Efficient representation of 3D spatial data for defense-related applications
作者: Benjamin Kahl, Marcus Hebel, Michael Arens
分类: cs.GR
发布日期: 2025-11-07
DOI: 10.1117/12.3069693
💡 一句话要点
针对国防应用,提出结合传统几何模型与神经渲染的3D空间数据高效表示方法。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D空间数据表示 神经渲染 3D高斯溅射 几何建模 国防应用
📋 核心要点
- 现有3D数据表示方法在国防应用中面临几何精度与视觉逼真度之间的权衡,传统方法几何精确但视觉效果差,神经渲染方法视觉效果好但几何精度不足。
- 论文提出一种混合方法,结合传统网格模型保证几何完整性,并利用神经渲染技术(如3DGS)增强视觉细节,从而兼顾几何精度和视觉逼真度。
- 论文设计了一种分层场景结构来管理混合表示,旨在提高系统的可扩展性和性能,使其能够处理大规模的国防应用场景。
📝 摘要(中文)
地理空间传感器数据对于现代国防和安全至关重要,它为态势感知提供了不可或缺的3D信息。这些数据来自激光雷达传感器和光学相机等来源,可以创建详细的作战环境模型。本文对传统表示方法(如点云、体素网格和三角网格)以及现代神经和隐式技术(如神经辐射场(NeRFs)和3D高斯溅射(3DGS))进行了比较分析。我们的评估揭示了一个根本性的权衡:传统模型提供强大的几何精度,非常适合视线分析和物理模拟等功能性任务,而现代方法擅长生成高保真、照片般逼真的视觉效果,但通常缺乏几何可靠性。基于这些发现,我们得出结论,混合方法是最有希望的前进方向。我们提出了一种系统架构,该架构结合了用于几何完整性的传统网格支架和用于视觉细节的神经表示(如3DGS),并在分层场景结构中进行管理,以确保可扩展性和性能。
🔬 方法详解
问题定义:国防应用中,3D空间数据的表示方法需要在几何精度和视觉逼真度之间取得平衡。传统方法(如点云、体素网格、三角网格)虽然几何精度高,但视觉效果较差,难以满足现代态势感知的需求。而新兴的神经渲染方法(如NeRF、3DGS)虽然能生成逼真的视觉效果,但几何精度不足,难以支持精确的物理模拟和视线分析等关键任务。
核心思路:论文的核心思路是结合传统几何模型和神经渲染技术的优势,构建一种混合表示方法。具体来说,使用传统网格模型作为几何框架,保证整体的几何精度和拓扑结构;然后,利用神经渲染技术(特别是3DGS)来增强网格模型的视觉细节,提升渲染质量。
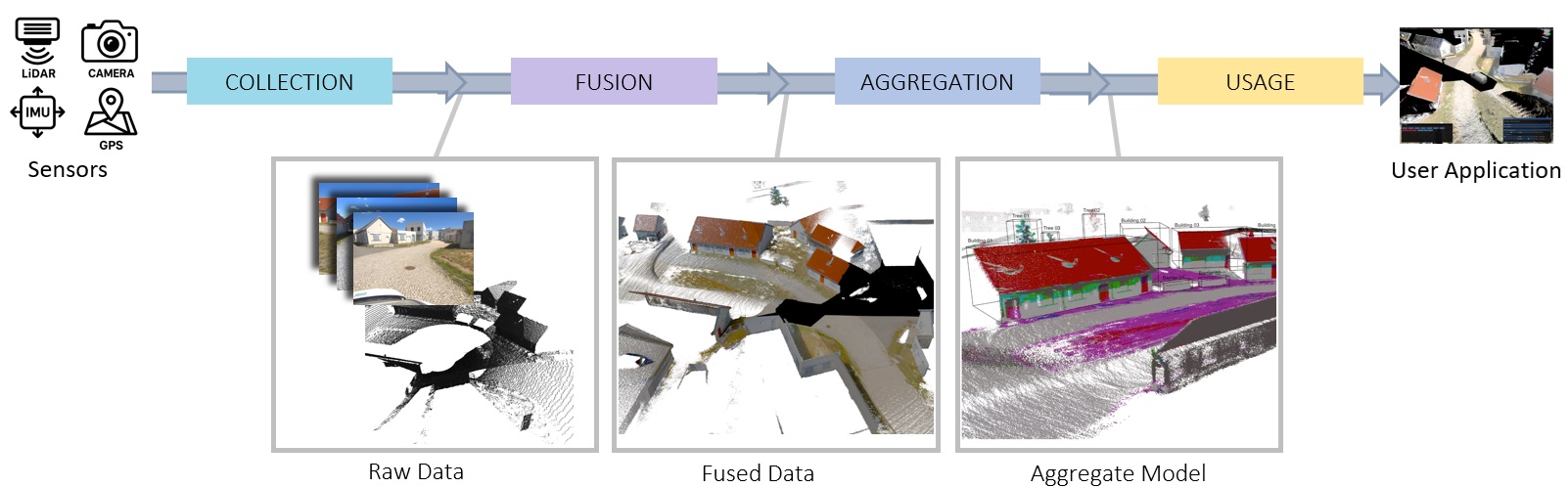
技术框架:论文提出了一种分层场景结构来管理混合表示。该结构包含以下主要模块:1) 传统网格模型:用于表示场景的基本几何结构。2) 3DGS模块:用于增强网格模型的视觉细节,生成高质量的渲染图像。3) 分层场景管理模块:用于组织和管理场景中的各个对象,提高系统的可扩展性和性能。整体流程是首先构建场景的传统网格模型,然后使用3DGS对网格模型进行渲染,最后通过分层场景管理模块对场景进行组织和管理。
关键创新:论文的关键创新在于提出了一种混合表示方法,将传统几何模型和神经渲染技术相结合,从而兼顾了几何精度和视觉逼真度。这种混合表示方法能够更好地满足国防应用的需求,例如,可以用于构建高精度的三维地图,并在此基础上进行视线分析、物理模拟和目标识别等任务。
