Mesh Splatting for End-to-end Multiview Surface Reconstruction
作者: Ruiqi Zhang, Jiacheng Wu, Jie Chen
分类: cs.GR
发布日期: 2026-01-29
💡 一句话要点
提出Mesh Splatting,通过可微体渲染实现端到端多视角表面重建,提升网格质量。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 表面重建 体渲染 网格表示 可微渲染 多视角几何
📋 核心要点
- 传统表面重建方法依赖网格划分或直接优化表面参数,前者易产生过度密集网格,后者难以捕捉复杂几何细节。
- 论文提出Mesh Splatting,将表面表示可微地转化为体素表示,通过体渲染实现端到端表面重建,从而建模复杂几何。
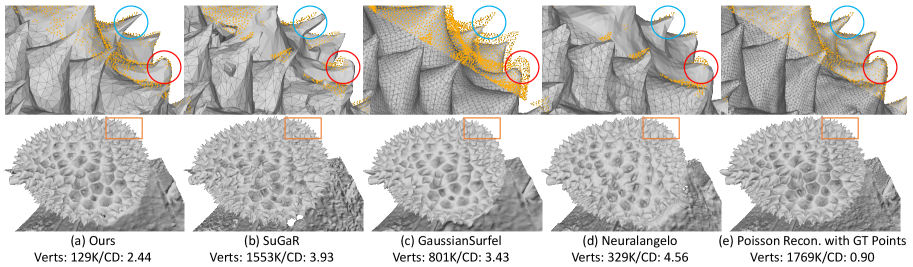
- 实验表明,该方法能在20分钟内完成优化,实现精确表面重建,并显著提升网格质量。
📝 摘要(中文)
表面通常表示为网格,可以通过网格划分从体素场中提取,或者直接优化为表面参数化。体素表示占据3D空间,并且沿射线的有效感受野很大,从而可以通过体渲染实现稳定而有效的优化;然而,随后的网格划分通常会产生过度密集的网格并引入累积误差。相比之下,纯表面方法避免了网格划分,但仅使用单层感受野捕获边界几何形状,这使得学习复杂的几何细节变得困难,并增加了对先验(例如,阴影或法线)的依赖。我们通过可微地将表面表示转换为体素表示来弥合这一差距,从而可以通过体渲染进行端到端表面重建,以建模复杂的几何形状。具体来说,我们将网格软化为多个半透明层,这些层相对于基础网格保持可微,从而使其具有可控的3D感受野。结合基于splatting的渲染器和拓扑控制策略,我们的方法可以在大约20分钟内进行优化,以实现准确的表面重建,同时显着提高网格质量。
🔬 方法详解
问题定义:现有的表面重建方法,如基于体素场的方法,虽然具有较大的感受野,但后续的网格划分会引入误差并产生过密的网格。而纯表面方法虽然避免了网格划分,但感受野有限,难以捕捉复杂的几何细节,依赖于先验知识。因此,如何兼顾大的感受野和精确的表面重建是一个挑战。
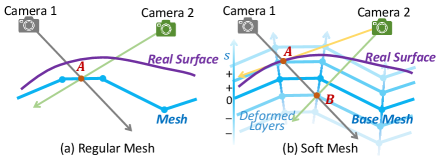
核心思路:论文的核心思路是将表面表示转化为体素表示,并使其可微,从而能够利用体渲染的优势进行端到端优化。具体来说,是将网格“软化”为多个半透明层,赋予其可控的3D感受野。这样既能保持表面表示的精确性,又能利用体渲染的稳定性。
技术框架:该方法主要包含以下几个步骤:1) 初始化一个网格表面;2) 将该网格表面通过Mesh Splatting转化为多个半透明层,形成一个体素表示;3) 使用基于splatting的渲染器对该体素表示进行渲染,生成图像;4) 计算渲染图像与真实图像之间的损失,并反向传播梯度,优化网格表面。同时,采用拓扑控制策略来改善网格质量。
关键创新:该方法最重要的创新点在于提出了Mesh Splatting,即将网格表面转化为可微的体素表示。这种表示方式既保留了表面表示的精确性,又赋予了其体素表示的感受野。此外,结合splatting-based渲染器和拓扑控制策略,实现了端到端的表面重建。
关键设计:Mesh Splatting的具体实现是将网格的每个三角形面片“splat”到多个半透明层上,每个层的透明度由一个高斯函数控制,高斯函数的方差控制了感受野的大小。损失函数包括图像重建损失和正则化项,用于约束网格的形状和拓扑结构。拓扑控制策略通过边坍缩和边翻转等操作来简化网格,提高网格质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够在20分钟内完成优化,实现精确的表面重建,并显著提高网格质量。与传统方法相比,该方法在重建精度和网格质量上均有显著提升,尤其是在处理复杂几何形状时表现更佳。
🎯 应用场景
该研究成果可应用于三维重建、虚拟现实、增强现实、机器人导航等领域。通过高质量的表面重建,可以提升虚拟场景的真实感,提高机器人对环境的感知能力,并为三维建模提供更精确的数据。
📄 摘要(原文)
Surfaces are typically represented as meshes, which can be extracted from volumetric fields via meshing or optimized directly as surface parameterizations. Volumetric representations occupy 3D space and have a large effective receptive field along rays, enabling stable and efficient optimization via volumetric rendering; however, subsequent meshing often produces overly dense meshes and introduces accumulated errors. In contrast, pure surface methods avoid meshing but capture only boundary geometry with a single-layer receptive field, making it difficult to learn intricate geometric details and increasing reliance on priors (e.g., shading or normals). We bridge this gap by differentiably turning a surface representation into a volumetric one, enabling end-to-end surface reconstruction via volumetric rendering to model complex geometries. Specifically, we soften a mesh into multiple semi-transparent layers that remain differentiable with respect to the base mesh, endowing it with a controllable 3D receptive field. Combined with a splatting-based renderer and a topology-control strategy, our method can be optimized in about 20 minutes to achieve accurate surface reconstruction while substantially improving mesh quality.