Audio Driven Real-Time Facial Animation for Social Telepresence
作者: Jiye Lee, Chenghui Li, Linh Tran, Shih-En Wei, Jason Saragih, Alexander Richard, Hanbyul Joo, Shaojie Bai
分类: cs.GR, cs.CV, cs.LG, cs.SD
发布日期: 2025-10-01 (更新: 2025-11-01)
备注: SIGGRAPH Asia 2025. Project page: https://jiyewise.github.io/projects/AudioRTA
💡 一句话要点
提出一种音频驱动的实时面部动画系统,用于社交远程呈现。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频驱动 面部动画 实时渲染 扩散模型 在线Transformer 蒸馏学习 社交VR
📋 核心要点
- 现有音频驱动面部动画方法难以兼顾真实感、实时性和低延迟,限制了其在社交VR中的应用。
- 提出一种基于扩散模型的实时面部动画框架,通过在线Transformer和蒸馏加速,显著降低延迟。
- 实验表明,该方法在面部动画准确性上超越现有技术,推理速度提升100-1000倍,并验证了其在VR中的可行性。
📝 摘要(中文)
本文提出了一种音频驱动的实时系统,用于为虚拟现实中的社交互动生成逼真的3D面部头像动画。该系统延迟极低,适用于任何人。核心是一个编码器模型,能够实时将音频信号转换为潜在的面部表情序列,然后解码为逼真的3D面部头像。利用扩散模型的生成能力,系统捕捉了自然交流所需的丰富面部表情,同时实现了实时性能(<15ms GPU时间)。通过在线Transformer(消除了对未来输入的依赖)和蒸馏流水线(将迭代去噪加速为单步),该架构最大限度地减少了延迟。此外,还解决了实时场景中逐帧处理连续音频信号并保持一致动画质量的关键设计挑战。该框架的多功能性扩展到多模态应用,包括情感条件等语义模态以及VR头显上的眼动相机等多模态传感器。实验结果表明,面部动画的准确性显著优于现有的离线最先进基线,推理速度提高了100到1000倍。通过实时VR演示和多语言语音等各种场景验证了该方法。
🔬 方法详解
问题定义:现有音频驱动的面部动画方法通常难以在真实感、实时性和低延迟之间取得平衡。离线方法虽然可以生成高质量的动画,但无法满足实时交互的需求。在线方法虽然速度较快,但往往牺牲了动画的真实性和丰富性。因此,需要一种能够实时生成逼真面部动画,且延迟足够低,以支持自然社交交互的系统。
核心思路:本文的核心思路是利用扩散模型的强大生成能力,并结合在线Transformer和蒸馏技术,实现实时且高质量的面部动画生成。扩散模型能够捕捉丰富的面部表情变化,而在线Transformer消除了对未来音频信息的依赖,蒸馏技术则加速了扩散模型的推理过程。
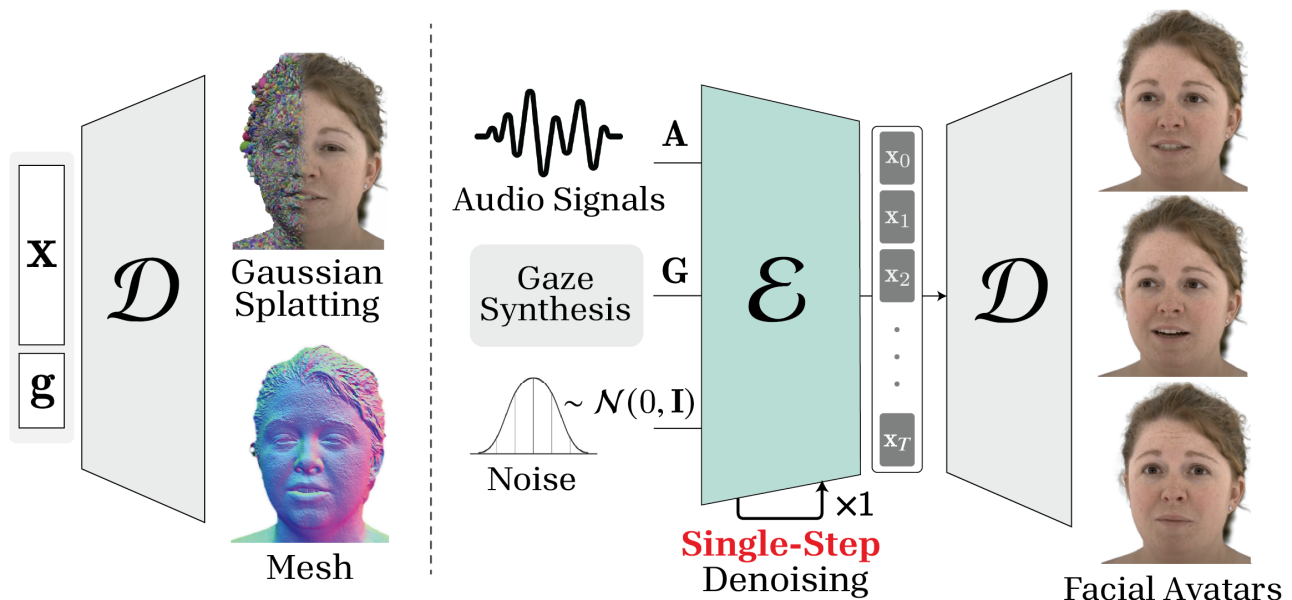
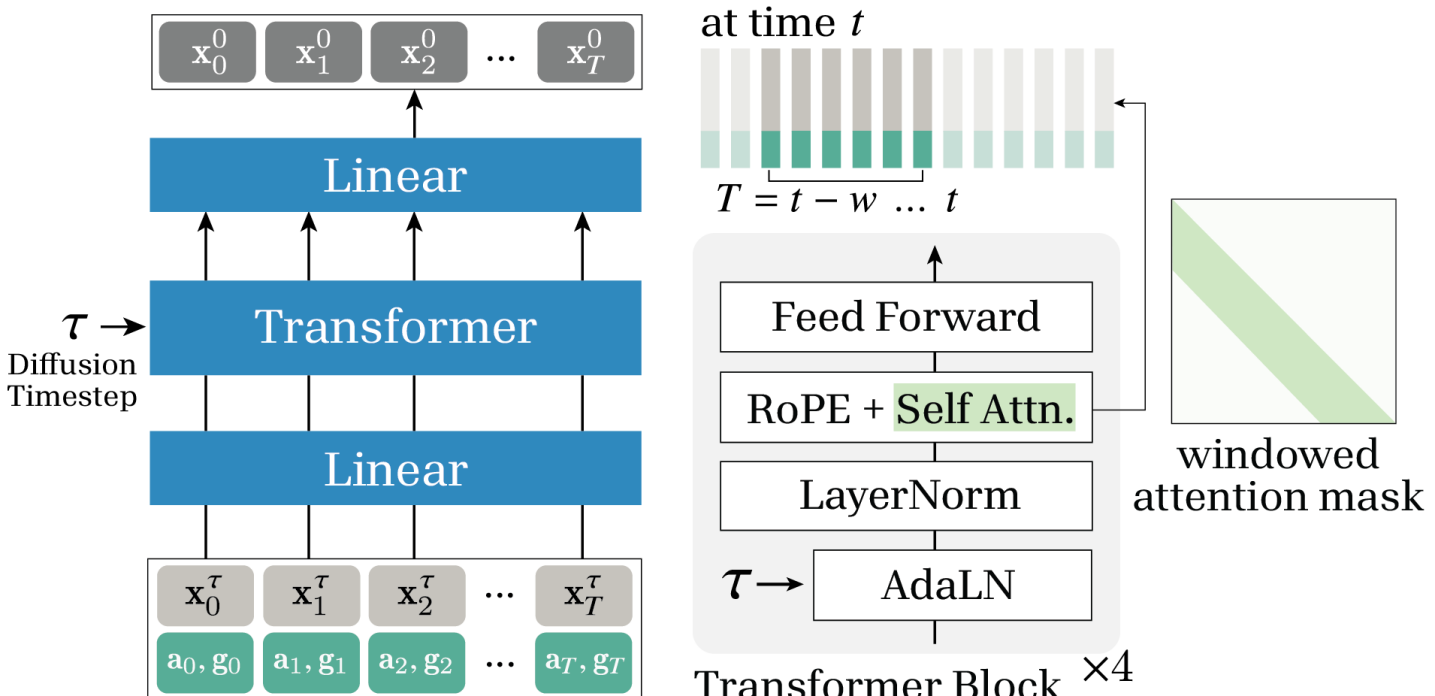
技术框架:该系统主要包含两个模块:编码器和解码器。编码器是一个在线Transformer,负责将输入的音频信号实时转换为潜在的面部表情序列。解码器则利用扩散模型,将潜在的面部表情序列解码为逼真的3D面部头像动画。整个流程是端到端的,可以进行优化以最小化延迟。
关键创新:该论文的关键创新在于以下几点:1) 使用在线Transformer,消除了对未来音频信息的依赖,实现了真正的实时处理。2) 采用蒸馏技术,将扩散模型的迭代去噪过程加速为单步,显著降低了推理时间。3) 针对实时场景下的连续音频信号处理,设计了相应的优化策略,保证了动画质量的连贯性。
