Pulp Motion: Framing-aware multimodal camera and human motion generation
作者: Robin Courant, Xi Wang, David Loiseaux, Marc Christie, Vicky Kalogeiton
分类: cs.GR, cs.CV
发布日期: 2025-10-06
备注: Project page: https://www.lix.polytechnique.fr/vista/projects/2025_pulpmotion_courant/
💡 一句话要点
提出Pulp Motion框架,实现文本驱动下保持屏幕构图一致的人体运动和相机轨迹联合生成。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人体运动生成 相机轨迹生成 多模态生成 屏幕构图 文本条件生成
📋 核心要点
- 现有方法分别生成人体运动和相机轨迹,忽略了电影摄影中演员表演和相机运动在屏幕空间中的紧密联系。
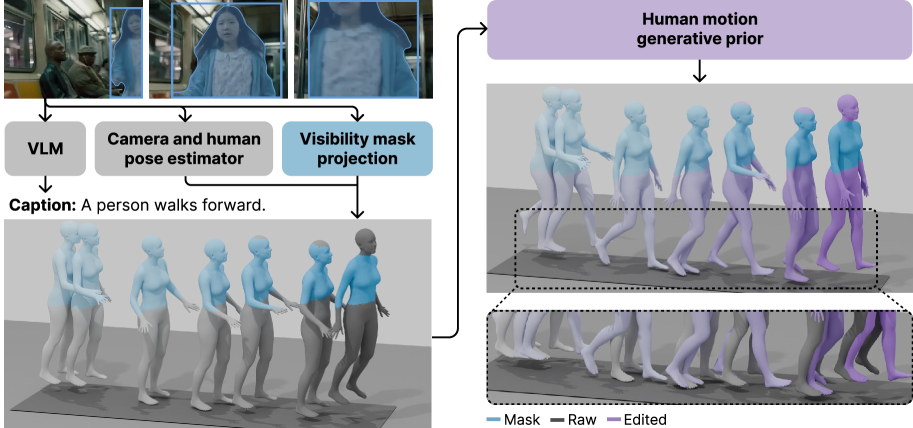
- 提出PulpMotion框架,通过屏幕构图这一辅助模态,在文本驱动下联合生成人体运动和相机轨迹,保证屏幕构图的一致性。
- 实验表明,该方法在生成帧内一致的人体-相机运动方面有效,并在文本对齐方面有所提升,生成更符合电影摄影意义的构图。
📝 摘要(中文)
本文首次将人体运动和相机轨迹的生成任务视为一个文本条件下的联合生成问题,旨在保持屏幕空间中演员表演和相机运动之间的紧密联系。我们提出了一个简单的、模型无关的框架,通过一个辅助模态——将人体关节投影到相机上产生的屏幕构图——来增强多模态一致性。这种屏幕构图为模态之间提供了一个自然有效的桥梁,促进了一致性,并产生更精确的联合分布。我们首先设计了一个联合自编码器,学习一个共享的潜在空间,以及从人体和相机潜在变量到构图潜在变量的轻量级线性变换。然后,我们引入辅助采样,利用这种线性变换来引导生成过程朝着一致的构图模态发展。为了支持这项任务,我们还引入了PulpMotion数据集,一个包含丰富字幕和高质量人体运动的人体运动和相机轨迹数据集。在基于DiT和MAR的架构上进行的大量实验表明,我们的方法在生成帧内一致的人体-相机运动方面具有通用性和有效性,同时在两种模态的文本对齐方面也取得了收益。我们的定性结果产生了更有电影意义的构图,为这项任务设定了新的技术水平。代码、模型和数据可在我们的项目页面中找到。
🔬 方法详解
问题定义:现有方法分别生成人体运动和相机轨迹,忽略了电影摄影中演员表演和相机运动在屏幕空间中的紧密联系。这导致生成的运动和轨迹在屏幕构图上不协调,缺乏电影感。因此,需要一种能够联合生成人体运动和相机轨迹,并保证屏幕构图一致性的方法。
核心思路:论文的核心思路是通过引入屏幕构图作为辅助模态,建立人体运动和相机轨迹之间的桥梁。屏幕构图反映了人体关节在相机视角下的位置关系,能够有效地衡量两者的一致性。通过学习人体运动、相机轨迹和屏幕构图的联合分布,可以引导生成过程朝着一致的构图方向发展。
技术框架:PulpMotion框架包含以下主要模块:1) 联合自编码器:学习人体运动、相机轨迹和屏幕构图的共享潜在空间。2) 线性变换:建立人体运动和相机轨迹的潜在变量到屏幕构图潜在变量的映射关系。3) 辅助采样:利用线性变换引导生成过程,使生成的运动和轨迹具有一致的屏幕构图。整体流程是:首先,使用文本描述作为条件,生成人体运动和相机轨迹的潜在变量;然后,通过线性变换预测屏幕构图的潜在变量;最后,利用辅助采样,根据预测的屏幕构图潜在变量,调整人体运动和相机轨迹的潜在变量,从而生成具有一致构图的运动和轨迹。
关键创新:最重要的技术创新点是引入了屏幕构图作为辅助模态,并利用线性变换建立人体运动和相机轨迹之间的联系。与现有方法相比,PulpMotion框架能够显式地建模屏幕构图,并将其作为生成过程的约束条件,从而保证生成结果的构图一致性。
关键设计:1) 联合自编码器:使用变分自编码器(VAE)学习共享潜在空间,采用KL散度损失约束潜在变量的分布。2) 线性变换:使用线性层将人体运动和相机轨迹的潜在变量映射到屏幕构图的潜在变量,采用均方误差损失训练线性变换。3) 辅助采样:使用Metropolis-Hastings算法,根据预测的屏幕构图潜在变量,对人体运动和相机轨迹的潜在变量进行采样,从而引导生成过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,PulpMotion框架在生成帧内一致的人体-相机运动方面具有通用性和有效性。在DiT和MAR架构上,该方法不仅能够生成更符合电影摄影意义的构图,还在两种模态的文本对齐方面取得了收益。定性结果也表明,PulpMotion能够生成更具电影感的场景。
