Propensity Score Alignment of Unpaired Multimodal Data
作者: Johnny Xi, Jana Osea, Zuheng Xu, Jason Hartford
分类: cs.LG, stat.ME, stat.ML
发布日期: 2024-04-02 (更新: 2024-10-29)
备注: NeurIPS 2024
💡 一句话要点
提出倾向评分对齐方法以解决非配对多模态数据对齐问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态表示学习 倾向评分 样本对齐 最优传输 因果推断 生物数据分析 机器学习
📋 核心要点
- 现有的多模态表示学习方法通常依赖于配对样本,而在许多领域,尤其是生物学中,配对样本难以获取。
- 本文提出了一种通过倾向评分对齐非配对样本的方法,利用因果推断中的潜在结果类比来实现样本对齐。
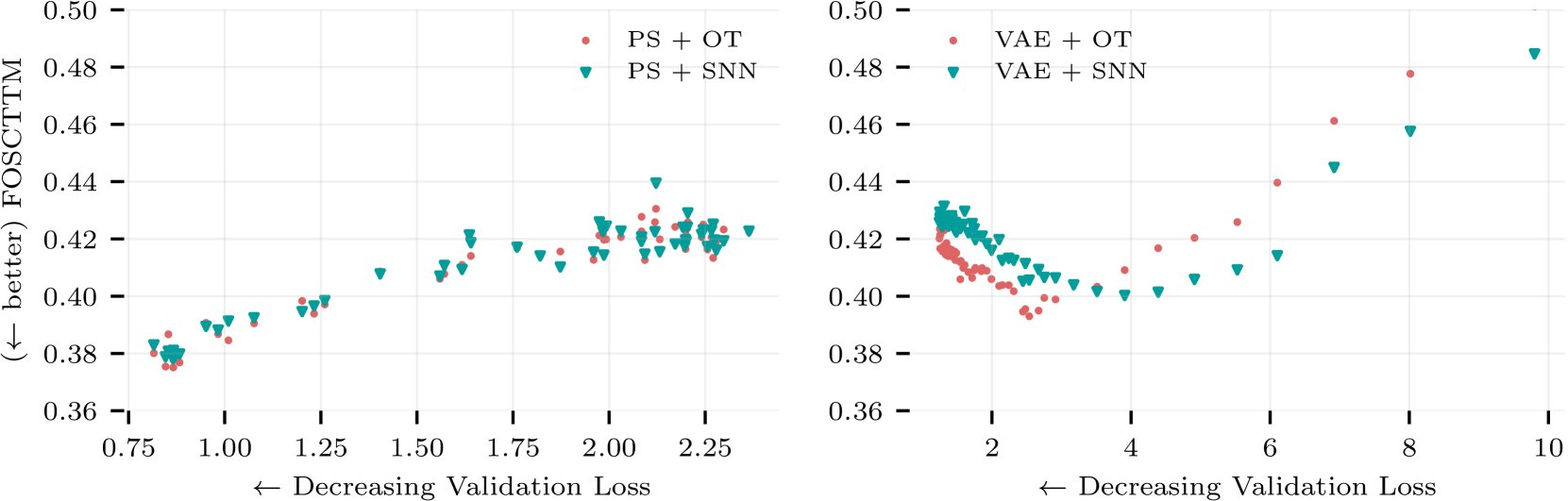
- 实验结果表明,最优传输匹配在合成和真实数据集上均显著优于当前最先进的对齐方法。
📝 摘要(中文)
多模态表示学习技术通常依赖于配对样本来学习共同表示,但在生物学等领域,配对样本的收集非常困难,因为测量设备往往会破坏样本。本文提出了一种方法,旨在解决多模态表示学习中非配对样本的对齐挑战。我们将因果推断中的潜在结果与多模态观察中的潜在视图进行类比,从而利用Rubin框架来估计一个共同空间以匹配样本。该方法假设我们收集的样本受到实验性处理的扰动,并利用此来估计每种模态的倾向评分,倾向评分封装了潜在状态与处理之间的所有共享信息,并可用于定义样本之间的距离。我们实验了两种利用该距离的对齐技术——共享最近邻(SNN)和最优传输(OT)匹配,发现OT匹配在合成多模态设置和NeurIPS多模态单细胞集成挑战中的真实数据上显著优于现有的对齐方法。
🔬 方法详解
问题定义:本文旨在解决多模态表示学习中非配对样本的对齐问题。现有方法通常依赖于配对样本,导致在样本难以获取的领域(如生物学)面临挑战。
