Event-T2M: Event-level Conditioning for Complex Text-to-Motion Synthesis
作者: Seong-Eun Hong, JaeYoung Seon, JuYeong Hwang, JongHwan Shin, HyeongYeop Kang
分类: cs.GR
发布日期: 2026-02-04
备注: 28 pages, 7 figures. Accepted to ICLR 2026
💡 一句话要点
Event-T2M:通过事件级条件控制实现复杂文本到动作的合成。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 文本到动作生成 事件级条件控制 扩散模型 多事件动作 动作合成
📋 核心要点
- 现有文本到动作生成模型难以处理复杂的多动作提示,容易丢失动作细节或产生不自然的过渡。
- Event-T2M将文本提示分解为语义自包含的事件,并利用事件级交叉注意力机制整合这些事件。
- 实验表明,Event-T2M在多事件动作生成方面优于现有方法,尤其是在新构建的HumanML3D-E基准上。
📝 摘要(中文)
本文提出了一种新的文本到动作生成框架Event-T2M,旨在解决现有方法在处理复杂多动作提示时,容易将多个动作合并为单个嵌入,导致动作遗漏、重排序或不自然过渡的问题。Event-T2M将文本提示分解为事件,每个事件被定义为文本提示中最小的语义自包含动作或状态变化,并与动作片段进行时间对齐。该框架利用运动感知的检索模型对每个事件进行编码,并通过Conformer块中的基于事件的交叉注意力机制将它们整合。为了更准确地评估模型在多事件场景下的性能,本文构建了HumanML3D-E基准,该基准按照事件数量进行分层。在HumanML3D、KIT-ML和HumanML3D-E上的实验结果表明,Event-T2M在标准测试中与最先进的基线模型相匹配,并且随着事件复杂性的增加,其性能优于其他模型。人工评估验证了事件定义的合理性、HumanML3D-E的可靠性以及Event-T2M在生成多事件动作方面的优越性,能够保持动作顺序和自然性,更接近真实情况。这些结果表明,事件级条件控制是推动文本到动作生成超越单动作提示的一种通用原则。
🔬 方法详解
问题定义:现有文本到动作生成模型在处理包含多个动作的复杂文本提示时,通常将整个提示压缩成一个单一的嵌入向量。这种做法忽略了各个动作之间的独立性和顺序关系,导致生成的动作序列可能出现动作遗漏、动作顺序颠倒或者动作之间的过渡不自然等问题。因此,需要一种能够更好地理解和建模复杂文本提示中各个动作之间关系的方法。
核心思路:Event-T2M的核心思路是将复杂的文本提示分解为一系列独立的“事件”,每个事件代表一个语义上自包含的动作或状态变化。通过将文本提示分解为事件,模型可以更好地理解每个动作的含义,并学习它们之间的时序关系。然后,模型利用事件级的条件控制来生成相应的动作序列,从而避免了现有方法中将所有动作压缩成一个单一嵌入向量的问题。
技术框架:Event-T2M的整体框架包括以下几个主要模块:1) 事件分解模块:将输入的文本提示分解为一系列独立的事件。2) 事件编码模块:使用运动感知的检索模型对每个事件进行编码,生成事件的嵌入向量。3) 动作生成模块:使用基于扩散模型的生成器,根据事件的嵌入向量生成相应的动作序列。4) 事件集成模块:使用Conformer块中的基于事件的交叉注意力机制,将各个事件的动作序列集成起来,生成最终的完整动作序列。
关键创新:Event-T2M的关键创新在于提出了“事件级条件控制”的概念,并将文本提示分解为一系列独立的事件。这种方法能够更好地理解和建模复杂文本提示中各个动作之间的关系,从而生成更自然、更准确的动作序列。此外,Event-T2M还构建了一个新的基准数据集HumanML3D-E,该数据集按照事件数量进行分层,可以更准确地评估模型在多事件场景下的性能。
关键设计:在事件分解模块中,可以使用现有的自然语言处理技术,例如依存句法分析或语义角色标注,来识别文本提示中的事件。在事件编码模块中,可以使用预训练的语言模型,例如BERT或GPT,来生成事件的嵌入向量。在动作生成模块中,可以使用基于扩散模型的生成器,例如DDPM或DDIM,来生成动作序列。在事件集成模块中,可以使用Conformer块中的交叉注意力机制,来学习各个事件之间的时序关系。损失函数可以包括重构损失、对抗损失和对比损失等。
