MPMAvatar: Learning 3D Gaussian Avatars with Accurate and Robust Physics-Based Dynamics
作者: Changmin Lee, Jihyun Lee, Tae-Kyun Kim
分类: cs.GR, cs.CV
发布日期: 2025-10-02
备注: Accepted to NeurIPS 2025
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MPMAvatar:提出基于物理的精确鲁棒3D高斯Avatar学习框架
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱四:生成式动作 (Generative Motion)
关键词: 3D人体Avatar 物理动力学模拟 Material Point Method 高斯溅射渲染 服装建模 虚拟现实 动画生成
📋 核心要点
- 现有方法在模拟具有宽松服装的人体动力学方面存在精度和鲁棒性不足的挑战。
- MPMAvatar利用Material Point Method模拟器,结合各向异性模型和碰撞处理,实现精确的服装动力学。
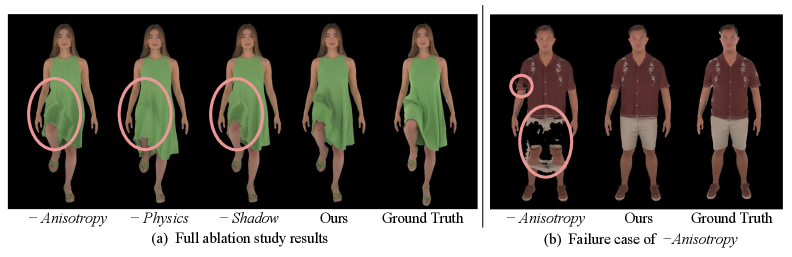
- 实验表明,MPMAvatar在动力学和渲染精度、鲁棒性及效率上优于现有技术,并能零样本泛化到新交互。
📝 摘要(中文)
本文提出MPMAvatar,一个从多视角视频创建3D人体Avatar的框架,它支持高度真实、鲁棒的动画,以及自由视角的照片级渲染。为了实现精确和鲁棒的动力学建模,核心思想是使用基于Material Point Method(MPM)的模拟器,通过结合各向异性本构模型和新颖的碰撞处理算法,精心定制该模拟器以模拟具有复杂形变和与底层身体接触的服装。该动力学建模方案与使用具有准阴影的3D高斯溅射渲染的规范Avatar相结合,从而为物理上真实的动画实现高保真渲染。实验表明,MPMAvatar在动力学建模精度、渲染精度以及鲁棒性和效率方面显著优于现有的最先进的基于物理的Avatar。此外,本文还展示了一个新颖的应用,其中Avatar能够以零样本方式泛化到未见过的交互,这对于以前基于学习的方法来说是无法实现的,因为它们的模拟泛化能力有限。
🔬 方法详解
问题定义:现有3D人体Avatar创建方法在模拟宽松服装的物理动力学时,精度和鲁棒性不足,难以应对复杂形变和身体接触,泛化能力有限。
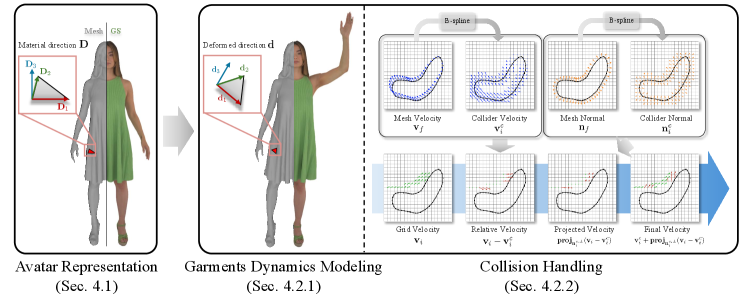
核心思路:利用Material Point Method (MPM) 模拟器,该方法擅长处理复杂形变和接触问题。通过定制MPM模拟器,并结合各向异性本构模型和新颖的碰撞处理算法,提升服装动力学模拟的精度和鲁棒性。同时,结合3D高斯溅射渲染技术,实现高保真渲染。
技术框架:MPMAvatar框架包含以下主要模块:1) 多视角视频输入;2) 基于MPM的服装动力学模拟,包括各向异性本构模型和碰撞处理;3) 规范Avatar建模,使用3D高斯溅射进行渲染;4) 动力学模拟和渲染的集成,实现物理上真实的动画效果。
关键创新:1) 将Material Point Method引入3D人体Avatar的服装动力学模拟,提升了复杂形变和接触问题的处理能力;2) 提出了各向异性本构模型和新颖的碰撞处理算法,进一步提高了动力学模拟的精度和鲁棒性;3) 结合3D高斯溅射渲染,实现了高保真度的渲染效果。
关键设计:1) MPM模拟器的参数设置,例如网格分辨率、时间步长等,需要根据具体服装的复杂程度进行调整;2) 各向异性本构模型的参数选择,需要根据服装材料的特性进行优化;3) 碰撞处理算法的设计,需要保证碰撞检测的准确性和碰撞响应的真实性;4) 3D高斯溅射渲染的参数设置,例如高斯分布的方差、颜色等,需要根据光照条件进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MPMAvatar在动力学建模精度、渲染精度以及鲁棒性和效率方面显著优于现有的最先进的基于物理的Avatar。此外,MPMAvatar能够以零样本方式泛化到未见过的交互,这对于以前基于学习的方法来说是无法实现的。具体性能数据和对比基线在论文中有详细展示。
🎯 应用场景
MPMAvatar可应用于虚拟现实、增强现实、游戏、电影制作等领域,用于创建逼真的人体Avatar,并模拟真实的服装动力学效果。该技术可用于虚拟试衣、角色动画、虚拟社交等应用场景,提升用户体验和互动性。未来,该技术有望应用于机器人控制、远程操作等领域,实现更自然的人机交互。
📄 摘要(原文)
While there has been significant progress in the field of 3D avatar creation from visual observations, modeling physically plausible dynamics of humans with loose garments remains a challenging problem. Although a few existing works address this problem by leveraging physical simulation, they suffer from limited accuracy or robustness to novel animation inputs. In this work, we present MPMAvatar, a framework for creating 3D human avatars from multi-view videos that supports highly realistic, robust animation, as well as photorealistic rendering from free viewpoints. For accurate and robust dynamics modeling, our key idea is to use a Material Point Method-based simulator, which we carefully tailor to model garments with complex deformations and contact with the underlying body by incorporating an anisotropic constitutive model and a novel collision handling algorithm. We combine this dynamics modeling scheme with our canonical avatar that can be rendered using 3D Gaussian Splatting with quasi-shadowing, enabling high-fidelity rendering for physically realistic animations. In our experiments, we demonstrate that MPMAvatar significantly outperforms the existing state-of-the-art physics-based avatar in terms of (1) dynamics modeling accuracy, (2) rendering accuracy, and (3) robustness and efficiency. Additionally, we present a novel application in which our avatar generalizes to unseen interactions in a zero-shot manner-which was not achievable with previous learning-based methods due to their limited simulation generalizability. Our project page is at: https://KAISTChangmin.github.io/MPMAvatar/