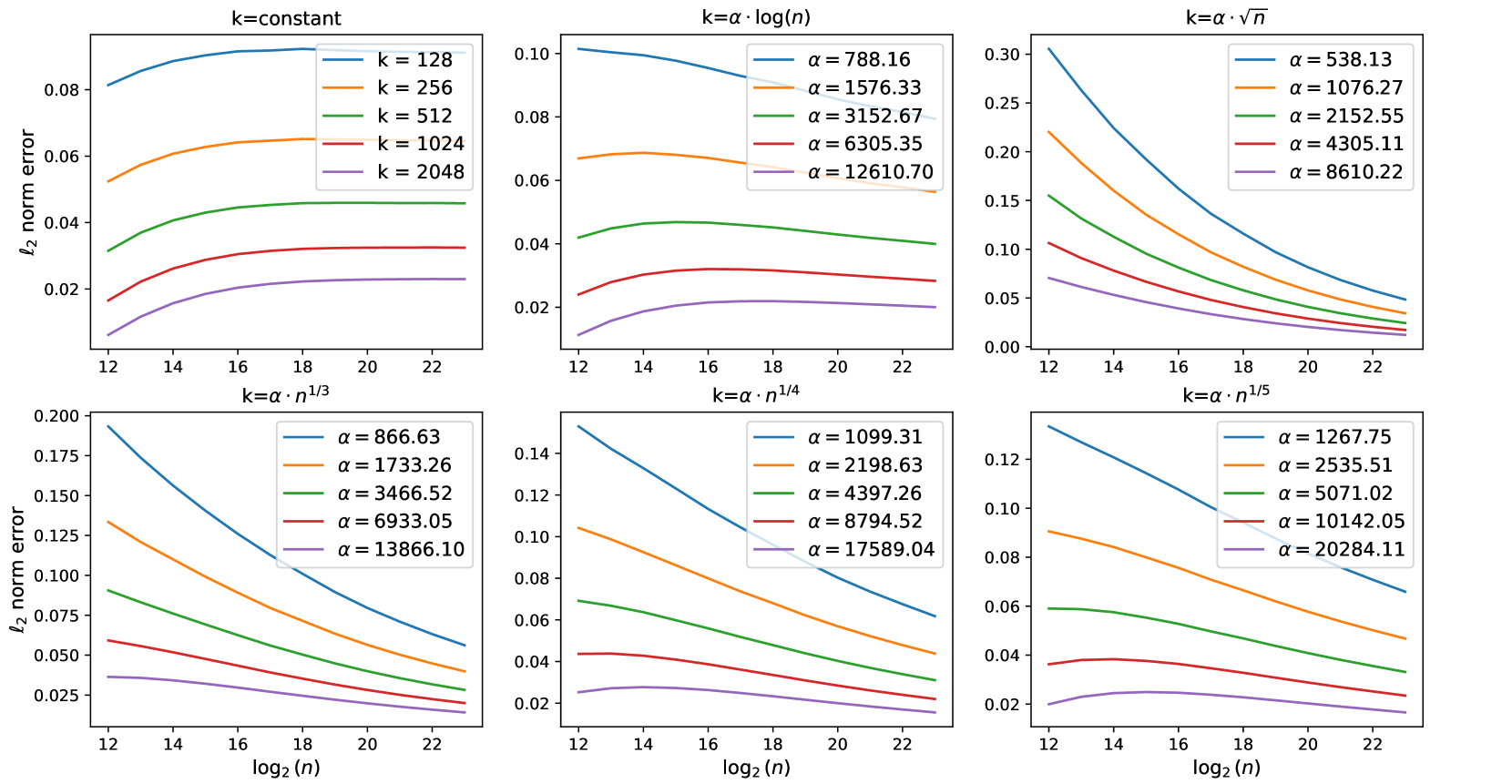
关键设计:论文中设计了自适应策略来动态调整窗口大小,避免了固定窗口带来的效率损失,同时在实验中验证了该策略在不同上下文长度下的有效性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,采用自适应窗口大小策略的稀疏注意力在多个任务中表现出更高的准确性和效率,相较于传统方法,误差降低了至少$O(1)$,并且在处理长序列时性能显著提升。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、计算机视觉和机器人等需要高效注意力机制的任务。通过优化注意力计算,能够显著提升大型语言模型的推理效率和准确性,推动智能系统在复杂场景中的应用。
📄 摘要(原文)
Sparse Attention is a technique that approximates standard attention computation with sub-quadratic complexity. This is achieved by selectively ignoring smaller entries in the attention matrix during the softmax function computation. Variations of this technique, such as pruning KV cache, sparsity-based fast attention, and Sparse Transformer, have been extensively utilized for efficient Large Language Models (LLMs) deployment. Despite its widespread use, a theoretical understanding of the conditions under which sparse attention performs on par with traditional attention remains elusive. This work aims to $\textbf{bridge this gap by examining the inherent sparsity of standard attention processes}$. Our theoretical framework reveals several brand-new key insights: $\bullet$ Attention is $n^{C}$-sparse, implying that considering only the largest $Ω(n^{C})$ entries out of all $n$ entries is sufficient for sparse attention to approximate the exact attention matrix with decreasing loss. Here, $n$ represents the input length and $C \in (0, 1)$ is a constant. $\bullet$ Stable $o(\log(n))$-sparse attention, which approximates attention computation with $\log(n)$ or fewer entries, may not be feasible since the error will persist at a minimum of $O(1)$. $\bullet$ An adaptive strategy ($α\cdot n^C, α\in \mathbb{R}$) for the window size of efficient attention methods rather than a fixed one is guaranteed to perform more accurately and efficiently in a task for inference on flexible context lengths.