T2VTree: User-Centered Visual Analytics for Agent-Assisted Thought-to-Video Authoring
作者: Zhuoyun Zheng, Yu Dong, Gaorong Liang, Guan Li, Guihua Shan, Shiyu Cheng, Dong Tian, Jianlong Zhou, Jie Liang
分类: cs.MM, cs.GR, cs.HC, cs.MA
发布日期: 2026-02-09
🔗 代码/项目: GITHUB
💡 一句话要点
T2VTree:面向用户中心的智能体辅助“想法到视频”创作可视化分析方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到视频生成 可视化分析 智能体辅助 用户中心设计 视频创作
📋 核心要点
- 现有“想法到视频”工具难以有效管理和复用创作过程中的多阶段决策和探索轨迹。
- T2VTree将创作过程表示为树状可视化,结合智能体规划,支持用户编辑和控制生成流程。
- 通过案例研究和用户研究,验证了T2VTree在细化、比较和重用方面的有效性。
📝 摘要(中文)
生成模型显著扩展了视频生成能力,但实际的“想法到视频”创作仍然是一个多阶段、多模态和决策密集的过程。然而,现有工具要么将中间决策隐藏在重复运行的背后,要么暴露操作员级别的工作流程,使得探索轨迹难以管理、比较和重用。我们提出了T2VTree,一种面向用户中心的智能体辅助“想法到视频”创作的可视化分析方法。T2VTree将创作过程表示为树状可视化。树中的每个节点将可编辑的规范(意图、参考输入、工作流程选择、提示和参数)与生成的多模态输出绑定,使得细化、分支和溯源检查可以直接操作。为了减轻决定下一步做什么的负担,一组协作智能体将步骤级别的意图转换为可执行的计划,该计划在执行前保持可见且用户可编辑。我们进一步实现了一个可视化分析系统,该系统集成了分支创作与就地预览和拼接以进行收敛组装,从而无需离开创作环境即可实现端到端的多场景创建。我们通过两个多场景案例研究和一个比较用户研究展示了T2VTreeVA,表明T2VTree可视化和可编辑的智能体规划支持真实创作工作流程中的可靠细化、局部比较和实际重用。T2VTree可在https://github.com/tezuka0210/T2VTree获取。