🎯 应用场景
该研究成果可应用于电影制作、游戏开发、虚拟现实等领域。例如,可以根据剧本自动生成演员的运动和相机的运动轨迹,提高制作效率和质量。此外,还可以用于虚拟角色的动画生成,使其运动更加自然和符合电影摄影的规律。该研究有助于推动人工智能在内容创作领域的应用。
📄 摘要(原文)
Treating human motion and camera trajectory generation separately overlooks a core principle of cinematography: the tight interplay between actor performance and camera work in the screen space. In this paper, we are the first to cast this task as a text-conditioned joint generation, aiming to maintain consistent on-screen framing while producing two heterogeneous, yet intrinsically linked, modalities: human motion and camera trajectories. We propose a simple, model-agnostic framework that enforces multimodal coherence via an auxiliary modality: the on-screen framing induced by projecting human joints onto the camera. This on-screen framing provides a natural and effective bridge between modalities, promoting consistency and leading to more precise joint distribution. We first design a joint autoencoder that learns a shared latent space, together with a lightweight linear transform from the human and camera latents to a framing latent. We then introduce auxiliary sampling, which exploits this linear transform to steer generation toward a coherent framing modality. To support this task, we also introduce the PulpMotion dataset, a human-motion and camera-trajectory dataset with rich captions, and high-quality human motions. Extensive experiments across DiT- and MAR-based architectures show the generality and effectiveness of our method in generating on-frame coherent human-camera motions, while also achieving gains on textual alignment for both modalities. Our qualitative results yield more cinematographically meaningful framings setting the new state of the art for this task. Code, models and data are available in our \href{https://www.lix.polytechnique.fr/vista/projects/2025_pulpmotion_courant/}{project page}.