Detail Enhanced Gaussian Splatting for Large-Scale Volumetric Capture
作者: Julien Philip, Li Ma, Pascal Clausen, Wenqi Xian, Ahmet Levent Taşel, Mingming He, Xueming Yu, David M. George, Ning Yu, Oliver Pilarski, Paul Debevec
分类: cs.GR
发布日期: 2025-10-31
备注: 10 pages, Accepted as a Journal paper at Siggraph Asia 2025. Webpage: https://eyeline-labs.github.io/DEGS/
DOI: 10.1145/3763336
💡 一句话要点
提出基于高斯溅射和扩散增强的细节增强方法,用于大规模体绘制。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 体绘制 高斯溅射 扩散模型 细节增强 自由视点视频
📋 核心要点
- 现有大规模体绘制方法难以同时兼顾可扩展性和高分辨率细节,尤其是在面部特写等场景下。
- 利用动态高斯溅射重建场景,并结合扩散模型,使用高保真面部数据进行微调,增强细节。
- 实验结果表明,该方法能够有效提升大规模体绘制的细节质量,满足电影和媒体制作的需求。
📝 摘要(中文)
本文提出了一种独特的大规模、多表演者、高分辨率4D体绘制系统,能够提供逼真的自由视点视频,包括高达4K分辨率的面部特写。该系统基于动态高斯溅射和基于扩散的细节增强,专为高端媒体制作的需求而设计。系统采用两个捕捉装置:场景装置,用于捕捉多演员表演,但分辨率低于4K制作质量;面部装置,用于记录高保真单演员面部细节,作为细节增强的参考。首先,使用4D高斯溅射从场景装置重建动态表演,并结合新的模型设计和训练策略来提高重建、动态范围和渲染质量。然后,为了渲染高质量的面部特写图像,引入了一种基于扩散的细节增强模型,该模型使用来自面部装置的相同演员的高保真数据进行微调。该模型在从低质量和高质量高斯溅射模型生成的配对数据上进行训练,使用低质量输入来匹配场景装置的质量,并使用高质量高斯溅射作为ground truth。结果表明,该流程有效地弥合了大规模装置的可扩展性能捕捉与电影和媒体制作所需的高分辨率标准之间的差距。
🔬 方法详解
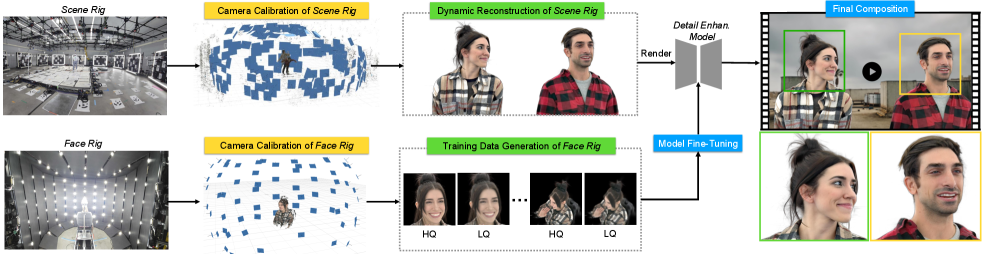
问题定义:论文旨在解决大规模体绘制中,如何在保证可扩展性的前提下,提升渲染细节,特别是面部特写等高分辨率需求场景下的细节不足问题。现有方法通常难以同时满足大规模场景和高分辨率细节的要求,导致渲染质量受限。
核心思路:论文的核心思路是利用高斯溅射(Gaussian Splatting)进行高效的场景重建和渲染,并在此基础上,通过一个基于扩散模型的细节增强模块,从高保真数据中学习并恢复细节信息。这种方法将高效的场景表示与强大的细节生成能力相结合,从而在保证渲染效率的同时,提升渲染质量。
技术框架:整个技术框架包含以下几个主要阶段:1) 使用场景装置(Scene Rig)捕捉多演员的动态表演,并使用4D高斯溅射进行重建。2) 使用面部装置(Face Rig)捕捉单演员的高保真面部细节数据,作为细节增强的参考。3) 训练一个基于扩散模型的细节增强模块,该模块以低质量的高斯溅射渲染结果作为输入,以高质量的高斯溅射渲染结果作为ground truth。4) 在渲染时,首先使用高斯溅射渲染场景,然后使用细节增强模块提升面部等关键区域的细节质量。
关键创新:论文的关键创新在于将高斯溅射与扩散模型相结合,用于大规模体绘制的细节增强。高斯溅射提供了一种高效的场景表示和渲染方法,而扩散模型则能够从高保真数据中学习并生成逼真的细节。这种结合克服了传统方法在可扩展性和细节质量之间的trade-off。
关键设计:在训练细节增强模型时,论文使用了配对数据,即低质量的高斯溅射渲染结果和对应的高质量高斯溅射渲染结果。低质量输入模拟了场景装置的质量,高质量结果则作为ground truth。损失函数的设计旨在使扩散模型能够从低质量输入中恢复出高质量的细节信息。此外,论文还针对高斯溅射模型设计了新的模型结构和训练策略,以提升重建、动态范围和渲染质量。
🖼️ 关键图片


📊 实验亮点
论文通过实验验证了该方法的有效性,能够显著提升大规模体绘制的细节质量,尤其是在面部特写等关键区域。该方法能够生成高达4K分辨率的逼真自由视点视频,满足电影和媒体制作的高分辨率需求。实验结果表明,该方法能够有效地弥合大规模装置的可扩展性能捕捉与高分辨率标准之间的差距。
🎯 应用场景
该研究成果可应用于电影制作、游戏开发、虚拟现实、增强现实等领域。通过该技术,可以实现对大规模动态场景的高质量自由视点渲染,为用户提供更加逼真和沉浸式的体验。未来,该技术有望进一步扩展到其他领域,如远程会议、数字人等。
📄 摘要(原文)
We present a unique system for large-scale, multi-performer, high resolution 4D volumetric capture providing realistic free-viewpoint video up to and including 4K resolution facial closeups. To achieve this, we employ a novel volumetric capture, reconstruction and rendering pipeline based on Dynamic Gaussian Splatting and Diffusion-based Detail Enhancement. We design our pipeline specifically to meet the demands of high-end media production. We employ two capture rigs: the Scene Rig, which captures multi-actor performances at a resolution which falls short of 4K production quality, and the Face Rig, which records high-fidelity single-actor facial detail to serve as a reference for detail enhancement. We first reconstruct dynamic performances from the Scene Rig using 4D Gaussian Splatting, incorporating new model designs and training strategies to improve reconstruction, dynamic range, and rendering quality. Then to render high-quality images for facial closeups, we introduce a diffusion-based detail enhancement model. This model is fine-tuned with high-fidelity data from the same actors recorded in the Face Rig. We train on paired data generated from low- and high-quality Gaussian Splatting (GS) models, using the low-quality input to match the quality of the Scene Rig, with the high-quality GS as ground truth. Our results demonstrate the effectiveness of this pipeline in bridging the gap between the scalable performance capture of a large-scale rig and the high-resolution standards required for film and media production.