关键设计:在线Transformer采用了因果注意力机制,确保只使用过去的音频信息进行预测。蒸馏过程通过最小化蒸馏后的模型与原始扩散模型输出之间的差异来实现。损失函数包括重建损失和对抗损失,用于保证动画的真实性和质量。具体参数设置和网络结构细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在面部动画准确性方面显著优于现有的离线最先进基线,并且推理速度提高了100到1000倍,实现了<15ms的GPU时间。通过实时VR演示和多语言语音等各种场景验证了该方法的可行性和有效性。
🎯 应用场景
该研究成果可广泛应用于社交VR、远程会议、虚拟主播等领域。通过实时面部动画,可以增强虚拟交互的真实感和沉浸感,提升用户体验。此外,该技术还可以应用于个性化头像定制、情感识别和表达等领域,具有广阔的应用前景。
📄 摘要(原文)
We present an audio-driven real-time system for animating photorealistic 3D facial avatars with minimal latency, designed for social interactions in virtual reality for anyone. Central to our approach is an encoder model that transforms audio signals into latent facial expression sequences in real time, which are then decoded as photorealistic 3D facial avatars. Leveraging the generative capabilities of diffusion models, we capture the rich spectrum of facial expressions necessary for natural communication while achieving real-time performance (<15ms GPU time). Our novel architecture minimizes latency through two key innovations: an online transformer that eliminates dependency on future inputs and a distillation pipeline that accelerates iterative denoising into a single step. We further address critical design challenges in live scenarios for processing continuous audio signals frame-by-frame while maintaining consistent animation quality. The versatility of our framework extends to multimodal applications, including semantic modalities such as emotion conditions and multimodal sensors with head-mounted eye cameras on VR headsets. Experimental results demonstrate significant improvements in facial animation accuracy over existing offline state-of-the-art baselines, achieving 100 to 1000 times faster inference speed. We validate our approach through live VR demonstrations and across various scenarios such as multilingual speeches.