🔬 方法详解
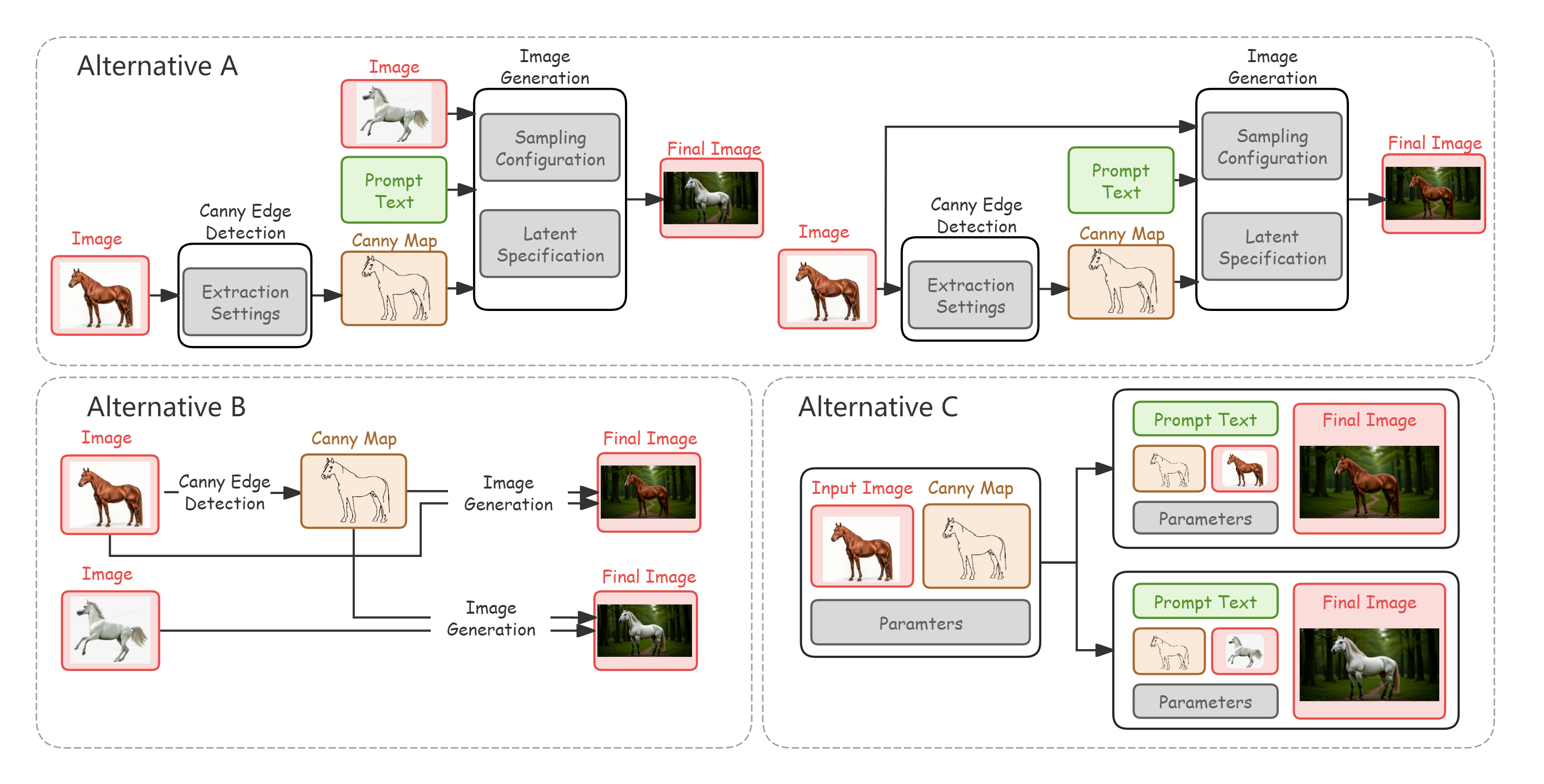
问题定义:论文旨在解决“想法到视频”创作过程中,现有工具在管理复杂创作流程、暴露中间决策、以及支持用户探索和复用创作轨迹方面的不足。现有方法要么隐藏中间决策,导致用户难以理解和控制生成过程,要么暴露过于底层的操作,使得创作流程难以管理和复用。
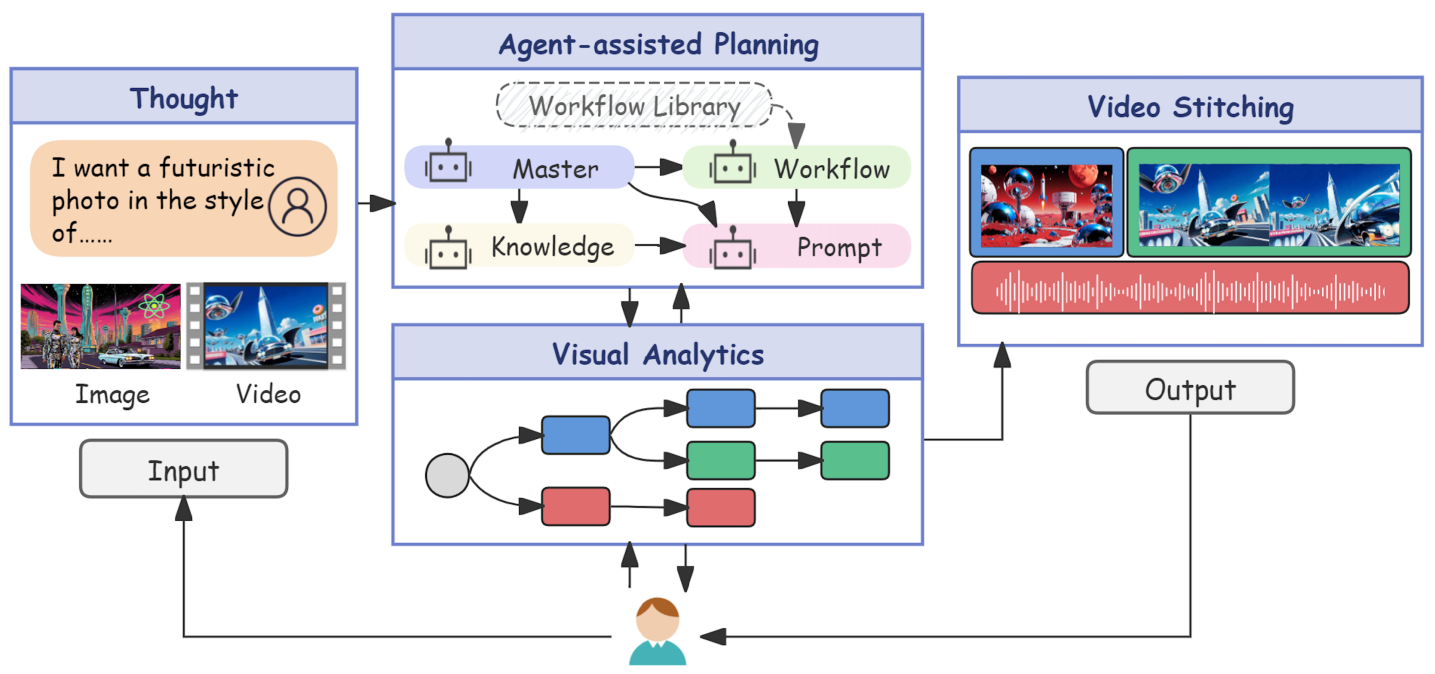
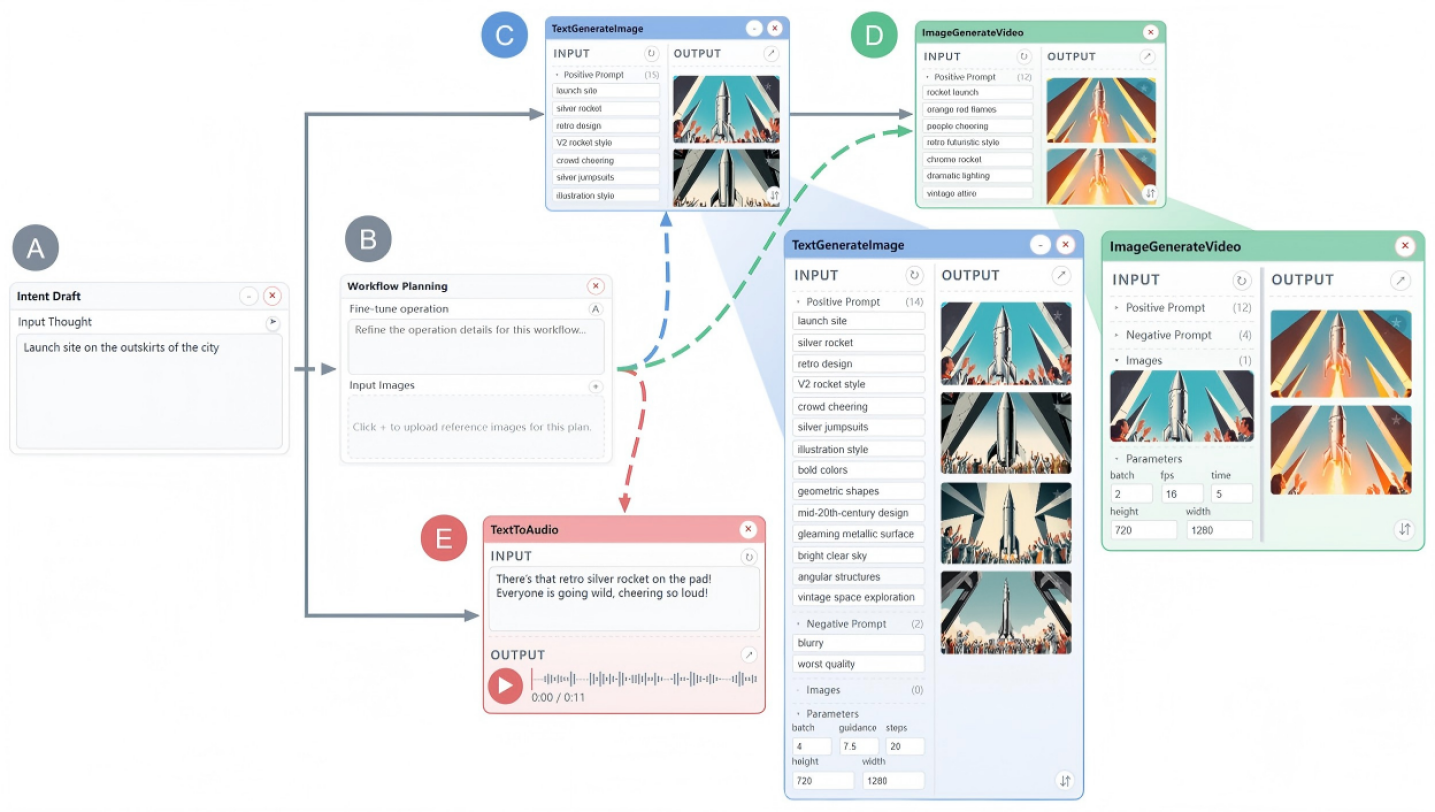
核心思路:论文的核心思路是将“想法到视频”的创作过程建模成一个树状结构,每个节点代表一个创作步骤,包含用户的意图、输入、工作流选择、提示和参数,以及生成的多模态输出。通过这种方式,用户可以清晰地看到创作流程中的每个决策点,并进行细化、分支和溯源。同时,引入智能体辅助规划,将用户的意图转化为可执行的计划,减轻用户的决策负担。
技术框架:T2VTree包含以下主要模块:1) 树状可视化模块,用于展示创作流程;2) 可编辑规范模块,允许用户修改每个节点的意图、输入等参数;3) 智能体规划模块,将用户意图转化为可执行计划;4) 多模态输出模块,展示每个节点的生成结果;5) 就地预览和拼接模块,支持多场景的组装。整体流程是:用户输入意图,智能体生成初步计划,用户编辑计划,系统执行计划生成多模态输出,用户在树状结构中进行细化、分支和溯源,最终完成视频创作。
关键创新:论文的关键创新在于将创作过程表示为树状可视化,并结合智能体辅助规划。这种方法使得用户可以清晰地理解和控制生成过程,并方便地进行细化、分支和溯源。与现有方法相比,T2VTree更加用户友好,能够更好地支持用户的探索和创作。
关键设计:智能体规划模块的设计是关键。具体实现细节未知,但可以推测其需要根据用户意图,选择合适的工作流、提示和参数,并生成可执行的计划。此外,树状可视化的设计也需要考虑如何清晰地展示创作流程,并支持用户的交互操作。具体参数设置、损失函数、网络结构等技术细节未知。
