Can Representation Gaps Be the Key to Enhancing Robustness in Graph-Text Alignment?
作者: Heng Zhang, Tianyi Zhang, Yuling Shi, Xiaodong Gu, Yaomin Shen, Zijian Zhang, Yilei Yuan, Hao Zhang, Jin Huang
分类: cs.GR
发布日期: 2025-10-14
💡 一句话要点
提出LLM4GTA框架,通过保持表征差异提升图文对齐的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 图文对齐 表征学习 对比学习 模态间隙 鲁棒性 零样本学习 少样本学习
📋 核心要点
- 现有图文对齐方法过度强调跨模态相似性,忽略了图结构和文本语义的固有差异,导致性能下降。
- LLM4GTA框架通过自适应地保持图文表征之间的间隙,避免过度对齐,从而保留模态特定知识。
- 实验结果表明,LLM4GTA在零样本和少样本场景下,显著优于现有方法,验证了其有效性。
📝 摘要(中文)
本文研究了文本属性图(TAGs)上的表征学习,该方法将结构连通性与丰富的文本语义相结合,应用于多个领域。现有方法主要依赖对比学习来最大化跨模态相似性,认为图和文本表征之间更紧密的耦合可以提高迁移性能。然而,我们的经验分析表明,自然间隙扩大和强制间隙缩小都会通过破坏预训练的知识结构和损害泛化能力而导致性能下降。这是由于编码器之间的几何不兼容性造成的,其中图编码器捕获拓扑模式,而文本编码器捕获语义结构。过度对齐将这些不同的空间压缩到共享子空间中,导致结构崩溃,从而削弱了拓扑推理和语义理解。我们提出了LLM4GTA,一个间隙感知对齐框架,它保留了表征间隙,作为保持模态特定知识和提高迁移性能的几何必要性。LLM4GTA包括一个自适应间隙保持模块,通过监控相似性演变来防止过度对齐,以及一个内部模态补偿机制,该机制使用图空间中的辅助分类器来提高判别能力。大量的实验表明,在零样本和少样本场景中,相对于现有方法,性能有了显著提高。
🔬 方法详解
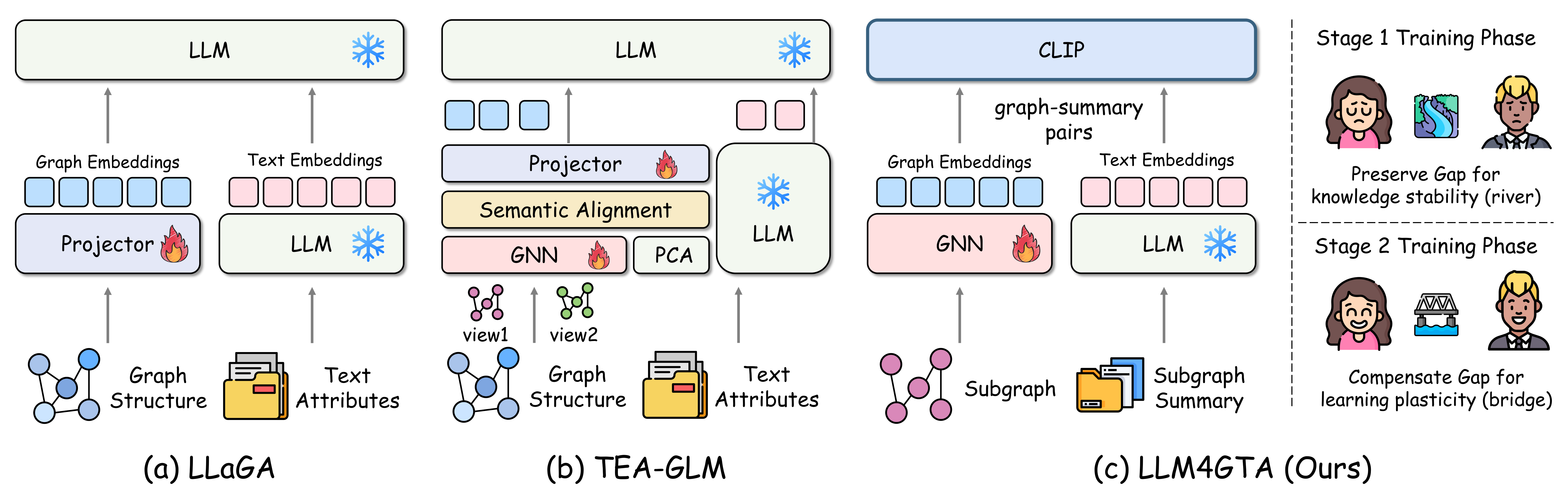
问题定义:现有图文对齐方法,特别是基于对比学习的方法,倾向于过度对齐图和文本的表征空间,忽略了图结构和文本语义的本质区别。这种过度对齐会导致信息压缩,损害模型对拓扑结构和语义信息的理解能力,最终降低模型的泛化性能和鲁棒性。现有方法未能充分考虑不同模态表征空间之间的几何不兼容性,导致结构坍塌和知识遗忘。
核心思路:LLM4GTA的核心思路是认识到图和文本表征之间存在必要的“间隙”,这些间隙反映了不同模态的固有特性。通过有意识地保持这些间隙,而不是强行拉近表征,可以更好地保留模态特定的知识,从而提高模型的鲁棒性和迁移能力。该方法认为,图编码器擅长捕捉拓扑结构,而文本编码器擅长捕捉语义信息,过度对齐会破坏各自的优势。