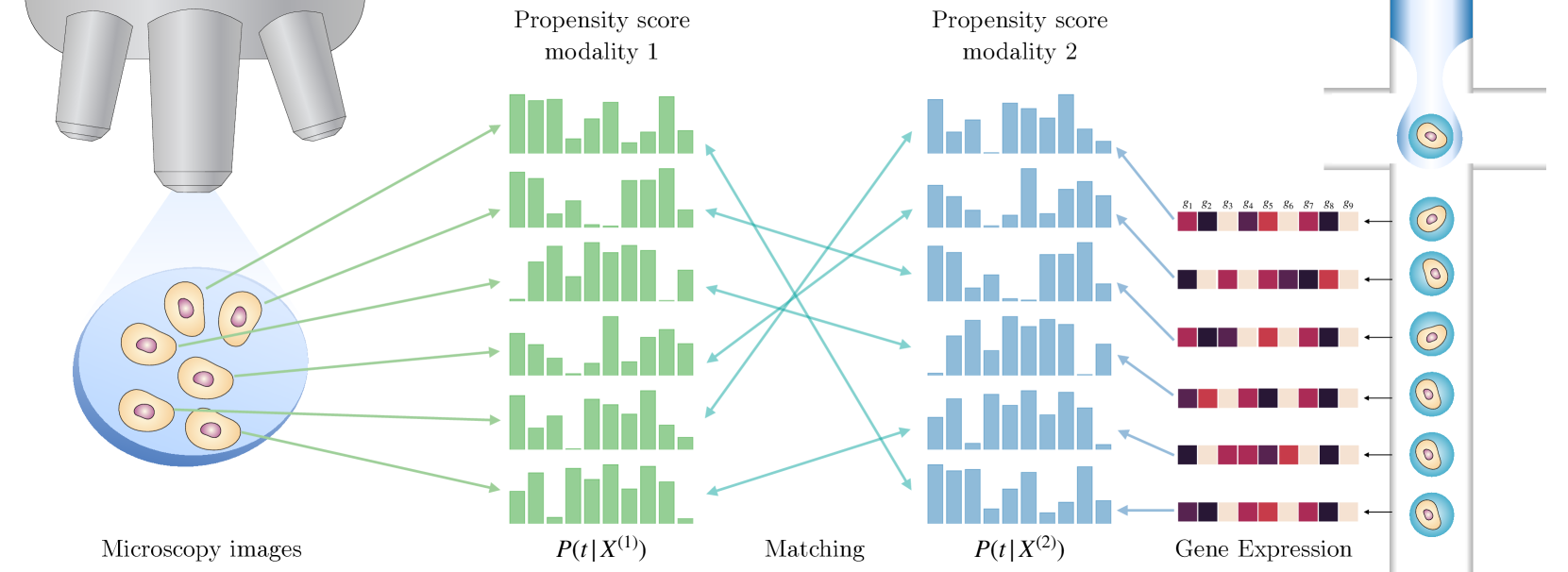
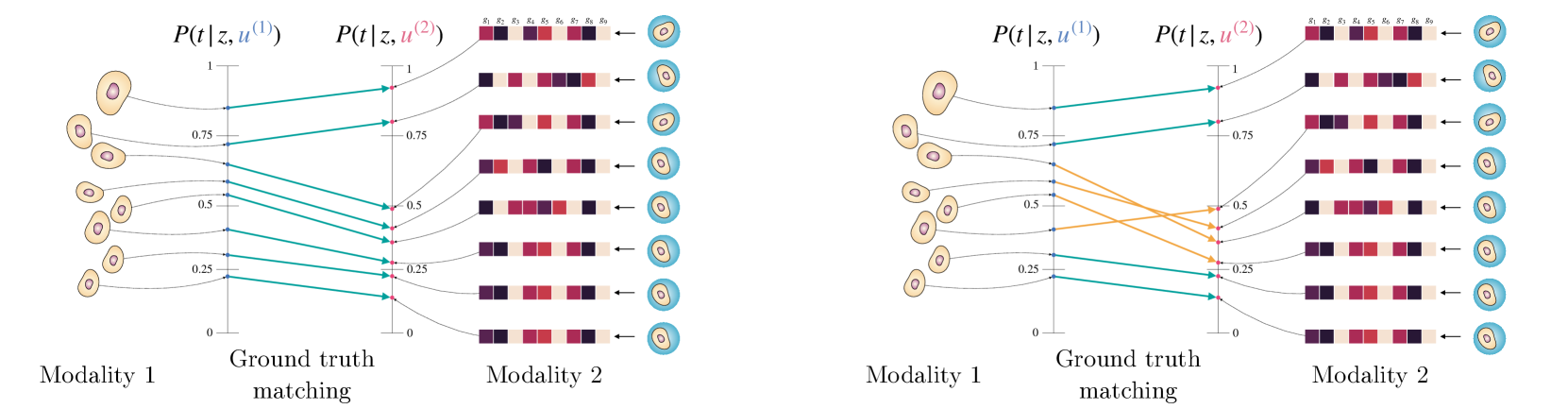
核心思路:通过将因果推断中的潜在结果与多模态观察中的潜在视图进行类比,利用Rubin框架来估计共同空间,从而实现样本对齐。
技术框架:整体流程包括样本收集、倾向评分估计、样本距离定义以及对齐技术的应用。主要模块包括倾向评分计算和对齐算法(SNN和OT匹配)。
关键创新:最重要的创新在于将倾向评分引入多模态对齐中,利用潜在状态与处理之间的共享信息来定义样本间的距离,这一方法与传统的配对样本方法有本质区别。
关键设计:在倾向评分的计算中,考虑了实验性处理的扰动,设计了适合多模态数据的损失函数和网络结构,以确保对齐的准确性和有效性。
🖼️ 关键图片
📊 实验亮点
实验结果显示,最优传输匹配在合成多模态设置中,相较于现有对齐方法,性能提升幅度达到显著水平。在NeurIPS多模态单细胞集成挑战中的真实数据上,OT匹配同样表现出优越的对齐效果,验证了方法的有效性。
🎯 应用场景
该研究的潜在应用领域包括生物医学、社交网络分析和多模态数据集成等。通过有效对齐非配对样本,能够提升数据分析的准确性和可靠性,推动相关领域的研究进展,具有重要的实际价值和未来影响。
📄 摘要(原文)
Multimodal representation learning techniques typically rely on paired samples to learn common representations, but paired samples are challenging to collect in fields such as biology where measurement devices often destroy the samples. This paper presents an approach to address the challenge of aligning unpaired samples across disparate modalities in multimodal representation learning. We draw an analogy between potential outcomes in causal inference and potential views in multimodal observations, which allows us to use Rubin's framework to estimate a common space in which to match samples. Our approach assumes we collect samples that are experimentally perturbed by treatments, and uses this to estimate a propensity score from each modality, which encapsulates all shared information between a latent state and treatment and can be used to define a distance between samples. We experiment with two alignment techniques that leverage this distance -- shared nearest neighbours (SNN) and optimal transport (OT) matching -- and find that OT matching results in significant improvements over state-of-the-art alignment approaches in both a synthetic multi-modal setting and in real-world data from NeurIPS Multimodal Single-Cell Integration Challenge.