R3-RECON: Radiance-Field-Free Active Reconstruction via Renderability
作者: Xiaofeng Jin, Matteo Frosi, Yiran Guo, Matteo Matteucci
分类: cs.GR
发布日期: 2026-01-12
备注: 18 pages, 11 figures
💡 一句话要点
提出R3-RECON以解决主动重建中的视角选择问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 主动重建 可渲染性 视角选择 3D重建 体素图 深度学习
📋 核心要点
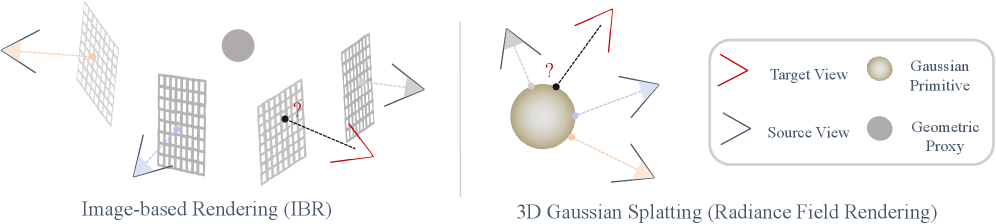
- 现有的主动重建方法在视角选择上依赖于复杂的辐射场,导致计算开销大且不适合轻量级应用。
- 本文提出R3-RECON框架,通过轻量级体素图生成可渲染性场,简化了视角选择过程。
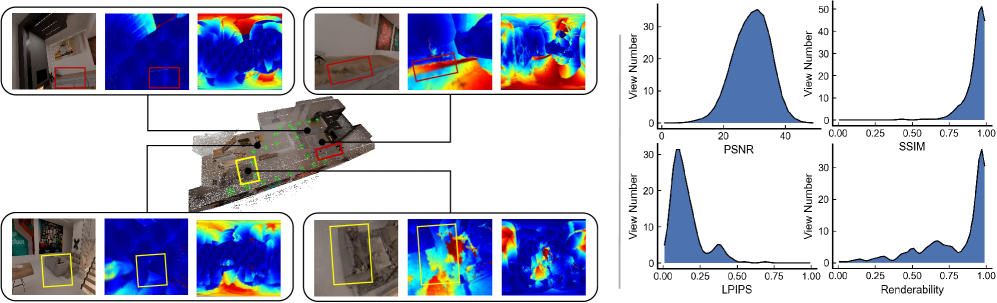
- 在Replica数据集上,R3-RECON在新视图质量和3D重建精度上均优于现有基线方法。
📝 摘要(中文)
在主动重建中,具身代理需要决定下一个观察视角,以高效获取支持高质量新视图渲染的视角。现有的主动视角规划方法通常依赖于通过辐射场反向传播或估计3D高斯原语的信息熵来确定下一个最佳视角(NBV),但这些方法与重表示特定机制紧密耦合,未能考虑轻量级在线部署所需的计算和资源限制。本文从可渲染性中心的视角重新审视主动重建,提出了R3-RECON框架,该框架通过轻量级体素图诱导出一个隐式的、姿态条件的可渲染性场。该方法在标准室内Replica数据集上实现了更均匀的新视图质量和更高的3D高斯点云重建精度。
🔬 方法详解
问题定义:本文旨在解决主动重建中视角选择的高计算开销问题。现有方法依赖于辐射场,导致不适合实时应用。
核心思路:R3-RECON框架通过轻量级体素图生成可渲染性场,避免了对辐射场的依赖,从而降低了计算复杂度。
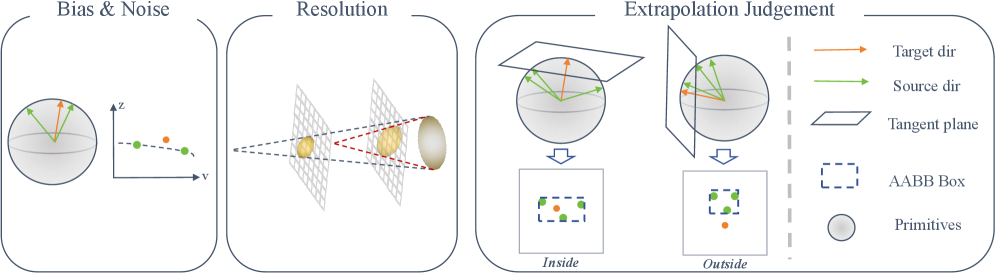
技术框架:该框架包括体素图的构建、可渲染性场的生成和NBV选择三个主要模块。体素图提供了环境的稀疏表示,而可渲染性场则用于快速评估视角的可渲染性。
关键创新:R3-RECON的主要创新在于引入了一个隐式的、姿态条件的可渲染性场,该场能够在毫秒级别内进行查询,显著提高了视角选择的效率。
关键设计:该方法通过聚合每个体素的在线观察统计信息生成统一的可渲染性评分,避免了梯度计算和辐射场训练的需求。
🖼️ 关键图片
📊 实验亮点
在标准室内Replica数据集上,R3-RECON实现了更均匀的新视图质量,相较于现有的主动3D高斯点云重建基线方法,其重建精度显著提高,且在相同的视角和时间预算下表现更佳。
🎯 应用场景
R3-RECON框架具有广泛的应用潜力,特别是在机器人导航、增强现实和虚拟现实等领域。其高效的视角选择机制能够支持实时环境重建,提升用户体验和系统性能。
📄 摘要(原文)
In active reconstruction, an embodied agent must decide where to look next to efficiently acquire views that support high-quality novel-view rendering. Recent work on active view planning for neural rendering largely derives next-best-view (NBV) criteria by backpropagating through radiance fields or estimating information entropy over 3D Gaussian primitives. While effective, these strategies tightly couple view selection to heavy, representation-specific mechanisms and fail to account for the computational and resource constraints required for lightweight online deployment. In this paper, we revisit active reconstruction from a renderability-centric perspective. We propose $\mathbb{R}^{3}$-RECON, a radiance-fields-free active reconstruction framework that induces an implicit, pose-conditioned renderability field over SE(3) from a lightweight voxel map. Our formulation aggregates per-voxel online observation statistics into a unified scalar renderability score that is cheap to update and can be queried in closed form at arbitrary candidate viewpoints in milliseconds, without requiring gradients or radiance-field training. This renderability field is strongly correlated with image-space reconstruction error, naturally guiding NBV selection. We further introduce a panoramic extension that estimates omnidirectional (360$^\circ$) view utility to accelerate candidate evaluation. In the standard indoor Replica dataset, $\mathbb{R}^{3}$-RECON achieves more uniform novel-view quality and higher 3D Gaussian splatting (3DGS) reconstruction accuracy than recent active GS baselines with matched view and time budgets.