关键设计:论文的关键设计包括:1) 选择3DGS作为神经渲染模块,因为它具有渲染速度快、效果好的优点。2) 设计了一种分层场景管理模块,可以有效地组织和管理场景中的各个对象,提高系统的可扩展性和性能。3) 针对国防应用的特点,对3DGS的参数进行了优化,例如,调整了高斯分布的方差,以提高渲染图像的清晰度。
🖼️ 关键图片


📊 实验亮点
论文通过对比实验验证了混合表示方法的有效性。实验结果表明,该方法在保证几何精度的前提下,能够显著提高渲染图像的视觉质量。与传统方法相比,混合表示方法在视觉逼真度方面有显著提升。虽然论文中没有给出具体的性能数据,但强调了该方法在几何精度和视觉逼真度之间取得了良好的平衡。
🎯 应用场景
该研究成果可广泛应用于国防和安全领域,例如构建高精度三维地图、进行视线分析、物理模拟、目标识别和态势感知。混合表示方法能够提供更全面、更准确的场景信息,帮助决策者更好地理解战场环境,从而做出更明智的决策。此外,该方法还可以应用于城市规划、自动驾驶等领域。
📄 摘要(原文)
Geospatial sensor data is essential for modern defense and security, offering indispensable 3D information for situational awareness. This data, gathered from sources like lidar sensors and optical cameras, allows for the creation of detailed models of operational environments. In this paper, we provide a comparative analysis of traditional representation methods, such as point clouds, voxel grids, and triangle meshes, alongside modern neural and implicit techniques like Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting (3DGS). Our evaluation reveals a fundamental trade-off: traditional models offer robust geometric accuracy ideal for functional tasks like line-of-sight analysis and physics simulations, while modern methods excel at producing high-fidelity, photorealistic visuals but often lack geometric reliability. Based on these findings, we conclude that a hybrid approach is the most promising path forward. We propose a system architecture that combines a traditional mesh scaffold for geometric integrity with a neural representation like 3DGS for visual detail, managed within a hierarchical scene structure to ensure scalability and performance.