🖼️ 关键图片


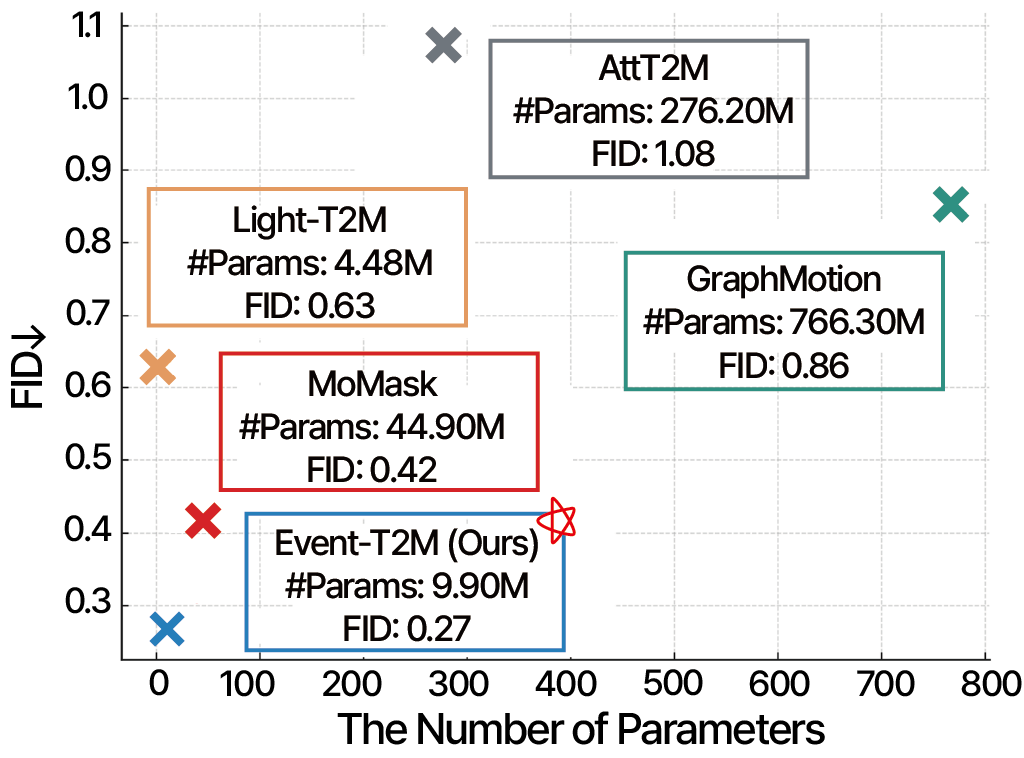
📊 实验亮点
Event-T2M在HumanML3D、KIT-ML和新构建的HumanML3D-E数据集上进行了评估。实验结果表明,Event-T2M在标准测试中与最先进的基线模型相匹配,并且随着事件复杂性的增加,其性能优于其他模型。在HumanML3D-E数据集上,Event-T2M的FID指标显著优于其他模型,表明其能够生成更逼真、更自然的动作序列。人工评估也验证了Event-T2M在生成多事件动作方面的优越性。
🎯 应用场景
Event-T2M技术可应用于虚拟现实、游戏开发、动画制作、机器人控制等领域。例如,在虚拟现实中,用户可以通过文本指令控制虚拟角色的动作;在游戏开发中,可以自动生成游戏角色的动画;在机器人控制中,可以使机器人根据文本指令执行复杂的任务。该技术有望提升人机交互的自然性和效率,并为相关行业带来创新。
📄 摘要(原文)
Text-to-motion generation has advanced with diffusion models, yet existing systems often collapse complex multi-action prompts into a single embedding, leading to omissions, reordering, or unnatural transitions. In this work, we shift perspective by introducing a principled definition of an event as the smallest semantically self-contained action or state change in a text prompt that can be temporally aligned with a motion segment. Building on this definition, we propose Event-T2M, a diffusion-based framework that decomposes prompts into events, encodes each with a motion-aware retrieval model, and integrates them through event-based cross-attention in Conformer blocks. Existing benchmarks mix simple and multi-event prompts, making it unclear whether models that succeed on single actions generalize to multi-action cases. To address this, we construct HumanML3D-E, the first benchmark stratified by event count. Experiments on HumanML3D, KIT-ML, and HumanML3D-E show that Event-T2M matches state-of-the-art baselines on standard tests while outperforming them as event complexity increases. Human studies validate the plausibility of our event definition, the reliability of HumanML3D-E, and the superiority of Event-T2M in generating multi-event motions that preserve order and naturalness close to ground-truth. These results establish event-level conditioning as a generalizable principle for advancing text-to-motion generation beyond single-action prompts.