OMEGA-Avatar: One-shot Modeling of 360° Gaussian Avatars
作者: Zehao Xia, Yiqun Wang, Zhengda Lu, Kai Liu, Jun Xiao, Peter Wonka
分类: cs.GR, cs.AI, cs.CV
发布日期: 2026-02-12
备注: Project page: https://omega-avatar.github.io/OMEGA-Avatar/
💡 一句话要点
OMEGA-Avatar:提出单图像360°高斯头像建模的快速前馈框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D头像生成 单图像建模 360度建模 高斯头像 可动画模型
📋 核心要点
- 现有单图像3D头像生成方法难以同时兼顾前馈速度、360°完整性和可动画性。
- OMEGA-Avatar通过语义感知网格变形和多视角特征溅射,实现了360°完整头部头像的快速前馈生成。
- 实验表明,OMEGA-Avatar在360°头部完整性上显著优于现有方法,并保持了跨视角的身份一致性。
📝 摘要(中文)
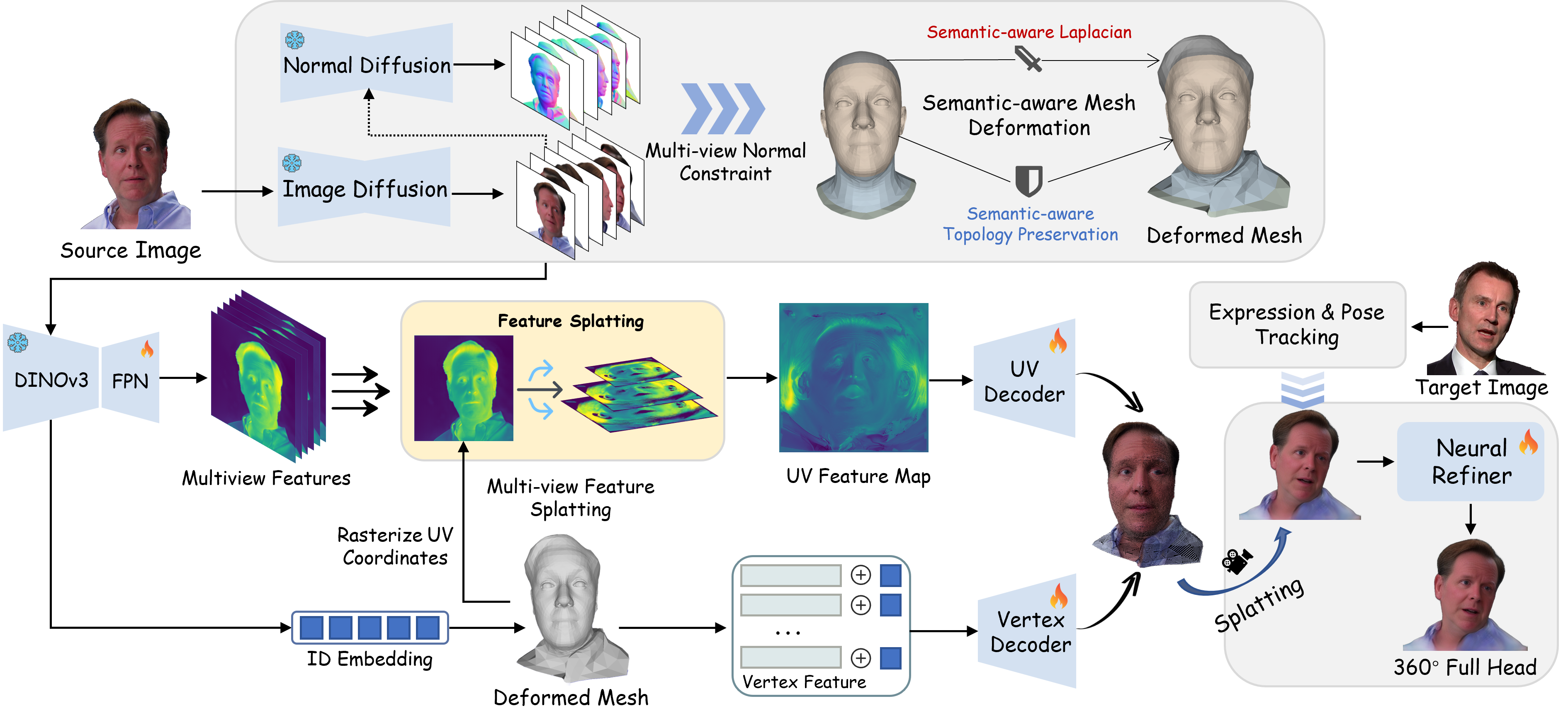
本文提出OMEGA-Avatar,首个从单张图像生成可泛化、360°完整且可动画3D高斯头像的前馈框架。现有方法通常只能同时满足这三个属性中的两个。为解决这一局限,OMEGA-Avatar引入两个创新组件:一是语义感知的网格变形模块,它整合多视角法线来优化带头发的FLAME头部,同时保持其拓扑结构,从而克服了完整头部头像生成中较差的头发建模问题;二是多视角特征溅射模块,通过可微双线性溅射、分层UV映射和可见性感知融合,从多个视角的特征构建共享的规范UV表示,从而实现完整头部特征的有效前馈解码。这种方法在所有视角上保持了全局结构连贯性和局部高频细节,确保了360°一致性,无需逐实例优化。大量实验表明,OMEGA-Avatar实现了最先进的性能,在360°完整头部完整性方面显著优于现有基线,同时在不同视角下稳健地保持了身份。
🔬 方法详解
问题定义:现有单图像3D头像生成方法通常需要在前馈速度、360°完整性和可动画性之间进行权衡。一些方法需要逐实例优化,速度慢;另一些方法无法生成完整的360°头部模型,尤其是在头发建模方面存在困难。因此,如何从单张图像快速生成高质量、可动画的360°完整头部头像是一个挑战。
核心思路:OMEGA-Avatar的核心思路是利用前馈网络直接从单张图像预测3D高斯头像,并通过两个关键模块来解决360°完整头部建模的难题。语义感知网格变形模块负责优化头部和头发的几何形状,而多视角特征溅射模块则负责将不同视角的特征融合到统一的UV空间中,从而保证360°一致性。
