SMP: Reusable Score-Matching Motion Priors for Physics-Based Character Control
作者: Yuxuan Mu, Ziyu Zhang, Yi Shi, Minami Matsumoto, Kotaro Imamura, Guy Tevet, Chuan Guo, Michael Taylor, Chang Shu, Pengcheng Xi, Xue Bin Peng
分类: cs.GR, cs.AI, cs.CV, cs.RO
发布日期: 2025-12-02 (更新: 2025-12-03)
备注: 14 pages, 9 figures
💡 一句话要点
提出SMP:可复用的基于分数匹配的运动先验,用于物理角色控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱八:物理动画 (Physics-based Animation)
关键词: 运动先验 物理角色控制 扩散模型 分数匹配 模仿学习 可复用性 运动合成
📋 核心要点
- 对抗模仿学习在学习运动先验方面表现出色,但通常需要为每个新控制器重新训练,限制了其可重用性,并需要保留参考运动数据。
- SMP利用预训练的运动扩散模型和分数蒸馏采样,创建可重用的、任务无关的运动先验,无需为每个新任务重新训练。
- 实验表明,SMP能够生成高质量的运动,与最先进的对抗模仿学习方法相当,并且可以组合和生成新的运动风格。
📝 摘要(中文)
本文提出了一种名为分数匹配运动先验(SMP)的方法,利用预训练的运动扩散模型和分数蒸馏采样(SDS)来创建可复用的、任务无关的运动先验。SMP可以在运动数据集上进行预训练,无需依赖任何控制策略或任务。训练完成后,SMP可以被冻结并作为通用奖励函数,用于训练策略以生成下游任务的自然行为。研究表明,在大规模数据集上训练的通用运动先验可以被重新用于各种特定风格的先验。此外,SMP可以组合不同的风格,合成原始数据集中不存在的新风格。该方法通过可复用和模块化的运动先验,生成了可与最先进的对抗模仿学习方法相媲美的高质量运动。在各种具有物理模拟人形角色的控制任务中,证明了SMP的有效性。
🔬 方法详解
问题定义:现有对抗模仿学习方法在学习运动先验时,通常需要针对每个新的控制任务或角色进行重新训练,导致训练成本高昂,且无法充分利用已有的运动数据。此外,这些方法通常需要保留原始的参考运动数据,增加了存储和管理的负担。因此,如何设计一种可复用的、任务无关的运动先验,成为一个重要的研究问题。
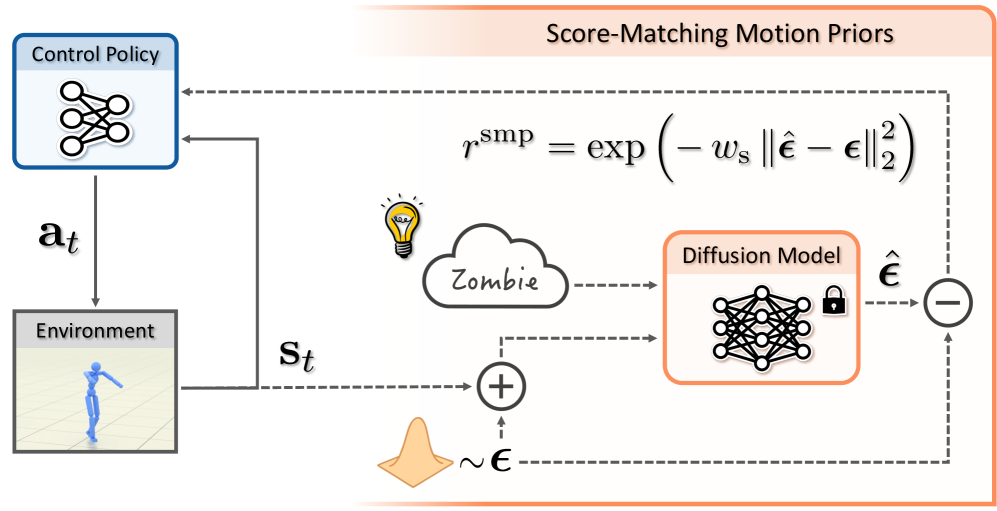
核心思路:SMP的核心思路是利用预训练的运动扩散模型,通过分数蒸馏采样(SDS)将运动扩散模型中的运动知识提炼成一个可复用的运动先验。由于运动扩散模型是在大规模运动数据集上训练的,因此它能够捕捉到各种自然运动的统计规律。通过SDS,可以将这些规律转化为一个奖励函数,用于指导控制策略的学习,从而生成自然逼真的运动。
技术框架:SMP的整体框架包括两个主要阶段:预训练阶段和控制阶段。在预训练阶段,首先在一个大规模的运动数据集上训练一个运动扩散模型。然后,利用训练好的运动扩散模型和SDS,生成一个SMP。在控制阶段,将SMP作为一个奖励函数,用于训练控制策略。控制策略的目标是最大化SMP给出的奖励,从而生成符合运动先验的自然运动。
关键创新:SMP的关键创新在于其可复用性和任务无关性。传统的对抗模仿学习方法需要为每个新任务重新训练运动先验,而SMP只需要预训练一次,就可以在多个不同的控制任务中使用。此外,SMP还可以组合不同的运动风格,生成新的运动风格,从而扩展了运动先验的应用范围。
关键设计:SMP的关键设计包括运动扩散模型的选择、SDS的实现方式以及奖励函数的构建。论文中使用了基于Transformer的运动扩散模型,并采用了一种改进的SDS算法,以提高采样效率和运动质量。奖励函数的设计也至关重要,论文中将SMP的分数函数作为奖励函数,并进行了一些调整,以使其更适合于控制任务。
🖼️ 关键图片

📊 实验亮点
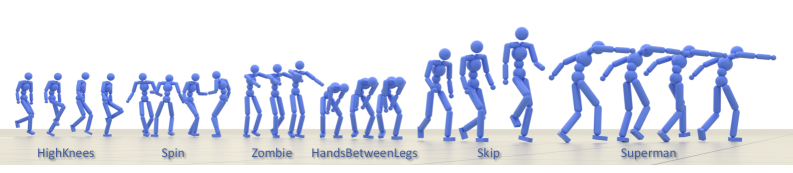
