Solving a Real-World Optimization Problem Using Proximal Policy Optimization with Curriculum Learning and Reward Engineering
作者: Abhijeet Pendyala, Asma Atamna, Tobias Glasmachers
分类: cs.LG
发布日期: 2024-04-03 (更新: 2024-07-23)
💡 一句话要点
提出基于PPO的课程学习与奖励工程以优化废物分类问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 近端策略优化 课程学习 奖励工程 废物分类 多目标优化 智能决策 自动化
📋 核心要点
- 现有方法在处理复杂的废物分类问题时,难以平衡操作安全性、体积优化和资源使用等多个目标。
- 论文提出通过课程学习和奖励工程相结合的方式,逐步提高环境复杂性,帮助代理学习最优策略。
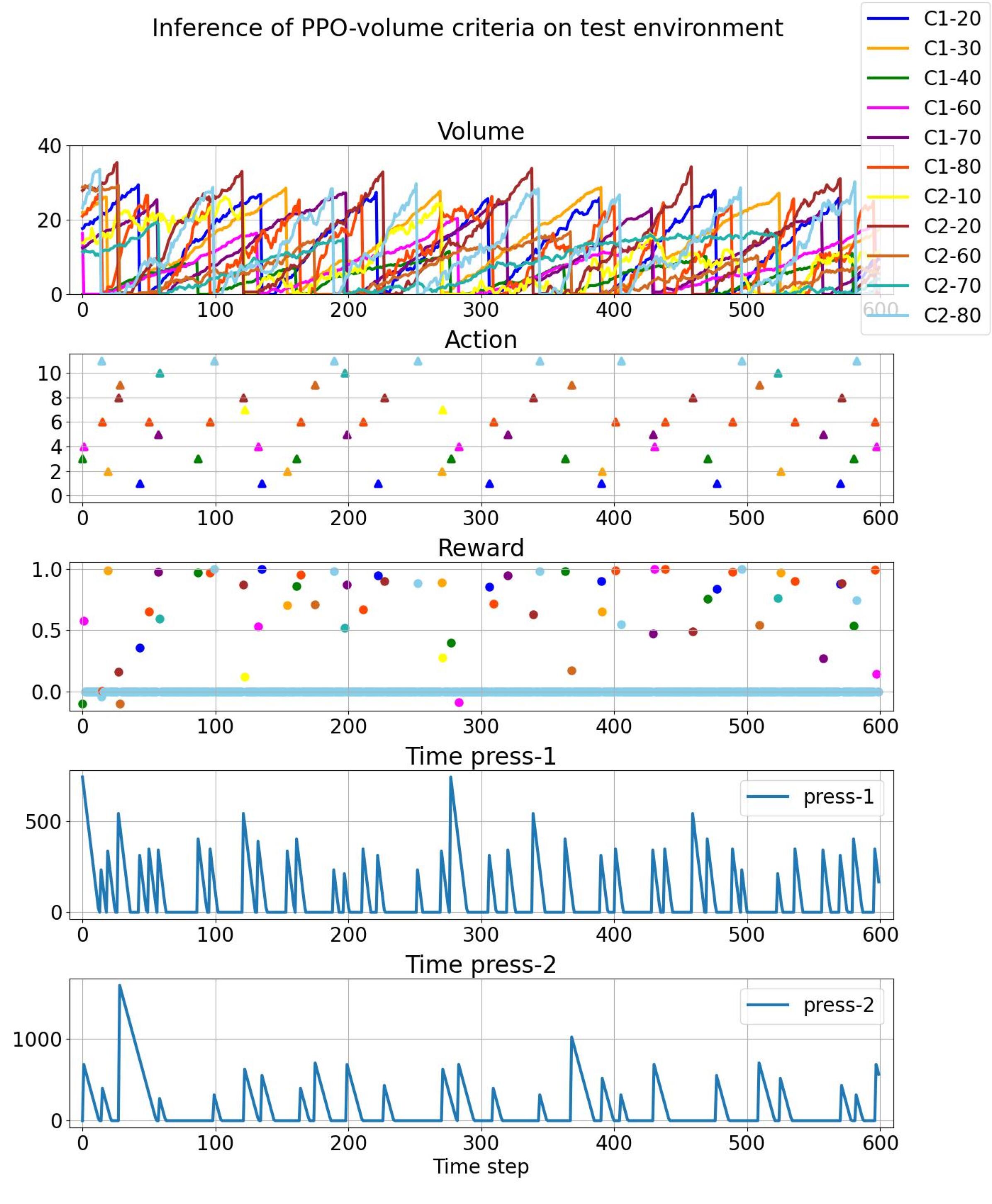
- 实验结果显示,该方法在推理时实现了近零安全违规,并显著提升了废物分类的效率。
📝 摘要(中文)
本文提出了一种通过课程学习原则和精细化奖励工程训练的近端策略优化(PPO)代理,以优化现实世界中的高通量废物分类设施。我们解决了在操作安全性、体积优化和资源使用最小化之间有效平衡的挑战。由于环境的延迟奖励和行动不平衡,简单的代理无法从头开始解决这一复杂问题。我们的五阶段课程学习方法逐步增加环境动态的复杂性,同时精炼奖励机制,使代理能够学习到理想的最优策略。实验结果表明,该方法显著提高了推理时的安全性,实现了近零安全违规,并提升了废物分类厂的效率。
🔬 方法详解
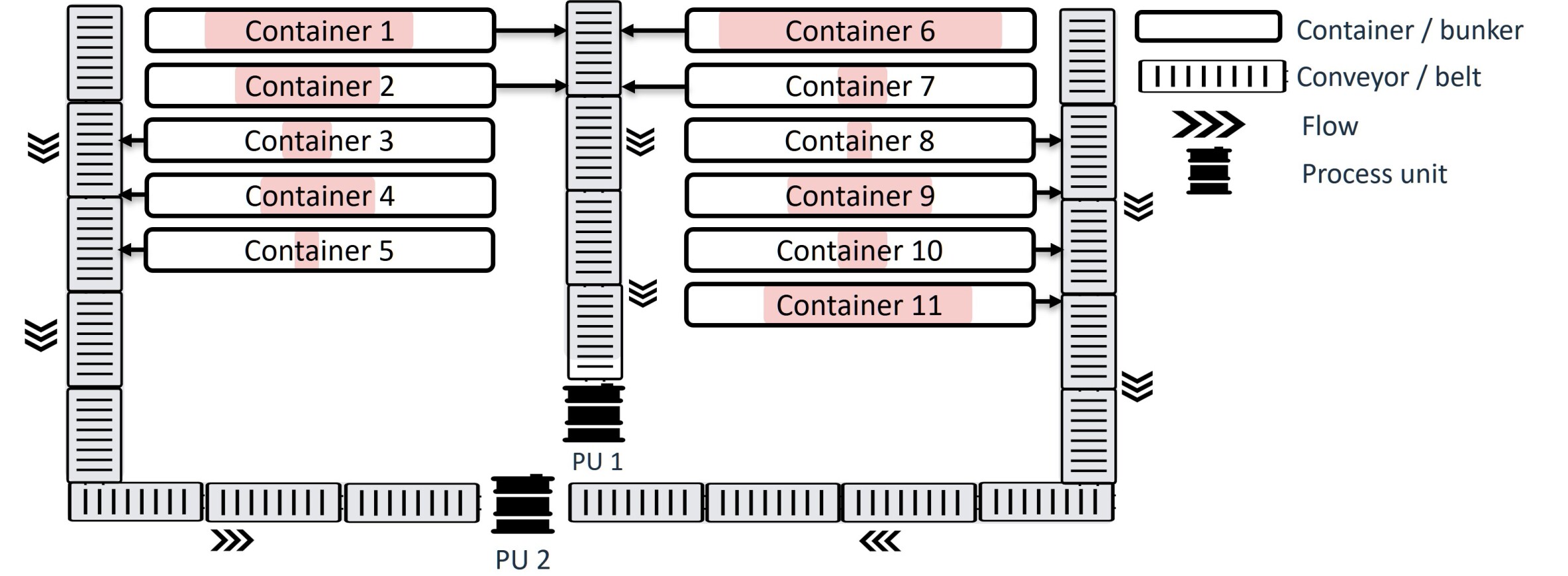
问题定义:本文旨在解决高通量废物分类设施中的多目标优化问题,现有方法因环境复杂性和奖励延迟而难以有效执行。
核心思路:通过课程学习逐步增加环境的复杂性,同时优化奖励机制,使代理能够更好地学习长远的行动后果,优先考虑稀有但有价值的行为。
技术框架:整体方法分为五个阶段,首先从简单的环境开始,逐步引入复杂的动态,同时在每个阶段中调整奖励机制,以促进代理的学习。
关键创新:该研究的创新在于结合课程学习与奖励工程,形成了一种适应性强的训练流程,显著提高了代理在复杂环境中的学习效率。
关键设计:在设计中,采用了精细化的奖励机制,确保代理能够识别并优先执行重要但不频繁的行动,同时设置了适当的超参数以优化学习过程。
🖼️ 关键图片

📊 实验亮点
实验结果表明,采用该方法的代理在推理时实现了近零的安全违规,与基线相比,废物分类效率显著提升,展示了课程学习与奖励工程结合的有效性。
🎯 应用场景
该研究的潜在应用领域包括废物管理、自动化生产线和智能制造等。通过优化废物分类过程,可以显著提高资源利用效率,降低运营成本,具有重要的实际价值和社会影响。未来,该方法还可以扩展到其他复杂的优化问题中,推动智能决策系统的发展。
📄 摘要(原文)
We present a proximal policy optimization (PPO) agent trained through curriculum learning (CL) principles and meticulous reward engineering to optimize a real-world high-throughput waste sorting facility. Our work addresses the challenge of effectively balancing the competing objectives of operational safety, volume optimization, and minimizing resource usage. A vanilla agent trained from scratch on these multiple criteria fails to solve the problem due to its inherent complexities. This problem is particularly difficult due to the environment's extremely delayed rewards with long time horizons and class (or action) imbalance, with important actions being infrequent in the optimal policy. This forces the agent to anticipate long-term action consequences and prioritize rare but rewarding behaviours, creating a non-trivial reinforcement learning task. Our five-stage CL approach tackles these challenges by gradually increasing the complexity of the environmental dynamics during policy transfer while simultaneously refining the reward mechanism. This iterative and adaptable process enables the agent to learn a desired optimal policy. Results demonstrate that our approach significantly improves inference-time safety, achieving near-zero safety violations in addition to enhancing waste sorting plant efficiency.