技术框架:OMEGA-Avatar的整体框架包括以下几个主要步骤:1) 输入单张图像;2) 使用前馈网络提取图像特征;3) 使用语义感知网格变形模块优化FLAME头部模型,特别是头发区域;4) 使用多视角特征溅射模块将不同视角的特征融合到规范UV空间;5) 使用渲染器生成360°视角的头像图像。
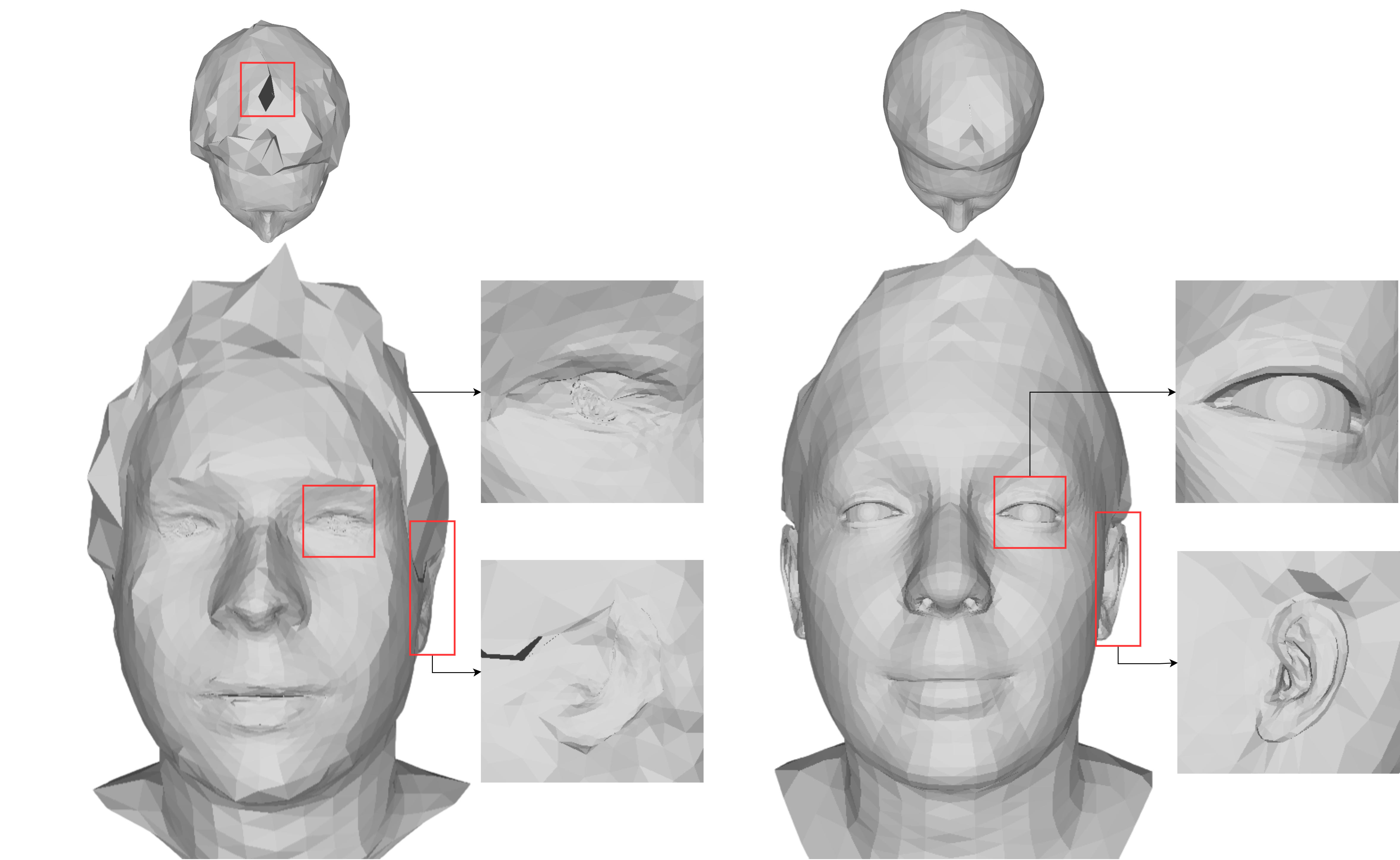
关键创新:OMEGA-Avatar的关键创新在于两个模块:语义感知网格变形模块和多视角特征溅射模块。语义感知网格变形模块通过整合多视角法线信息,能够更准确地建模头发的几何形状。多视角特征溅射模块通过可微的方式将不同视角的特征融合到统一的UV空间,从而保证了360°一致性,避免了逐实例优化。
关键设计:语义感知网格变形模块使用FLAME头部模型作为基础,并引入了语义分割信息来指导头发区域的变形。多视角特征溅射模块使用了可微双线性溅射、分层UV映射和可见性感知融合等技术,以保证特征融合的准确性和效率。损失函数包括几何损失、光度损失和正则化损失,用于约束头部模型的形状、外观和光滑度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OMEGA-Avatar在360°完整头部建模方面显著优于现有方法。在定量评估中,OMEGA-Avatar在头部完整性指标上取得了显著提升,同时在身份保持方面也表现出色。定性结果也表明,OMEGA-Avatar能够生成更逼真、更自然的3D头像,尤其是在头发建模方面。
🎯 应用场景
OMEGA-Avatar在虚拟现实、增强现实、游戏、社交媒体等领域具有广泛的应用前景。它可以用于创建个性化的3D头像,用于虚拟形象、在线会议、虚拟试穿等应用。该技术还可以用于生成逼真的数字替身,用于电影、电视等娱乐产业。未来,该技术有望进一步发展,实现更高质量、更逼真的3D头像生成。
📄 摘要(原文)
Creating high-fidelity, animatable 3D avatars from a single image remains a formidable challenge. We identified three desirable attributes of avatar generation: 1) the method should be feed-forward, 2) model a 360° full-head, and 3) should be animation-ready. However, current work addresses only two of the three points simultaneously. To address these limitations, we propose OMEGA-Avatar, the first feed-forward framework that simultaneously generates a generalizable, 360°-complete, and animatable 3D Gaussian head from a single image. Starting from a feed-forward and animatable framework, we address the 360° full-head avatar generation problem with two novel components. First, to overcome poor hair modeling in full-head avatar generation, we introduce a semantic-aware mesh deformation module that integrates multi-view normals to optimize a FLAME head with hair while preserving its topology structure. Second, to enable effective feed-forward decoding of full-head features, we propose a multi-view feature splatting module that constructs a shared canonical UV representation from features across multiple views through differentiable bilinear splatting, hierarchical UV mapping, and visibility-aware fusion. This approach preserves both global structural coherence and local high-frequency details across all viewpoints, ensuring 360° consistency without per-instance optimization. Extensive experiments demonstrate that OMEGA-Avatar achieves state-of-the-art performance, significantly outperforming existing baselines in 360° full-head completeness while robustly preserving identity across different viewpoints.