LGCC: Enhancing Flow Matching Based Text-Guided Image Editing with Local Gaussian Coupling and Context Consistency
作者: Fangbing Liu, Pengfei Duan, Wen Li, Yi He
分类: cs.GR, cs.AI, cs.LG
发布日期: 2025-10-29
💡 一句话要点
LGCC:通过局部高斯耦合与上下文一致性增强Flow Matching文本引导图像编辑
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本引导图像编辑 Flow Matching 局部高斯耦合 内容一致性 多模态大语言模型
📋 核心要点
- 现有基于Flow Matching的图像编辑方法,如BAGEL,存在细节退化和内容不一致等问题,限制了编辑质量。
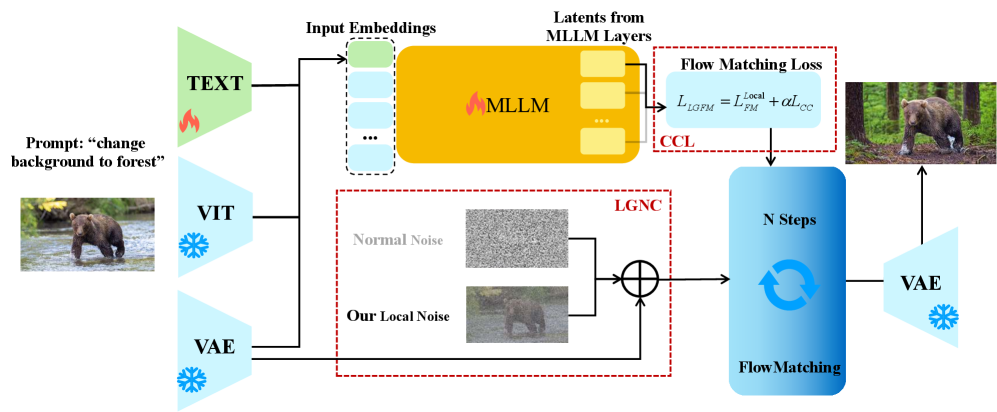
- LGCC框架通过局部高斯噪声耦合(LGNC)保留空间细节,并利用内容一致性损失(CCL)确保编辑指令与图像修改的语义对齐。
- 实验结果表明,LGCC显著提升了编辑质量和推理速度,在I2EBench上取得了更好的局部细节得分和整体得分。
📝 摘要(中文)
本文提出了一种名为LGCC的新框架,旨在提升基于Flow Matching的多模态大语言模型(MLLM)在图像编辑方面的性能。现有方法(如BAGEL)存在细节退化、内容不一致和效率低下的问题,主要原因是它们依赖于随机噪声初始化。LGCC包含两个关键组件:局部高斯噪声耦合(LGNC)和内容一致性损失(CCL)。LGNC通过将目标图像嵌入及其局部扰动对应项建模为耦合对来保留空间细节,而CCL确保编辑指令和图像修改之间的语义对齐,防止意外的内容移除。通过课程学习将LGCC与BAGEL预训练模型集成,显著减少了推理步骤,在I2EBench上局部细节得分提高了1.60%,总体得分提高了0.53%。LGCC在轻量级编辑中实现了3到5倍的加速,在通用编辑中实现了2倍的加速,仅需BAGEL或Flux 40%到50%的推理时间。这些结果表明LGCC能够保留细节、保持上下文完整性并提高推理速度,提供了一种经济高效的解决方案,且不影响编辑质量。
🔬 方法详解
问题定义:现有基于Flow Matching的文本引导图像编辑方法,例如BAGEL,依赖随机噪声初始化,导致图像编辑过程中容易出现细节丢失、内容不一致等问题。这些问题严重影响了编辑后的图像质量和用户体验。现有方法在效率方面也存在不足,推理时间较长,限制了其在实际应用中的部署。
核心思路:LGCC的核心思路是通过引入局部高斯噪声耦合(LGNC)来更好地保留图像的局部细节,并利用内容一致性损失(CCL)来保证编辑前后图像内容的语义一致性。LGNC将原始图像及其局部扰动版本视为耦合对,从而在训练过程中学习到更鲁棒的特征表示。CCL则通过约束编辑前后图像的特征相似性,防止不必要的图像内容移除。
技术框架:LGCC框架主要包含两个核心模块:局部高斯噪声耦合(LGNC)和内容一致性损失(CCL)。首先,LGNC模块对输入图像进行局部高斯噪声扰动,生成图像的扰动版本。然后,原始图像和扰动图像被送入Flow Matching模型进行训练。同时,CCL模块计算编辑前后图像的特征表示,并施加一致性约束。整个框架通过课程学习的方式与预训练的BAGEL模型集成,逐步提升编辑质量和效率。
关键创新:LGCC的关键创新在于提出了局部高斯噪声耦合(LGNC)和内容一致性损失(CCL)这两个模块。LGNC通过对图像进行局部扰动,增强了模型的鲁棒性,使其能够更好地保留图像的细节信息。CCL则通过约束编辑前后图像的语义一致性,有效防止了内容丢失的问题。此外,LGCC还采用了课程学习的方式,逐步提升模型的性能。
关键设计:LGNC模块的关键设计在于局部高斯噪声的扰动方式,需要仔细调整噪声的强度和范围,以保证既能增强模型的鲁棒性,又不会过度破坏图像的结构信息。CCL模块的关键设计在于特征提取器的选择和一致性损失的计算方式。论文中使用了预训练的CLIP模型来提取图像特征,并采用余弦相似度作为一致性损失的度量标准。此外,课程学习的训练策略也需要仔细设计,以保证模型能够逐步学习到高质量的编辑能力。
🖼️ 关键图片


📊 实验亮点
LGCC通过与BAGEL预训练模型集成,显著提升了图像编辑的性能。在I2EBench数据集上,LGCC的局部细节得分提高了1.60%,总体得分提高了0.53%。同时,LGCC在轻量级编辑中实现了3到5倍的加速,在通用编辑中实现了2倍的加速,仅需BAGEL或Flux 40%到50%的推理时间。这些结果表明LGCC在保证编辑质量的同时,显著提升了编辑效率。
🎯 应用场景
LGCC在图像编辑领域具有广泛的应用前景,例如照片修复、艺术创作、产品设计等。它可以用于快速、高质量地编辑图像,满足用户个性化的需求。该研究的实际价值在于提升了图像编辑的效率和质量,降低了编辑成本。未来,LGCC可以进一步扩展到视频编辑领域,为用户提供更加便捷、强大的编辑工具。
📄 摘要(原文)
Recent advancements have demonstrated the great potential of flow matching-based Multimodal Large Language Models (MLLMs) in image editing. However, state-of-the-art works like BAGEL face limitations, including detail degradation, content inconsistency, and inefficiency due to their reliance on random noise initialization. To address these issues, we propose LGCC, a novel framework with two key components: Local Gaussian Noise Coupling (LGNC) and Content Consistency Loss (CCL). LGNC preserves spatial details by modeling target image embeddings and their locally perturbed counterparts as coupled pairs, while CCL ensures semantic alignment between edit instructions and image modifications, preventing unintended content removal. By integrating LGCC with the BAGEL pre-trained model via curriculum learning, we significantly reduce inference steps, improving local detail scores on I2EBench by 1.60% and overall scores by 0.53%. LGCC achieves 3x -- 5x speedup for lightweight editing and 2x for universal editing, requiring only 40% -- 50% of the inference time of BAGEL or Flux. These results demonstrate LGCC's ability to preserve detail, maintain contextual integrity, and enhance inference speed, offering a cost-efficient solution without compromising editing quality.