Copy-Trasform-Paste: Zero-Shot Object-Object Alignment Guided by Vision-Language and Geometric Constraints
作者: Rotem Gatenyo, Ohad Fried
分类: cs.GR, cs.CV
发布日期: 2026-01-20
💡 一句话要点
提出Copy-Transform-Paste方法,实现零样本三维物体对齐,用于内容创作和场景组装。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 三维物体对齐 视觉语言模型 可微渲染 几何约束
📋 核心要点
- 现有方法在三维物体对齐方面存在不足,或依赖几何对齐,或需训练新模型,泛化性受限。
- 提出Copy-Transform-Paste框架,通过CLIP驱动的梯度优化物体姿态,结合语言和几何约束。
- 实验表明,该方法在自建基准测试中优于现有方法,实现了语义和物理上合理的对齐效果。
📝 摘要(中文)
本文研究了两个给定三维网格的零样本对齐问题,利用文本提示描述它们之间的空间关系,这对于内容创作和场景组装至关重要。早期方法主要依赖于几何对齐程序,而最近的工作利用预训练的二维扩散模型来建模语言条件下的物体-物体空间关系。与这些方法不同,我们直接在测试时优化相对姿态,通过可微渲染器,利用CLIP驱动的梯度更新平移、旋转和各向同性缩放,无需训练新模型。我们的框架通过几何感知目标增强了语言监督:一种软迭代最近点(ICP)项的变体,以鼓励表面附着,以及一种穿透损失,以阻止相互穿透。分阶段的时间表加强了接触约束,相机控制将优化集中在交互区域。为了进行评估,我们整理了一个包含不同类别和关系的基准,并与基线进行比较。我们的方法优于所有替代方案,产生了语义上忠实且物理上合理的对齐。
🔬 方法详解
问题定义:论文旨在解决零样本条件下的三维物体对齐问题,即给定两个三维网格和一个描述它们空间关系的文本提示,如何自动调整两个物体的相对姿态,使其满足文本描述的空间关系。现有方法要么依赖于几何特征,对复杂场景适应性差,要么需要训练新的模型,泛化能力不足。
核心思路:论文的核心思路是直接在测试时优化物体的相对姿态,利用预训练的CLIP模型提取文本和图像的特征,通过可微渲染器计算梯度,并结合几何约束(如表面接触和避免穿透)来指导优化过程。这种方法无需训练新模型,能够更好地泛化到新的物体和关系。
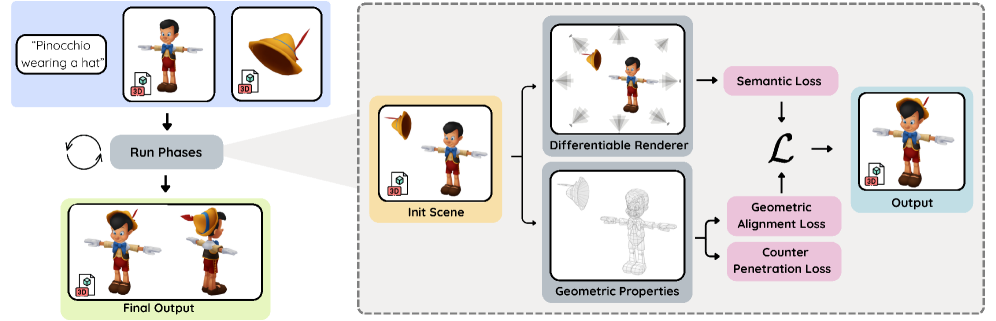
技术框架:整体框架包含以下几个主要模块:1) CLIP特征提取:利用CLIP模型提取文本提示和渲染图像的特征。2) 可微渲染:使用可微渲染器将三维物体渲染成二维图像,以便计算梯度。3) 姿态优化:通过梯度下降算法优化物体的平移、旋转和缩放参数。4) 几何约束:引入软ICP损失和穿透损失,鼓励物体表面接触并避免相互穿透。5) 分阶段优化:采用分阶段的时间表,逐步加强接触约束。6) 相机控制:调整相机视角,将优化集中在交互区域。
关键创新:最重要的创新点在于将语言监督和几何约束相结合,直接在测试时优化物体姿态,无需训练新模型。通过CLIP模型建立文本和图像之间的联系,利用可微渲染器计算梯度,并引入几何约束来保证对齐结果的物理合理性。
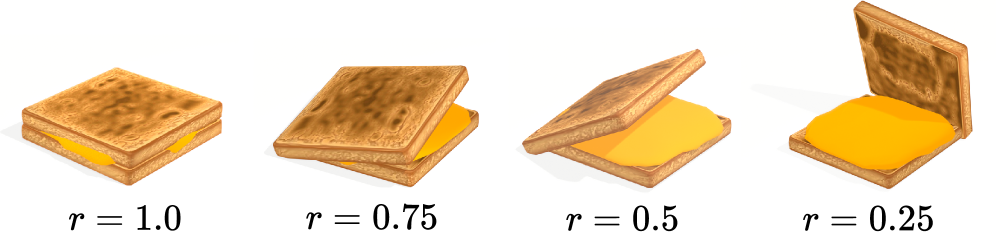
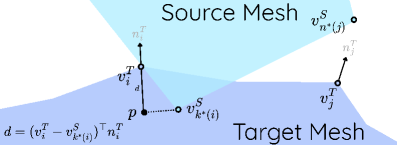
关键设计:关键设计包括:1) CLIP损失函数:使用CLIP模型提取的特征计算相似度损失,指导姿态优化。2) 软ICP损失:使用软迭代最近点算法鼓励物体表面接触。3) 穿透损失:惩罚物体之间的穿透,保证物理合理性。4) 分阶段优化策略:逐步增加软ICP损失的权重,先关注语义对齐,再关注几何细节。5) 相机控制策略:动态调整相机视角,将优化集中在交互区域。
🖼️ 关键图片
📊 实验亮点
该方法在自建的基准测试中取得了显著的性能提升,超越了所有对比的基线方法。实验结果表明,该方法能够生成语义上忠实且物理上合理的对齐结果。通过消融实验验证了各个模块的有效性,例如几何约束和分阶段优化策略。
🎯 应用场景
该研究成果可应用于三维内容创作、虚拟场景组装、机器人操作等领域。例如,用户可以通过简单的文本描述,自动将不同的三维模型组合成一个完整的场景。在机器人领域,该技术可以帮助机器人理解人类指令,并完成复杂的装配任务。未来,该技术有望进一步扩展到更复杂的场景和任务中。
📄 摘要(原文)
We study zero-shot 3D alignment of two given meshes, using a text prompt describing their spatial relation -- an essential capability for content creation and scene assembly. Earlier approaches primarily rely on geometric alignment procedures, while recent work leverages pretrained 2D diffusion models to model language-conditioned object-object spatial relationships. In contrast, we directly optimize the relative pose at test time, updating translation, rotation, and isotropic scale with CLIP-driven gradients via a differentiable renderer, without training a new model. Our framework augments language supervision with geometry-aware objectives: a variant of soft-Iterative Closest Point (ICP) term to encourage surface attachment and a penetration loss to discourage interpenetration. A phased schedule strengthens contact constraints over time, and camera control concentrates the optimization on the interaction region. To enable evaluation, we curate a benchmark containing diverse categories and relations, and compare against baselines. Our method outperforms all alternatives, yielding semantically faithful and physically plausible alignments.