🖼️ 关键图片
📊 实验亮点
论文通过两个多场景案例研究和一个比较用户研究展示了T2VTree的有效性。案例研究表明,T2VTree能够支持复杂的视频创作流程,并帮助用户快速迭代和优化作品。用户研究表明,与现有工具相比,T2VTree能够显著提高用户的创作效率和满意度。具体的性能数据未知。
🎯 应用场景
T2VTree可应用于视频内容创作、教育、娱乐等领域。它可以帮助用户更高效、更便捷地将想法转化为视频作品,降低视频创作的门槛。未来,T2VTree有望成为一种重要的视频创作工具,推动视频内容的普及和创新。
📄 摘要(原文)
Generative models have substantially expanded video generation capabilities, yet practical thought-to-video creation remains a multi-stage, multi-modal, and decision-intensive process. However, existing tools either hide intermediate decisions behind repeated reruns or expose operator-level workflows that make exploration traces difficult to manage, compare, and reuse. We present T2VTree, a user-centered visual analytics approach for agent-assisted thought-to-video authoring. T2VTree represents the authoring process as a tree visualization. Each node in the tree binds an editable specification (intent, referenced inputs, workflow choice, prompts, and parameters) with the resulting multimodal outputs, making refinement, branching, and provenance inspection directly operable. To reduce the burden of deciding what to do next, a set of collaborating agents translates step-level intent into an executable plan that remains visible and user-editable before execution. We further implement a visual analytics system that integrates branching authoring with in-place preview and stitching for convergent assembly, enabling end-to-end multi-scene creation without leaving the authoring context. We demonstrate T2VTreeVA through two multi-scene case studies and a comparative user study, showing how the T2VTree visualization and editable agent planning support reliable refinement, localized comparison, and practical reuse in real authoring workflows. T2VTree is available at: https://github.com/tezuka0210/T2VTree.