SMP在多个物理模拟人形角色的控制任务中取得了显著成果。实验结果表明,SMP能够生成与最先进的对抗模仿学习方法相媲美的高质量运动,同时具有更好的可复用性和泛化能力。此外,SMP还能够组合不同的运动风格,生成新的运动风格,例如将行走和跑步的风格结合起来,生成一种新的运动风格。
🎯 应用场景
SMP具有广泛的应用前景,可以应用于游戏、电影、虚拟现实等领域,用于生成逼真自然的虚拟角色运动。例如,在游戏中,可以使用SMP来控制游戏角色的运动,使其更加自然流畅。在电影中,可以使用SMP来生成特效角色的运动,提高电影的视觉效果。此外,SMP还可以应用于机器人控制领域,用于生成机器人的自然运动。
📄 摘要(原文)
Data-driven motion priors that can guide agents toward producing naturalistic behaviors play a pivotal role in creating life-like virtual characters. Adversarial imitation learning has been a highly effective method for learning motion priors from reference motion data. However, adversarial priors, with few exceptions, need to be retrained for each new controller, thereby limiting their reusability and necessitating the retention of the reference motion data when training on downstream tasks. In this work, we present Score-Matching Motion Priors (SMP), which leverages pre-trained motion diffusion models and score distillation sampling (SDS) to create reusable task-agnostic motion priors. SMPs can be pre-trained on a motion dataset, independent of any control policy or task. Once trained, SMPs can be kept frozen and reused as general-purpose reward functions to train policies to produce naturalistic behaviors for downstream tasks. We show that a general motion prior trained on large-scale datasets can be repurposed into a variety of style-specific priors. Furthermore SMP can compose different styles to synthesize new styles not present in the original dataset. Our method produces high-quality motion comparable to state-of-the-art adversarial imitation learning methods through reusable and modular motion priors. We demonstrate the effectiveness of SMP across a diverse suite of control tasks with physically simulated humanoid characters. Video demo available at https://youtu.be/ravlZJteS20