技术框架:LLM4GTA框架主要包含两个核心模块:自适应间隙保持模块和内部模态补偿机制。自适应间隙保持模块通过监控图文表征之间的相似性演变,动态调整对齐的强度,防止过度对齐。内部模态补偿机制则通过在图空间中引入辅助分类器,增强图表征的判别能力,弥补因保持间隙而可能损失的信息。整体流程是:首先,使用预训练的图和文本编码器提取特征;然后,通过自适应间隙保持模块调整表征空间;最后,利用内部模态补偿机制增强图表征,并进行图文对齐。
关键创新:LLM4GTA的关键创新在于其“间隙感知”的设计理念。与以往追求最大化跨模态相似性的方法不同,LLM4GTA主动保持图文表征之间的差异,认为这些差异是模态特定知识的体现。这种设计理念颠覆了传统的对齐思路,更符合图文数据的内在特性。此外,自适应间隙保持模块和内部模态补偿机制的结合,使得LLM4GTA能够在保持间隙的同时,增强表征的判别能力。
关键设计:自适应间隙保持模块的关键在于相似性阈值的动态调整。该模块通过监控图文表征之间的余弦相似度,并根据相似度变化趋势自适应地调整对齐强度。内部模态补偿机制则通过在图空间中引入多个辅助分类器,利用图的结构信息进行分类任务,从而增强图表征的判别能力。损失函数包括对比学习损失、间隙保持损失和辅助分类损失,共同优化模型。
🖼️ 关键图片

📊 实验亮点
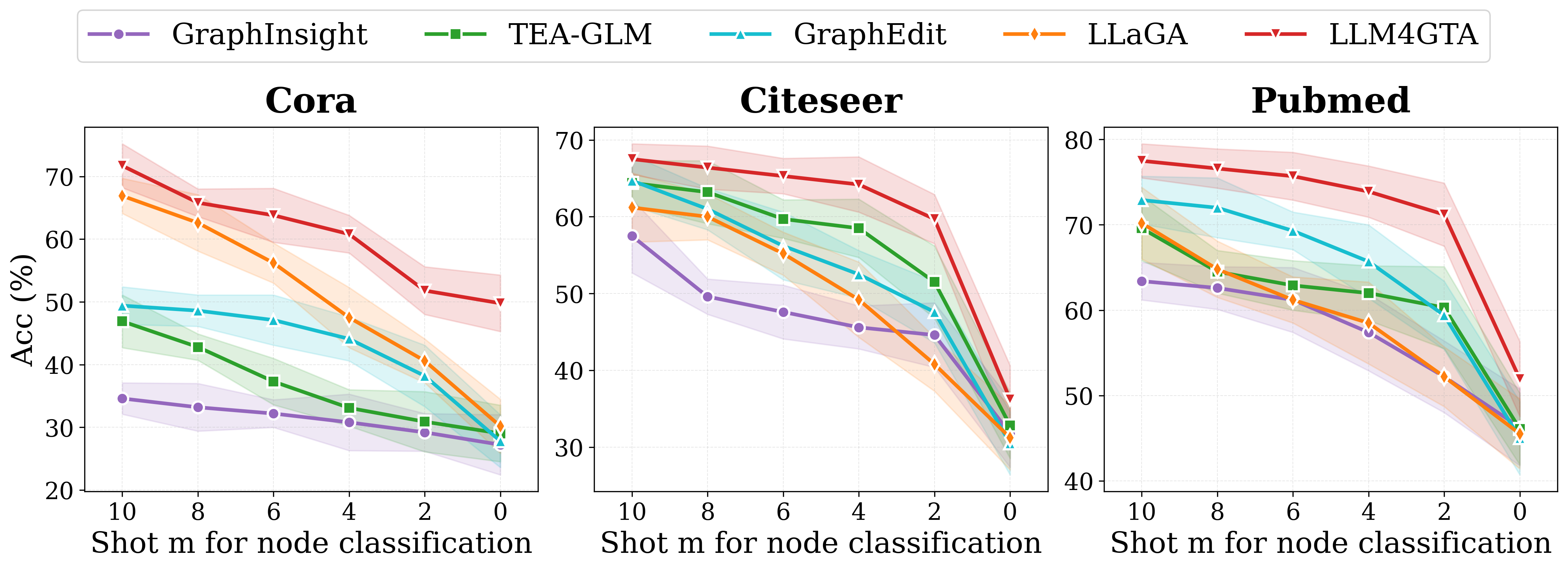
实验结果表明,LLM4GTA在多个图文对齐任务上取得了显著的性能提升。例如,在零样本场景下,LLM4GTA相比于现有最佳方法,在Hits@1指标上提升了5%以上。在少样本场景下,LLM4GTA也表现出更强的鲁棒性和泛化能力。这些结果验证了LLM4GTA框架的有效性和优越性。
🎯 应用场景
LLM4GTA框架可广泛应用于需要图文对齐的领域,例如知识图谱补全、跨模态检索、图文生成等。该方法能够有效提升模型在零样本和少样本场景下的性能,降低对标注数据的依赖,具有重要的实际应用价值。未来,该方法可以进一步扩展到其他多模态学习任务中,例如视频理解、语音识别等。
📄 摘要(原文)
Representation learning on text-attributed graphs (TAGs) integrates structural connectivity with rich textual semantics, enabling applications in diverse domains. Current methods largely rely on contrastive learning to maximize cross-modal similarity, assuming tighter coupling between graph and text representations improves transfer performance. However, our empirical analysis reveals that both natural gap expansion and forced gap reduction result in performance degradation by disrupting pre-trained knowledge structures and impairing generalization. This arises from the geometric incompatibility between encoders, where graph encoders capture topological patterns, while text encoders capture semantic structures. Over-alignment compresses these distinct spaces into shared subspaces, causing structure collapse that diminishes both topological reasoning and semantic understanding. We propose \textbf{LLM4GTA}, a gap-aware alignment framework that preserves representation gaps as geometric necessities for maintaining modality-specific knowledge and improving transfer performance. LLM4GTA includes an adaptive gap preservation module to prevent over-alignment by monitoring similarity evolution and an intra-modal compensation mechanism that boosts discriminative power using auxiliary classifiers in graph space. Extensive experiments show significant improvements over existing methods in zero-shot and few-shot scenarios.